前回は物体検知モデルの精度を評価する指標をまとめました。
今回は実際にYOLOv8でdetectした結果に対して、精度を計算してみようと思います。
自分で実装しても良いのですが、大変なのでまずはお手軽にYOLOv8のvalモードで精度を算出したいと思います。
YOLOv8のvalモードではCOCOの精度指標である101点補完APを計算しているようです。
# Integrate area under curve
method = 'interp' # methods: 'continuous', 'interp'
if method == 'interp':
x = np.linspace(0, 1, 101) # 101-point interp (COCO)
引用: https://github.com/ultralytics/ultralytics/blob/44c7c3514d87a5e05cfb14dba5a3eeb6eb860e70/ultralytics/yolo/utils/metrics.py#L403
物体検知用の画像の準備
今までは猫の画像を使っていましたが、犬派の人のために犬の画像を用意します 笑
(犬だけだと精度確認が分かりにくかったので、後からキリンの画像も2枚足しました)
最初はDALL-Eで作成していたのですが、納得のいく画像が作成できずフォトサイトからダウンロードすることにしました。
unsplash.comというサイトから「puppies」と「giraffe」いうキーワードで検索し、良さそうな画像をダウンロードしました。
わざと誤認識や未検知しそうな画像を数枚ピックアップしています。

下記URLから写真をダウンロード出来ますので、本記事と同じ結果を再現したい場合はぜひダウンロードしてください。
credits to all photo graphers uploading below photos at unsplash.com:
・https://unsplash.com/ja/%E5%86%99%E7%9C%9F/ECjHeJtRznQ
・https://unsplash.com/ja/%E5%86%99%E7%9C%9F/rfL-thiRzDs
・https://unsplash.com/ja/%E5%86%99%E7%9C%9F/fliwkBbS7oM
・https://unsplash.com/ja/%E5%86%99%E7%9C%9F/VDrErQEF9e4
・https://unsplash.com/ja/%E5%86%99%E7%9C%9F/UspYqrVBsIo
・https://unsplash.com/ja/%E5%86%99%E7%9C%9F/k34a6Yzt6A0
・https://unsplash.com/ja/%E5%86%99%E7%9C%9F/ME11XuIpUXg
・https://unsplash.com/ja/%E5%86%99%E7%9C%9F/QwhIHDAEfYM
・https://unsplash.com/ja/%E5%86%99%E7%9C%9F/VoWGN5kuzt4
・https://unsplash.com/ja/%E5%86%99%E7%9C%9F/tV7JNH73cJg
・https://unsplash.com/ja/%E5%86%99%E7%9C%9F/eQdDUdi5qLk
・https://unsplash.com/ja/%E5%86%99%E7%9C%9F/0FdCO4C_R8M
大きさがバラバラなので640pxに統一しておく
このままYOLOv8モデルに投入しても動作すると思いますが、軽量化のために事前にリサイズしておきます。
サイズはUltralyticsで事前学習済みのモデルのインプットである640pxにします。
All YOLOv8 pretrained models are available here. Detect, Segment and Pose models are pretrained on the COCO dataset
引用: https://github.com/ultralytics/ultralytics#models
| Model | size(pixels) | mAP val50-95 | Speed CPU ONNX(ms) | Speed A100 TensorRT(ms) | params(M) | FLOPs(B) |
|---|---|---|---|---|---|---|
| YOLOv8n | 640 | 37.3 | 80.4 | 0.99 | 3.2 | 8.7 |
| YOLOv8s | 640 | 44.9 | 128.4 | 1.20 | 11.2 | 28.6 |
| YOLOv8m | 640 | 50.2 | 234.7 | 1.83 | 25.9 | 78.9 |
| YOLOv8l | 640 | 52.9 | 375.2 | 2.39 | 43.7 | 165.2 |
| YOLOv8x | 640 | 53.9 | 479.1 | 3.53 | 68.2 | 257.8 |
import os
import cv2
# インプットとアウトプット
input_folder = '/Users/hinomaruc/Desktop/blog/dataset/puppies_giraffe'
output_folder = '/Users/hinomaruc/Desktop/blog/dataset/puppies_giraffe_resized'
# アウトプットフォルダの作成
if not os.path.exists(output_folder):
os.makedirs(output_folder)
for file_name in os.listdir(input_folder):
if file_name.endswith('.jpg'):
# 画像の読み込み
file_path = os.path.join(input_folder, file_name)
img = cv2.imread(file_path)
# 画像の大きさを取得 (縦・横・チャンネル)
height, width, channels = img.shape
# 640pxに対して、縦横比の計算
ratio = 640 / max(height, width)
# 新しい大きさを計算
new_height = int(height * ratio)
new_width = int(width * ratio)
