前回、ロジスティック回帰CVで76.7%の精度でした。
今回はナイーブベイズを使って予測してみようと思います。
The sklearn.naive_bayes module implements Naive Bayes algorithms. These are supervised learning methods based on applying Bayes’ theorem with strong (naive) feature independence assumptions.
引用: https://scikit-learn.org/stable/modules/classes.html
sklearnのドキュメントにはナイーブベイズはベイズの定理が基礎になっていて、変数間に強い独立性を仮定している教師ありのメソッドと説明されています。
以前RecSysというリコメンドシステムの学会に参加したとき(発表したわけではありません 笑)、とある企業の発表を聞く機会がありました。
発表の中でユーザー属性の推定をする箇所があったかと思うのですが、その時利用されていたのがナイーブベイズでした。
実装しやすく変数間に独立性を仮定しなければいけないが実際は独立していなくても使ってみると精度は悪くなかったと言ってたかと思います。
その発表を聞いて以来、ヒノマルクもナイーブベイズのファンになり多様するようになりました 笑
You do not have to normalize the probabilities if you only care about knowing which class your input most likely belongs to.
If you do want the class probabilities, then you indeed need to normalize:
引用: https://stats.stackexchange.com/questions/249762/with-the-naive-bayes-classifier-why-do-we-have-to-normalize-the-probabilities-a
またナイーブベイズを扱う上でのデータの標準化に関してですが、分類する上では気にしなくても良さそうですがクラスへの所属確率が必要な場合は標準化した方がいいとのことです。
それではやってみましょう。
全部で5種類のナイーブベイズがあったので全て試します。
評価指標
タイタニックのデータセットは生存有無を正確に予測できた乗客の割合(Accuracy)を評価指標としています。
分析用データの準備
事前に欠損値処理や特徴量エンジニアリングを実施してデータをエクスポートしています。
本記事と同じ結果にするためには事前に下記記事を確認してデータを用意してください。
学習データと評価データの読み込み
import pandas as pd
import numpy as np
# タイタニックデータセットの学習用データと評価用データの読み込み
df_train = pd.read_csv("/Users/hinomaruc/Desktop/notebooks/titanic/titanic_train.csv")
df_eval = pd.read_csv("/Users/hinomaruc/Desktop/notebooks/titanic/titanic_eval.csv")概要確認
# 概要確認
df_train.info()
RangeIndex: 891 entries, 0 to 890
Data columns (total 22 columns):
# Column Non-Null Count Dtype
--- ------ -------------- -----
0 PassengerId 891 non-null int64
1 Survived 891 non-null int64
2 Pclass 891 non-null int64
3 Name 891 non-null object
4 Sex 891 non-null object
5 Age 891 non-null float64
6 SibSp 891 non-null int64
7 Parch 891 non-null int64
8 Ticket 891 non-null object
9 Fare 891 non-null float64
10 Cabin 204 non-null object
11 Embarked 891 non-null object
12 FamilyCnt 891 non-null int64
13 SameTicketCnt 891 non-null int64
14 Pclass_str_1 891 non-null float64
15 Pclass_str_2 891 non-null float64
16 Pclass_str_3 891 non-null float64
17 Sex_female 891 non-null float64
18 Sex_male 891 non-null float64
19 Embarked_C 891 non-null float64
20 Embarked_Q 891 non-null float64
21 Embarked_S 891 non-null float64
dtypes: float64(10), int64(7), object(5)
memory usage: 153.3+ KB
# 概要確認
df_eval.info()
RangeIndex: 418 entries, 0 to 417
Data columns (total 21 columns):
# Column Non-Null Count Dtype
--- ------ -------------- -----
0 PassengerId 418 non-null int64
1 Pclass 418 non-null int64
2 Name 418 non-null object
3 Sex 418 non-null object
4 Age 418 non-null float64
5 SibSp 418 non-null int64
6 Parch 418 non-null int64
7 Ticket 418 non-null object
8 Fare 418 non-null float64
9 Cabin 91 non-null object
10 Embarked 418 non-null object
11 Pclass_str_1 418 non-null float64
12 Pclass_str_2 418 non-null float64
13 Pclass_str_3 418 non-null float64
14 Sex_female 418 non-null float64
15 Sex_male 418 non-null float64
16 Embarked_C 418 non-null float64
17 Embarked_Q 418 non-null float64
18 Embarked_S 418 non-null float64
19 FamilyCnt 418 non-null int64
20 SameTicketCnt 418 non-null int64
dtypes: float64(10), int64(6), object(5)
memory usage: 68.7+ KB
# 描画設定
import seaborn as sns
from matplotlib import ticker
import matplotlib.pyplot as plt
sns.set_style("whitegrid")
from matplotlib import rcParams
rcParams['font.family'] = 'Hiragino Sans' # Macの場合
#rcParams['font.family'] = 'Meiryo' # Windowsの場合
#rcParams['font.family'] = 'VL PGothic' # Linuxの場合
rcParams['xtick.labelsize'] = 12 # x軸のラベルのフォントサイズ
rcParams['ytick.labelsize'] = 12 # y軸のラベルのフォントサイズ
rcParams['axes.labelsize'] = 18 # ラベルのフォントとサイズ
rcParams['figure.figsize'] = 18,8 # 画像サイズの変更(inch)モデリング用に学習用データを訓練データとテストデータに分割
# 訓練データとテストデータに分割する。
from sklearn.model_selection import train_test_split
x_train, x_test = train_test_split(df_train, test_size=0.20,random_state=100)
# 説明変数
FEATURE_COLS=[
'Age'
, 'Fare'
, 'SameTicketCnt'
, 'Pclass_str_1'
, 'Pclass_str_3'
, 'Sex_female'
, 'Embarked_Q'
, 'Embarked_S'
]
X_train = x_train[FEATURE_COLS] # 説明変数 (train)
Y_train = x_train["Survived"] # 目的変数 (train)
X_test = x_test[FEATURE_COLS] # 説明変数 (test)
Y_test = x_test["Survived"] # 目的変数 (test)ナイーブベイズ (GaussianNB)
モデル作成 (GaussianNB)
# https://scikit-learn.org/stable/modules/generated/sklearn.naive_bayes.GaussianNB.html
from sklearn.naive_bayes import GaussianNB
from sklearn.pipeline import make_pipeline
from sklearn.preprocessing import StandardScaler
pipeline = make_pipeline(StandardScaler(), GaussianNB())fit_pipeline = pipeline.fit(X_train,Y_train)# 訓練データへの当てはまりを確認
# Return the mean accuracy on the given test data and labels.
fit_pipeline.score(X_train,Y_train)