# リサイズ
resized_img = cv2.resize(img, (new_width, new_height), interpolation = cv2.INTER_AREA)
# 保存
output_path = os.path.join(output_folder, file_name)
cv2.imwrite(output_path, resized_img)リサイズ前後のファイルサイズとディメンションの確認
標準的なLinuxコマンドで確認できるようにしました。環境によっては結果が変わるかも知れません。私はMacbook pro 10.15.7 で確認しました。Pythonでやっても良かったかも知れません 笑
dir="puppies_giraffe"
for file in "$dir"/*
do
size=`ls -lh $file | cut -d' ' -f8`
dimensions=`file $file | cut -d',' -f8`
echo "$file,$size,$dimensions"
donepuppies_giraffe/andrew-lancaster-k34a6Yzt6A0-unsplash.jpg,1.2M, 4657x3105 puppies_giraffe/bharathi-kannan-rfL-thiRzDs-unsplash.jpg,1.5M, 5016x2491 puppies_giraffe/elena-mozhvilo-UspYqrVBsIo-unsplash.jpg,4.7M, 6016x4000 puppies_giraffe/jametlene-reskp-VDrErQEF9e4-unsplash.jpg,2.7M, 5472x3648 puppies_giraffe/jametlene-reskp-fliwkBbS7oM-unsplash.jpg,2.9M, 5472x3648 puppies_giraffe/judi-neumeyer-ECjHeJtRznQ-unsplash.jpg,4.6M, 5574x3585 puppies_giraffe/karel-van-der-auwera-VoWGN5kuzt4-unsplash.jpg,1.6M, 2448x3264 puppies_giraffe/mariola-grobelska-eQdDUdi5qLk-unsplash.jpg,2.9M, 5980x3835 puppies_giraffe/nathalie-spehner-ME11XuIpUXg-unsplash.jpg,2.2M, 3648x4560 puppies_giraffe/nicole-romero-QwhIHDAEfYM-unsplash.jpg,1.1M, 3750x2042 puppies_giraffe/steve-sewell-tV7JNH73cJg-unsplash.jpg,7.1M, 6000x4000 puppies_giraffe/valeria-hutter-0FdCO4C_R8M-unsplash.jpg,1.9M, 4000x6000
大きいサイズですね。リサイズ後を見てみます。
dir="puppies_giraffe_resized"
for file in "$dir"/*
do
size=`ls -lh $file | cut -d' ' -f8`
dimensions=`file $file | cut -d',' -f8`
echo "$file,$size,$dimensions"
donepuppies_giraffe_resized/andrew-lancaster-k34a6Yzt6A0-unsplash.jpg,, 640x426 puppies_giraffe_resized/bharathi-kannan-rfL-thiRzDs-unsplash.jpg,, 640x317 puppies_giraffe_resized/elena-mozhvilo-UspYqrVBsIo-unsplash.jpg,, 640x425 puppies_giraffe_resized/jametlene-reskp-VDrErQEF9e4-unsplash.jpg,, 640x426 puppies_giraffe_resized/jametlene-reskp-fliwkBbS7oM-unsplash.jpg,, 640x426 puppies_giraffe_resized/judi-neumeyer-ECjHeJtRznQ-unsplash.jpg,, 640x411 puppies_giraffe_resized/karel-van-der-auwera-VoWGN5kuzt4-unsplash.jpg,, 480x640 puppies_giraffe_resized/mariola-grobelska-eQdDUdi5qLk-unsplash.jpg,, 640x410 puppies_giraffe_resized/nathalie-spehner-ME11XuIpUXg-unsplash.jpg,, 512x640 puppies_giraffe_resized/nicole-romero-QwhIHDAEfYM-unsplash.jpg,, 640x348 puppies_giraffe_resized/steve-sewell-tV7JNH73cJg-unsplash.jpg,, 640x426 puppies_giraffe_resized/valeria-hutter-0FdCO4C_R8M-unsplash.jpg,, 426x640
正常にリサイズ出来ているようです。こちらのリサイズ済みの画像をYOLOv8のモデルに投入します。
物体検知モデルの精度確認のために、まずはground-truth data(正解データ)を作成する
predictによる予測結果が合っているか確認するためには正解データが必要になります。
物体検知の場合、画像を人間の手でアノテーションしたものを利用します。
今回はLabelImgというツールを使いました。
LabelImgはアノテーションツールになります。PythonとQtで作られていてPASCAL VOC、YOLO, CreateMLフォーマットに対応しています。
LabelImg is a graphical image annotation tool.
It is written in Python and uses Qt for its graphical interface.
Annotations are saved as XML files in PASCAL VOC format, the format used by ImageNet. Besides, it also supports YOLO and CreateML formats.
引用: https://github.com/heartexlabs/labelImg
また、LabelImgはLabel Studioというツールの一部になったようなので、そちらを使ったり他のラベリングツールでも問題ありません。個人で使う分にはシンプルで最低限の機能があるLabelImgで十分かと思います。他にも「labelme」というアノテーションツールもシンプルで使いやすくてお勧めです。
LabelImg is now part of the Label Studio community.
引用: https://github.com/heartexlabs/labelImg
LableImgのインストール方法は「installation」をご確認ください。私のMac環境だとpip install labelimgだけでOKでした。
LableImgの使い方
軽くLabelImgの使い方をご紹介しておきます。
- LableImgの起動画面
まずは「ディレクトリを開く」ボタンを押下し、画像が格納されているフォルダを選択します。私の場合だと/Users/hinomaruc/Desktop/blog/dataset/puppies_giraffe_resizedフォルダですね。
- フォルダ内の画像が表示されます
アノテーションのフォーマットがYOLOになっていることを確認します。
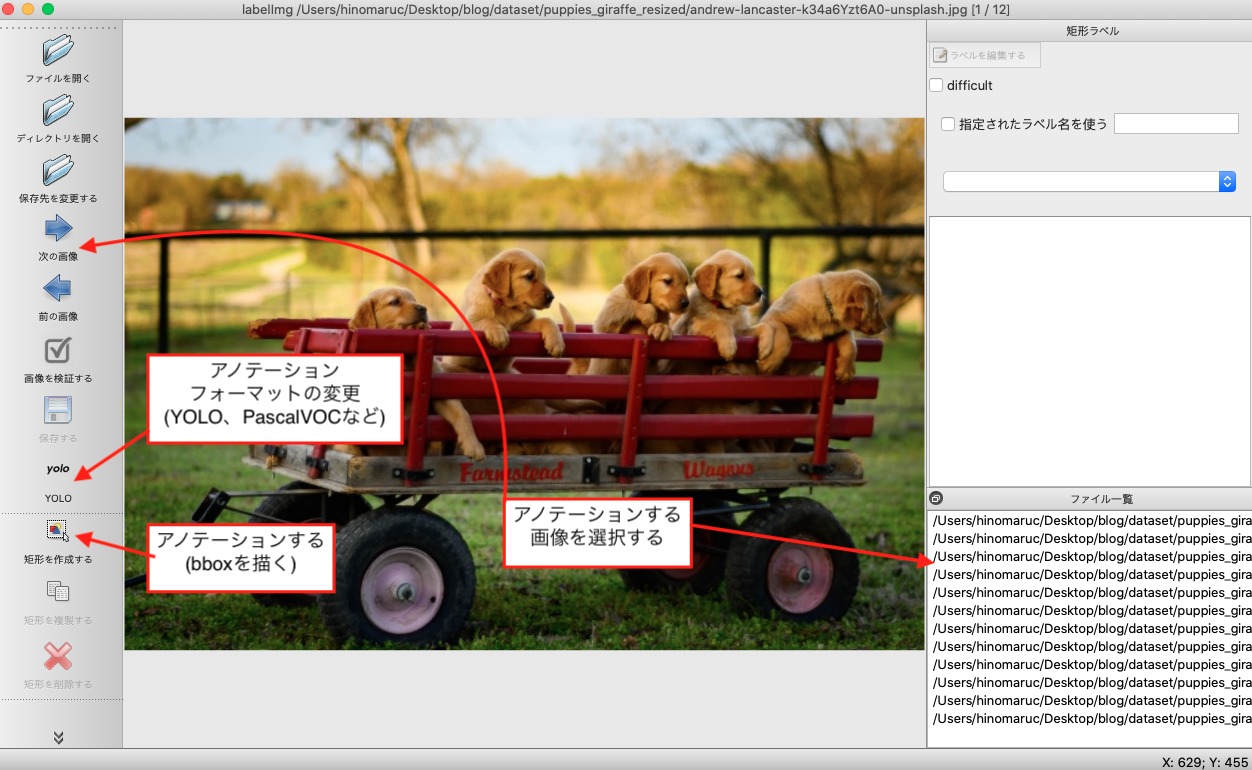
- 矩形を作成するボタンを押下し、アノテーションしていく
犬に見える物体を全てアノテーションしていきます。今回YOLOv8のpretrained modelを利用します。YOLOv8のobject detectionのpretrained modelはcoco 2017 datasetで学習されたモデルなので、アノテーションのときに正解データとしてタグ付けする名称もcoco 2017 datasetのクラス名に合わせます。
Ultralyticsの「datasets/coco.yaml」に記載されていますので参照ください。
今回ですと子犬という意味であるpuppiesがないので、「dog」で正解ラベルを付与していくことにします。キリンの画像の場合は「giraffe」というラベルでアノテーションします。
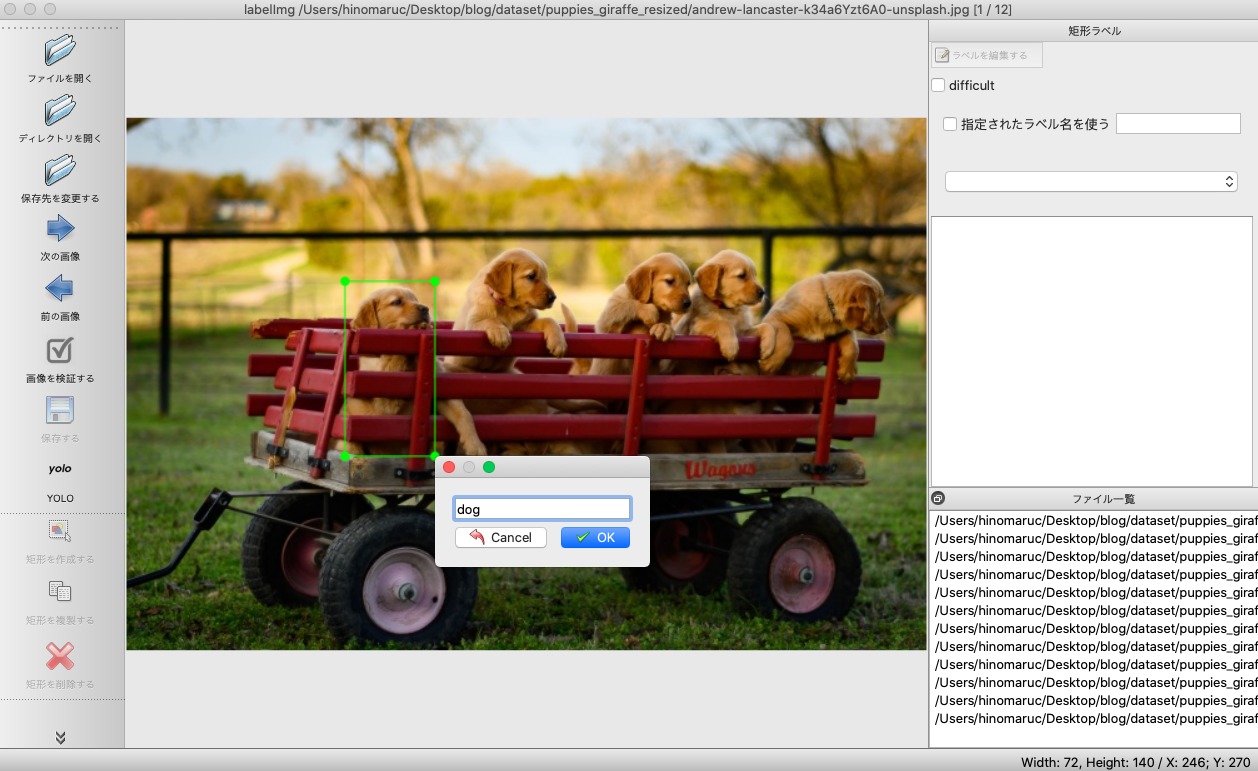
- 「犬」を全てアノテーションした後の画面
全部で5匹の子犬をアノテーションしました。他のバウンディングボックスと重なってアノテーションしてしまって問題ありません。他の画像も同じような手順でアノテーションしていきます。(繰り返しになりますが、キリンの場合は「giraffe」とラベル付けします 笑)
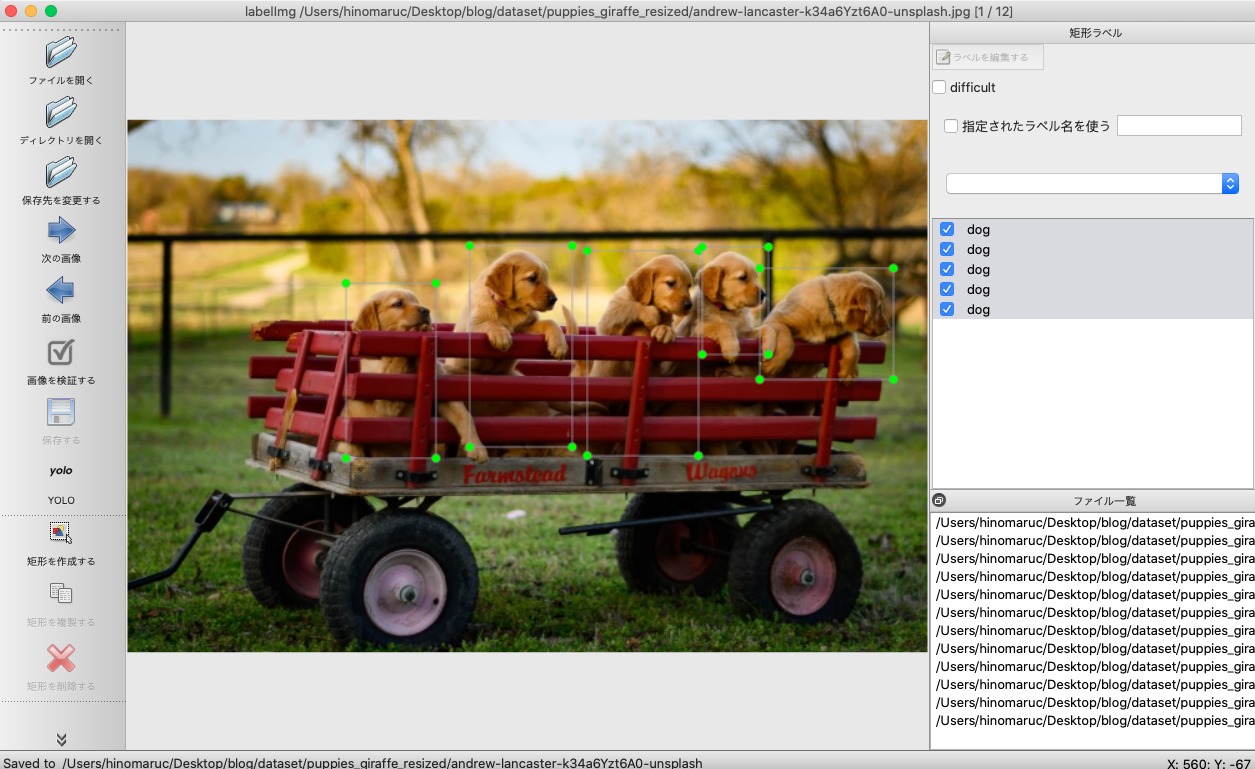
- アノテーションした後は「保存する」ボタンを押下します
保存するとフォルダの中に[classes.txt]と[画像ファイル名.txt]の2つのファイルが作成されています。YOLO形式は画像ごとにtxtファイルが作成されますので、12枚の画像をアノテーションするとtxtファイルが12個作成されると思います。classes.txtはアノテーションしたラベル名です。今回はdogとgiraffeだけなので2種類しか記載がありませんが、猫をcatとしてアノテーションするとclasses.txtにcatも追記されます。
下記は12枚の画像を全てアノテーションした後のフォルダのスクリーンショットです。
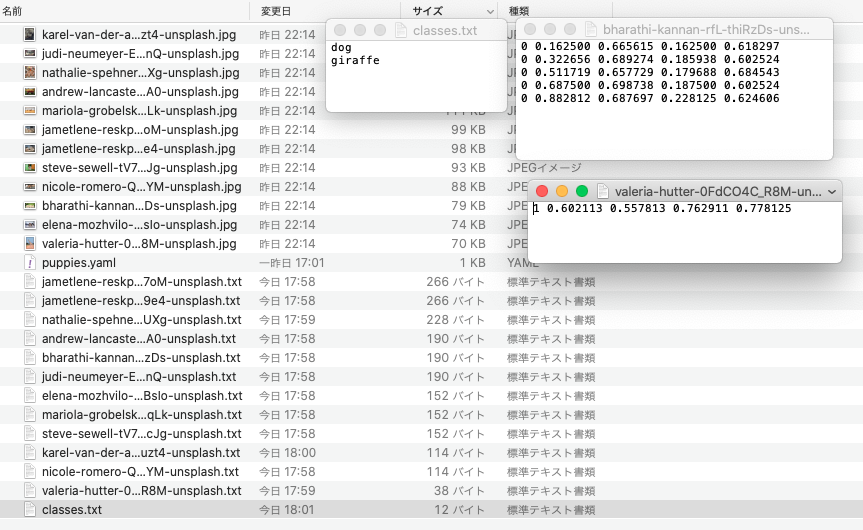
- 学習に使ったラベルに合わせてアノテーション済みのラベル番号を変更する
coco2017だとdogは16番でgiraffeは23番と定義されているのでそちらに合わせます。
もしYOLOv8のpretrained modelを使ってvalモード実行時にラベルを0番や1番のままにしておくと、結果がpersonやbicycleと異なる名称で出てきてしまいます。(coco2017のクラス定義で出力される)
ラベルを0番と1番のままにしてpretrained modelでvalモードを使った例としては下記になります。本当はdogとgiraffeと出て欲しいのに違うラベル名が出てきてしまう。
Class Images Instances Box(P R mAP50 m all 12 54 0.933 0.878 0.948 0.646 person 12 49 0.946 0.755 0.901 0.597 bicycle 12 5 0.92 1 0.995 0.694
最初からcocoの80種類のラベルをclasses.txtに追記した上でアノテーションすればいいのではないかと思いましたが、やってみるとLabelImgは新規アノテーションするとclasses.txtが上書きされてしまうようで上手くいきませんでした。
ラベル付け替えの具体的な手順ですが、アノテーションファイルの先頭のラベル番号「0」を「16」、「1」を「23」に変更します。アノテーションツール側で対応できれば一番楽ですがLabelImgでは対応が難しそうです。(※ もしキリン画像を先にアノテーションした場合は0がキリンを指している可能性もあるので要確認)
下記は「0」が犬だった場合の付け替え例です。「16」に変更します。
変更前:
0 0.171875 0.464080 0.306250 0.635057 0 0.461719 0.534483 0.323437 0.804598 0 0.806250 0.396552 0.387500 0.574713
変更後:
16 0.171875 0.464080 0.306250 0.635057 16 0.461719 0.534483 0.323437 0.804598 16 0.806250 0.396552 0.387500 0.574713
さすがに手動で直すのは辛いのでPython側でやってしまいます。
import glob
# ラベルを付け替える用の辞書
label_dict = {0:16,1:23}