0.7935393258426966
# テストデータへの当てはまりを確認
# Return the mean accuracy on the given test data and labels.
fit_pipeline.score(X_test,Y_test)
0.7988826815642458
# モデルパラメータ一覧
fit_pipeline.get_params()
{'memory': None,
'steps': [('standardscaler', StandardScaler()), ('gaussiannb', GaussianNB())],
'verbose': False,
'standardscaler': StandardScaler(),
'gaussiannb': GaussianNB(),
'standardscaler__copy': True,
'standardscaler__with_mean': True,
'standardscaler__with_std': True,
'gaussiannb__priors': None,
'gaussiannb__var_smoothing': 1e-09}
model_pipeline = fit_pipeline.named_steps["gaussiannb"] # or pipeline.steps[1][1]model_pipeline.get_params()
{'priors': None, 'var_smoothing': 1e-09}
精度確認 (GaussianNB)
# https://scikit-learn.org/stable/modules/generated/sklearn.metrics.ConfusionMatrixDisplay.html
import matplotlib.pyplot as plt
from sklearn.datasets import make_classification
from sklearn.metrics import ConfusionMatrixDisplay
from sklearn.metrics import confusion_matrix
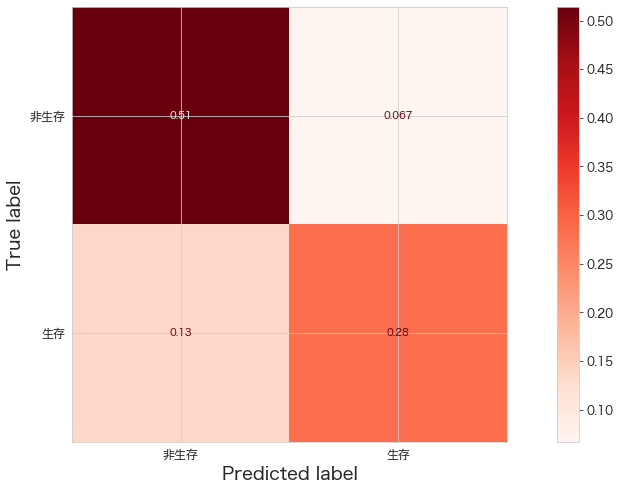
print(confusion_matrix(Y_test,fit_pipeline.predict(X_test)))
ConfusionMatrixDisplay.from_estimator(fit_pipeline,X_test,Y_test,cmap="Reds",display_labels=["非生存","生存"],normalize="all")
plt.show()[[92 12]
[24 51]]
Kaggleへ予測データをアップロード (GaussianNB)
df_eval["Survived"] = fit_pipeline.predict(df_eval[FEATURE_COLS])
df_eval[["PassengerId","Survived"]].to_csv("titanic_submission.csv",index=False)
!/Users/hinomaruc/Desktop/notebooks/my-venv/bin/kaggle competitions submit -c titanic -f titanic_submission.csv -m "model #006. gaussiannb (normalized)"
100%|████████████████████████████████████████| 2.77k/2.77k [00:04<00:00, 598B/s]
Successfully submitted to Titanic - Machine Learning from Disaster
0.74641
まずまずな結果です。
ナイーブベイズ (ComplementNB)
モデル作成 (ComplementNB)
# https://scikit-learn.org/stable/modules/generated/sklearn.naive_bayes.ComplementNB.html
from sklearn.naive_bayes import ComplementNB
from sklearn.pipeline import make_pipeline
from sklearn.preprocessing import MinMaxScaler
pipeline = make_pipeline(MinMaxScaler(), ComplementNB())StandardScalerで標準化してfitしたら下記エラーが発生しました。
ValueError: Negative values in data passed to ComplementNB (input X)
そのため、0から1の範囲にスケールするMinMaxScalerを使用しました。
fit_pipeline = pipeline.fit(X_train,Y_train)# Return the mean accuracy on the given data and labels.