# 元ファイル置き場
folder_path = "/Users/hinomaruc/Desktop/blog/dataset/puppies_giraffe_resized"
# アノテーションファイルを取得
txt_files = glob.glob(folder_path + "/*.txt")
# 書き換える
for txt_file in txt_files:
# classes.txtは除外
if txt_file.endswith("classes.txt"):
continue
with open(txt_file, "r") as f:
lines = f.readlines()
new_lines = []
for line in lines:
line_parts = line.split()
label = int(line_parts[0])
if label in label_dict:
line_parts[0] = str(label_dict[label])
new_line = " ".join(line_parts) + "\n"
new_lines.append(new_line)
# 書き込む
with open(txt_file, "w") as f:
f.writelines(new_lines)これで準備は完了です。
YOLOv8でdetectを実行
最初yolov8n.ptモデルで推論したのですが、あまり精度がよくなかったので、yolov8m.ptモデルを適用しました。ほどほど誤検知や未検知があるので精度検証するには良さそうなサンプルになりました。
from ultralytics import YOLO
# 事前学習済みのモデルを読み込み(detectionモデルを使用)
model = YOLO('yolov8m.pt')
# predictモードを実行
results = model.predict(source="/Users/hinomaruc/Desktop/blog/dataset/puppies_giraffe_resized",
project="/Users/hinomaruc/Desktop/blog/dataset/yolov8/runs", # 出力先
name="puppies_giraffe", #フォルダ名
exist_ok=True, #上書きOKか
save=True)image 1/12 /Users/hinomaruc/Desktop/blog/dataset/puppies_giraffe_resized/andrew-lancaster-k34a6Yzt6A0-unsplash.jpg: 448x640 1 truck, 7 dogs, 1768.7ms image 2/12 /Users/hinomaruc/Desktop/blog/dataset/puppies_giraffe_resized/bharathi-kannan-rfL-thiRzDs-unsplash.jpg: 320x640 6 dogs, 1299.8ms image 3/12 /Users/hinomaruc/Desktop/blog/dataset/puppies_giraffe_resized/elena-mozhvilo-UspYqrVBsIo-unsplash.jpg: 448x640 4 dogs, 1 chair, 1737.6ms image 4/12 /Users/hinomaruc/Desktop/blog/dataset/puppies_giraffe_resized/jametlene-reskp-VDrErQEF9e4-unsplash.jpg: 448x640 1 cat, 5 dogs, 1748.3ms image 5/12 /Users/hinomaruc/Desktop/blog/dataset/puppies_giraffe_resized/jametlene-reskp-fliwkBbS7oM-unsplash.jpg: 448x640 9 dogs, 1934.3ms image 6/12 /Users/hinomaruc/Desktop/blog/dataset/puppies_giraffe_resized/judi-neumeyer-ECjHeJtRznQ-unsplash.jpg: 416x640 6 dogs, 1 sheep, 1800.5ms image 7/12 /Users/hinomaruc/Desktop/blog/dataset/puppies_giraffe_resized/karel-van-der-auwera-VoWGN5kuzt4-unsplash.jpg: 640x480 1 dog, 1995.6ms image 8/12 /Users/hinomaruc/Desktop/blog/dataset/puppies_giraffe_resized/mariola-grobelska-eQdDUdi5qLk-unsplash.jpg: 416x640 4 giraffes, 1631.5ms image 9/12 /Users/hinomaruc/Desktop/blog/dataset/puppies_giraffe_resized/nathalie-spehner-ME11XuIpUXg-unsplash.jpg: 640x512 6 dogs, 2061.4ms image 10/12 /Users/hinomaruc/Desktop/blog/dataset/puppies_giraffe_resized/nicole-romero-QwhIHDAEfYM-unsplash.jpg: 352x640 2 dogs, 1 bear, 1468.0ms image 11/12 /Users/hinomaruc/Desktop/blog/dataset/puppies_giraffe_resized/steve-sewell-tV7JNH73cJg-unsplash.jpg: 448x640 1 truck, 2 dogs, 1746.7ms image 12/12 /Users/hinomaruc/Desktop/blog/dataset/puppies_giraffe_resized/valeria-hutter-0FdCO4C_R8M-unsplash.jpg: 640x448 1 person, 1 giraffe, 1797.0ms Speed: 1.7ms preprocess, 1749.1ms inference, 1.9ms postprocess per image at shape (1, 3, 640, 640) Results saved to /Users/hinomaruc/Desktop/blog/dataset/yolov8/runs/puppies_giraffe

(オプション) 参考までにyolov8n.pyモデルを適用した結果
全体的に確信度も低いし、テディベアと間違ってしまってる画像もありますね 笑
image 1/12 /Users/hinomaruc/Desktop/blog/dataset/puppies_giraffe_resized/andrew-lancaster-k34a6Yzt6A0-unsplash.jpg: 448x640 1 person, 1 truck, 1 dog, 2 teddy bears, 296.4ms image 2/12 /Users/hinomaruc/Desktop/blog/dataset/puppies_giraffe_resized/bharathi-kannan-rfL-thiRzDs-unsplash.jpg: 320x640 6 dogs, 217.1ms image 3/12 /Users/hinomaruc/Desktop/blog/dataset/puppies_giraffe_resized/elena-mozhvilo-UspYqrVBsIo-unsplash.jpg: 448x640 4 dogs, 273.4ms image 4/12 /Users/hinomaruc/Desktop/blog/dataset/puppies_giraffe_resized/jametlene-reskp-VDrErQEF9e4-unsplash.jpg: 448x640 1 cat, 3 dogs, 286.2ms image 5/12 /Users/hinomaruc/Desktop/blog/dataset/puppies_giraffe_resized/jametlene-reskp-fliwkBbS7oM-unsplash.jpg: 448x640 4 dogs, 279.4ms image 6/12 /Users/hinomaruc/Desktop/blog/dataset/puppies_giraffe_resized/judi-neumeyer-ECjHeJtRznQ-unsplash.jpg: 416x640 1 cat, 2 dogs, 270.6ms image 7/12 /Users/hinomaruc/Desktop/blog/dataset/puppies_giraffe_resized/karel-van-der-auwera-VoWGN5kuzt4-unsplash.jpg: 640x480 1 dog, 303.1ms image 8/12 /Users/hinomaruc/Desktop/blog/dataset/puppies_giraffe_resized/mariola-grobelska-eQdDUdi5qLk-unsplash.jpg: 416x640 5 giraffes, 277.3ms image 9/12 /Users/hinomaruc/Desktop/blog/dataset/puppies_giraffe_resized/nathalie-spehner-ME11XuIpUXg-unsplash.jpg: 640x512 1 dog, 3 teddy bears, 350.1ms image 10/12 /Users/hinomaruc/Desktop/blog/dataset/puppies_giraffe_resized/nicole-romero-QwhIHDAEfYM-unsplash.jpg: 352x640 2 dogs, 223.4ms image 11/12 /Users/hinomaruc/Desktop/blog/dataset/puppies_giraffe_resized/steve-sewell-tV7JNH73cJg-unsplash.jpg: 448x640 3 dogs, 271.8ms image 12/12 /Users/hinomaruc/Desktop/blog/dataset/puppies_giraffe_resized/valeria-hutter-0FdCO4C_R8M-unsplash.jpg: 640x448 1 giraffe, 289.7ms Speed: 1.6ms preprocess, 278.2ms inference, 1.6ms postprocess per image at shape (1, 3, 640, 640) Results saved to /Users/hinomaruc/Desktop/blog/dataset/yolov8/runs/puppies_giraffe

yamlファイルの作成
独自のvalデータセットを読み込ませるために新しいyamlファイルを作成し、val実行時に指定します。
yamlフォーマットはcoco128.yamlを参考に作成します。
下記のようになりました。今回はYOLOv8のpremodelを利用するのでnamesはcocoの80クラスをそのまま記載しています。
しかし、names:はval実行時には特に使ってないみたいなので中身が適当でも動きます 笑
→ 23/5/7追記 アノテーションラベルにラベル番号が23という数字がある場合、少なくとも23行namesに記載しないと下記warningとValueErrorが発生するようです。
Warning: Label class 23 exceeds dataset class count 3. Possible class labels are 0-2 ValueError: not enough values to unpack (expected 3, got 0)
yamlファイルにtest:という項目がありますが、こちらは現状定義だけですかね。将来的にtestモードなどが実装されたら使われるのかも知れません。(私が公式ドキュメント内でtest項目が使われている箇所を見つけられていない可能性はあり)
→ 23/5/6追記 val:に何かしらちゃんと存在するフォルダを指定している場合のみ、model.val(split='test')と指定してあげればyamlのtest:で指定しているフォルダを参照してくれました。(val:に存在しないディレクトリを記載するとエラーになります)
# Train/val/test sets as 1) dir: path/to/imgs, 2) file: path/to/imgs.txt, or 3) list: [path/to/imgs1, path/to/imgs2, ..]
path: /Users/hinomaruc/Desktop/blog/dataset # dataset root dir
train: images/train2017 # train images (relative to 'path') 128 images
val: ../puppies_giraffe_resized
test: # model.val(split='test')でval時にテストフォルダを参照する
# Classes
names:
0: person
1: bicycle
2: car
3: motorcycle
4: airplane
5: bus
6: train
7: truck
8: boat
9: traffic light
10: fire hydrant
11: stop sign
12: parking meter
13: bench
14: bird
15: cat
16: dog
17: horse
18: sheep
19: cow
20: elephant
21: bear
22: zebra
23: giraffe
24: backpack
25: umbrella
26: handbag
27: tie
28: suitcase
29: frisbee
30: skis
31: snowboard
32: sports ball
33: kite
34: baseball bat
35: baseball glove
36: skateboard
37: surfboard
38: tennis racket
39: bottle
40: wine glass
41: cup
42: fork
43: knife
44: spoon
45: bowl
46: banana
47: apple
48: sandwich
49: orange
50: broccoli
51: carrot
52: hot dog
53: pizza
54: donut
55: cake
56: chair
57: couch
58: potted plant
59: bed
60: dining table
61: toilet
62: tv
63: laptop
64: mouse
65: remote
66: keyboard
67: cell phone
68: microwave
69: oven
70: toaster
71: sink
72: refrigerator
73: book
74: clock
75: vase
76: scissors
77: teddy bear
78: hair drier
79: toothbrushYOLOv8のvalモードの実行
model.val()でvalモードを実行できます。valはvalidationの略で、モデルの精度を検証する機能になります。
valモードを実行すると物体検知モデルの場合はDetMetricsオブジェクトが返却されます (DetはDetectionの略だと推測します)。
valモードで精度を出力してみる
それではさっそくmodel.val()を使ってみます。valメソッドの引数に先ほど作成した検証データの場所を指すyamlファイル(puppies-giraffe.yaml)を指定します
今回Ultralytics側で学習済みのpretrained model(yolov8m.pt)を使うため、valメソッドでdataやimgszを引数として設定しています。しかし通常trainの後にvalを実行する場合はmodelオブジェクトに各種設定を引き継いでくれているらしくmodel('yolov8m.pt').val()と空白のまま実行すれば良いみたいです。
YOLOv8 models automatically remember their training settings, so you can validate a model at the same image size and on the original dataset easily with just yolo val model=yolov8n.pt or model('yolov8n.pt').val()
# モデルの検証
metrics = model.val(
data="/Users/hinomaruc/Desktop/blog/dataset/puppies_graffe_resized/puppies-giraffe.yaml",
imgsz=640,
save_json=True)
Ultralytics YOLOv8.0.78 🚀 Python-3.7.16 torch-1.13.1 CPU
YOLOv8m summary (fused): 218 layers, 25886080 parameters, 0 gradients, 78.9 GFLOPs
val: Scanning /Users/hinomaruc/Desktop/blog/dataset/puppies_giraffe_resized... 1
val: New cache created: /Users/hinomaruc/Desktop/blog/dataset/puppies_giraffe_resized.cache
Class Images Instances Box(P R mAP50 m
all 12 54 0.933 0.878 0.948 0.646
dog 12 49 0.946 0.755 0.901 0.597
giraffe 12 5 0.92 1 0.995 0.694
Speed: 4.7ms preprocess, 2868.2ms inference, 0.0ms loss, 3.0ms postprocess per image
Saving runs/detect/val/predictions.json...
Results saved to runs/detect/val
結果が出てきました。
allとクラスごとの精度検証結果が出力されています。
まず、Imagesはテストデータセットの枚数全体のようです。犬の写真は全部で10枚、キリンの画像は全部で2枚ありますので合計12枚になります。
dogをみると49匹の犬が存在しPrecisionが0.946、Recallが0.755、mAP50が0.901、mAP50-95だと0.597という精度になるようです。(50や95はIoUの閾値になります。何それという方は物体検知モデルの精度指標を色々確認してみるで精度指標に関してまとめているのでぜひご覧になってください。)
giraffeは全部で5匹いて、Precisionは0.92、Recallが1、mAP50が0.995、mAP50-95だと0.694という精度になりました。
中々良い精度ではないでしょうか?
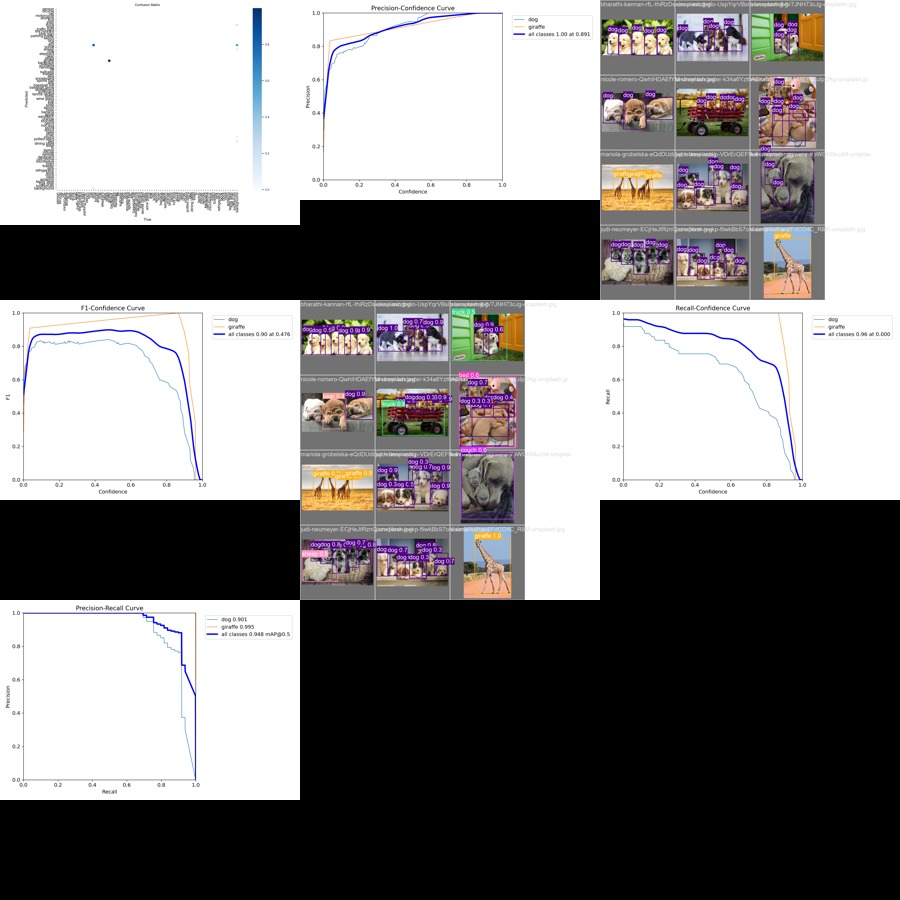
Results saved to runs/detect/valとあるようにvalフォルダ以下に精度検証のグラフが出力されています。
→ 23/5/12追記: ドキュメントに記載はないですが、#2151を参考にpredictモードにあったproject・name・exist_okパラメータをmodel.val()に設定すれば結果を任意の場所に出力できます。
→ 23/5/12追記: 出力結果の1つであるval_batch0_pred.jpgですが、最大15個しか検知結果を表示しないように制御しているようです。詳細:val.py#L222。そして、もしかしたらconfも0.25で足切りされているかも? 詳細:plotting.py#L372
下記の様な感じで色々グラフィカルに確認することが可能になっています。
DetMetricsクラスについて
DetMetricsクラスに関してはutils.metrics.DetMetricsセクションに説明がありました。
23年4月現在、valメソッドからDetMetricsの細かな設定はできないようです。例えば、val結果を出力するディレクトリの場所の設定やグラフ作成のオン・オフなどです。

Metricクラスについて
DetMetricsオブジェクトの中にはboxという名前のMetricオブジェクトが格納されています。Metricクラスは精度検証に必要な各種指標を計算するためのクラスで、Precision・Recall・F1・AP(for all classes)といった精度指標の属性を持ちます。
Class for computing evaluation metrics for YOLOv8 model
引用: https://docs.ultralytics.com/reference/yolo/utils/metrics/#ultralytics.yolo.utils.metrics.Metric
Metricクラスの属性とメソッド一覧はutils.metrics.Metricセクションを参照ください。
下記にいつでも復習出来るように説明書きを引用としてまとめておきます。
MetricクラスのAttributes:
p (list): Precision for each class. Shape: (nc,).
r (list): Recall for each class. Shape: (nc,).
f1 (list): F1 score for each class. Shape: (nc,).
all_ap (list): AP scores for all classes and all IoU thresholds. Shape: (nc, 10).
ap_class_index (list): Index of class for each AP score. Shape: (nc,).
nc (int): Number of classes.
MetricクラスのMethods:
ap50(): AP at IoU threshold of 0.5 for all classes. Returns: List of AP scores. Shape: (nc,) or [].
ap(): AP at IoU thresholds from 0.5 to 0.95 for all classes. Returns: List of AP scores. Shape: (nc,) or [].
mp(): Mean precision of all classes. Returns: Float.
mr(): Mean recall of all classes. Returns: Float.
map50(): Mean AP at IoU threshold of 0.5 for all classes. Returns: Float.
map75(): Mean AP at IoU threshold of 0.75 for all classes. Returns: Float.
map(): Mean AP at IoU thresholds from 0.5 to 0.95 for all classes. Returns: Float.
mean_results(): Mean of results, returns mp, mr, map50, map.
class_result(i): Class-aware result, returns p[i], r[i], ap50[i], ap[i]. maps(): mAP of each class. Returns: Array of mAP scores, shape: (nc,).
fitness(): Model fitness as a weighted combination of metrics. Returns: Float.
update(results): Update metric attributes with new evaluation results.
引用: https://docs.ultralytics.com/reference/yolo/utils/metrics/#ultralytics.yolo.utils.metrics.Metric
DetMetricsオブジェクトとMetricオブジェクトの中身の確認
最後にDetMetricsオブジェクト(metrics)とMetricオブジェクト(metrics.box)の中身をざっとみてみます。
DetMetricsオブジェクトの中身
metrics
ultralytics.yolo.utils.metrics.DetMetrics object with attributes:
ap_class_index: array([16, 23])
box: ultralytics.yolo.utils.metrics.Metric object
confusion_matrix: ultralytics.yolo.utils.metrics.ConfusionMatrix object at 0x14858ffd0>
fitness: 0.6757397366469017
keys: ['metrics/precision(B)', 'metrics/recall(B)', 'metrics/mAP50(B)', 'metrics/mAP50-95(B)']
maps: array([ 0.6455, 0.6455, 0.6455, 0.6455, 0.6455, 0.6455, 0.6455, 0.6455, 0.6455, 0.6455, 0.6455, 0.6455, 0.6455, 0.6455, 0.6455, 0.6455, 0.59735, 0.6455, 0.6455, 0.6455, 0.6455, 0.6455, 0.6455, 0.69366,
0.6455, 0.6455, 0.6455, 0.6455, 0.6455, 0.6455, 0.6455, 0.6455, 0.6455, 0.6455, 0.6455, 0.6455, 0.6455, 0.6455, 0.6455, 0.6455, 0.6455, 0.6455, 0.6455, 0.6455, 0.6455, 0.6455, 0.6455, 0.6455,
0.6455, 0.6455, 0.6455, 0.6455, 0.6455, 0.6455, 0.6455, 0.6455, 0.6455, 0.6455, 0.6455, 0.6455, 0.6455, 0.6455, 0.6455, 0.6455, 0.6455, 0.6455, 0.6455, 0.6455, 0.6455, 0.6455, 0.6455, 0.6455,
0.6455, 0.6455, 0.6455, 0.6455, 0.6455, 0.6455, 0.6455, 0.6455])
names: {0: 'person', 1: 'bicycle', 2: 'car', 3: 'motorcycle', 4: 'airplane', 5: 'bus', 6: 'train', 7: 'truck', 8: 'boat', 9: 'traffic light', 10: 'fire hydrant', 11: 'stop sign', 12: 'parking meter', 13: 'bench', 14: 'bird', 15: 'cat', 16: 'dog', 17: 'horse', 18: 'sheep', 19: 'cow', 20: 'elephant', 21: 'bear', 22: 'zebra', 23: 'giraffe', 24: 'backpack', 25: 'umbrella', 26: 'handbag', 27: 'tie', 28: 'suitcase', 29: 'frisbee', 30: 'skis', 31: 'snowboard', 32: 'sports ball', 33: 'kite', 34: 'baseball bat', 35: 'baseball glove', 36: 'skateboard', 37: 'surfboard', 38: 'tennis racket', 39: 'bottle', 40: 'wine glass', 41: 'cup', 42: 'fork', 43: 'knife', 44: 'spoon', 45: 'bowl', 46: 'banana', 47: 'apple', 48: 'sandwich', 49: 'orange', 50: 'broccoli', 51: 'carrot', 52: 'hot dog', 53: 'pizza', 54: 'donut', 55: 'cake', 56: 'chair', 57: 'couch', 58: 'potted plant', 59: 'bed', 60: 'dining table', 61: 'toilet', 62: 'tv', 63: 'laptop', 64: 'mouse', 65: 'remote', 66: 'keyboard', 67: 'cell phone', 68: 'microwave', 69: 'oven', 70: 'toaster', 71: 'sink', 72: 'refrigerator', 73: 'book', 74: 'clock', 75: 'vase', 76: 'scissors', 77: 'teddy bear', 78: 'hair drier', 79: 'toothbrush'}
plot: True
results_dict: {'metrics/precision(B)': 0.9331572155711829, 'metrics/recall(B)': 0.8775510204081632, 'metrics/mAP50(B)': 0.9478627871442975, 'metrics/mAP50-95(B)': 0.6455038421471909, 'fitness': 0.6757397366469017}
save_dir: PosixPath('runs/detect/val9')
speed: {'preprocess': 4.679262638092041, 'inference': 2868.187586466471, 'loss': 0.0002384185791015625, 'postprocess': 2.9564102490743003}
Metricオブジェクトの中身を確認しなくても色々確認できそうです。
まず目を引くのがmapsですが、全80クラス分のmAPが表示されているようです。
maps property
mAP of each class.
引用: https://docs.ultralytics.com/reference/yolo/utils/metrics/
次に精度指標がまとめて確認できそうなDetMetricsのresults_dictプロパティに注目してみます。
# Returns dictionary of computed performance metrics and statistics.
metrics.results_dict
{'metrics/precision(B)': 0.9331572155711829,
'metrics/recall(B)': 0.8775510204081632,
'metrics/mAP50(B)': 0.9478627871442975,
'metrics/mAP50-95(B)': 0.6455038421471909,
'fitness': 0.6757397366469017}
特定クラスの結果ではなくて、全クラスの平均の精度を出力してくれているようです。
この中でfitnessだけ意味が分からなかったので調べたところ、Precision・Recall・mAP@0.5・mAP@0.5:0.95を重み付けして合算させた値のようです。
上記で言うと0.9478627871442975 x 0.1 + 0.6455038421471909 x 0.9 = 0.67573973664 という計算になるようです。
def fitness(self):
"""Model fitness as a weighted combination of metrics."""
w = [0.0, 0.0, 0.1, 0.9] # weights for [P, R, mAP@0.5, mAP@0.5:0.95]
return (np.array(self.mean_results()) * w).sum()
引用: Source code in ultralytics/yolo/utils/metrics.py
Metricオブジェクトの中身
次にMetricオブジェクトの中身を確認してみます。
metrics.box
ultralytics.yolo.utils.metrics.Metric object with attributes:
all_ap: array([[ 0.90073, 0.8701, 0.8701, 0.78743, 0.68193, 0.60271, 0.51143, 0.36108, 0.28949, 0.098472],
[ 0.995, 0.995, 0.995, 0.64536, 0.64536, 0.64536, 0.64536, 0.64536, 0.37611, 0.34867]])
ap: array([ 0.59735, 0.69366])
ap50: array([ 0.90073, 0.995])
ap_class_index: array([16, 23])
f1: array([ 0.83989, 0.95843])
map: 0.6455038421471909
map50: 0.9478627871442975
map75: 0.6240353434807746
maps: array([ 0.6455, 0.6455, 0.6455, 0.6455, 0.6455, 0.6455, 0.6455, 0.6455, 0.6455, 0.6455, 0.6455, 0.6455, 0.6455, 0.6455, 0.6455, 0.6455, 0.59735, 0.6455, 0.6455, 0.6455, 0.6455, 0.6455, 0.6455, 0.69366,
0.6455, 0.6455, 0.6455, 0.6455, 0.6455, 0.6455, 0.6455, 0.6455, 0.6455, 0.6455, 0.6455, 0.6455, 0.6455, 0.6455, 0.6455, 0.6455, 0.6455, 0.6455, 0.6455, 0.6455, 0.6455, 0.6455, 0.6455, 0.6455,
0.6455, 0.6455, 0.6455, 0.6455, 0.6455, 0.6455, 0.6455, 0.6455, 0.6455, 0.6455, 0.6455, 0.6455, 0.6455, 0.6455, 0.6455, 0.6455, 0.6455, 0.6455, 0.6455, 0.6455, 0.6455, 0.6455, 0.6455, 0.6455,
0.6455, 0.6455, 0.6455, 0.6455, 0.6455, 0.6455, 0.6455, 0.6455])
mp: 0.9331572155711829
mr: 0.8775510204081632
nc: 80
p: array([ 0.94613, 0.92018])
r: array([ 0.7551, 1])
all_apはクラスごとのAPをIoU0.5~0.95まで0.05刻みで計算したものを確認してくれているようです。
ap_class_indexが対応するクラス番号ですね。ap[0]は16:dogを表し、ap[1]は23:giraffeの結果を表すということがap_class_indexの順番でわかります。
まとめ
精度確認系は個人的には一番重要なパートだと思っているので少し詳しくまとめてみました。
YOLOv8では簡単にモデルが作成でき、かつ精度検証もできるのでおすすめのツールになりました 笑
次は特定の領域のみで物体検知して精度を確認したい場合にどうしたらいいのか調べてみたいと思います。
正解データを必要な部分のみアノテーションしつつ、「YOLOv8で特定のエリアのみ物体検知する方法」の記事で試した通り必要ない部分を黒塗りした画像を用意してマスクすれば実現可能かなと考えています。