print("train",fit_pipeline.score(X_train,Y_train))
print("test",fit_pipeline.score(X_test,Y_test))
train 0.7443820224719101
test 0.776536312849162
# モデルパラメータ一覧
fit_pipeline.get_params()
{'memory': None,
'steps': [('minmaxscaler', MinMaxScaler()), ('complementnb', ComplementNB())],
'verbose': False,
'minmaxscaler': MinMaxScaler(),
'complementnb': ComplementNB(),
'minmaxscaler__clip': False,
'minmaxscaler__copy': True,
'minmaxscaler__feature_range': (0, 1),
'complementnb__alpha': 1.0,
'complementnb__class_prior': None,
'complementnb__fit_prior': True,
'complementnb__norm': False}
model_pipeline = fit_pipeline.named_steps["complementnb"] # or pipeline.steps[1][1]
model_pipeline.get_params()
{'alpha': 1.0, 'class_prior': None, 'fit_prior': True, 'norm': False}
精度確認 (ComplementNB)
# https://scikit-learn.org/stable/modules/generated/sklearn.metrics.ConfusionMatrixDisplay.html
import matplotlib.pyplot as plt
from sklearn.datasets import make_classification
from sklearn.metrics import ConfusionMatrixDisplay
from sklearn.metrics import confusion_matrix
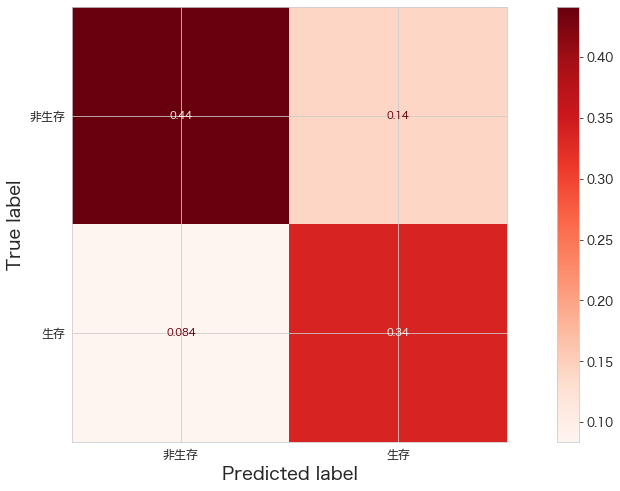
print(confusion_matrix(Y_test,fit_pipeline.predict(X_test)))
ConfusionMatrixDisplay.from_estimator(fit_pipeline,X_test,Y_test,cmap="Reds",display_labels=["非生存","生存"],normalize="all")
plt.show()[[79 25]
[15 60]]
Kaggleへ予測データをアップロード (ComplementNB)
df_eval["Survived"] = fit_pipeline.predict(df_eval[FEATURE_COLS])
df_eval[["PassengerId","Survived"]].to_csv("titanic_submission.csv",index=False)
!/Users/hinomaruc/Desktop/notebooks/my-venv/bin/kaggle competitions submit -c titanic -f titanic_submission.csv -m "model #006. complementnb (normalized)"
100%|████████████████████████████████████████| 2.77k/2.77k [00:05<00:00, 505B/s]
Successfully submitted to Titanic - Machine Learning from Disaster
0.70574
結構下がってしまいました。
ナイーブベイズ (CategoricalNB)
モデル作成 (CategoricalNB)
# https://scikit-learn.org/stable/modules/generated/sklearn.naive_bayes.CategoricalNB.html
from sklearn.naive_bayes import CategoricalNB
from sklearn.pipeline import make_pipeline
from sklearn.preprocessing import MinMaxScaler
pipeline = make_pipeline(MinMaxScaler(), CategoricalNB())StandardScalerで標準化してfitしたら下記エラーが発生しました。
ValueError: Negative values in data passed to CategoricalNB (input X)
そのため、0から1の範囲にスケールするMinMaxScalerを使用しました。
fit_pipeline = pipeline.fit(X_train,Y_train)# Return the mean accuracy on the given data and labels.
print("train",fit_pipeline.score(X_train,Y_train))
print("test",fit_pipeline.score(X_test,Y_test))
train 0.8019662921348315
test 0.7988826815642458
# モデルパラメータ一覧
fit_pipeline.get_params()
{'memory': None,
'steps': [('minmaxscaler', MinMaxScaler()),
('categoricalnb', CategoricalNB())],
'verbose': False,
'minmaxscaler': MinMaxScaler(),
'categoricalnb': CategoricalNB(),
'minmaxscaler__clip': False,
'minmaxscaler__copy': True,
'minmaxscaler__feature_range': (0, 1),
'categoricalnb__alpha': 1.0,
'categoricalnb__class_prior': None,
'categoricalnb__fit_prior': True,
'categoricalnb__min_categories': None}
model_pipeline = fit_pipeline.named_steps["categoricalnb"] # or pipeline.steps[1][1]
model_pipeline.get_params()
{'alpha': 1.0, 'class_prior': None, 'fit_prior': True, 'min_categories': None}
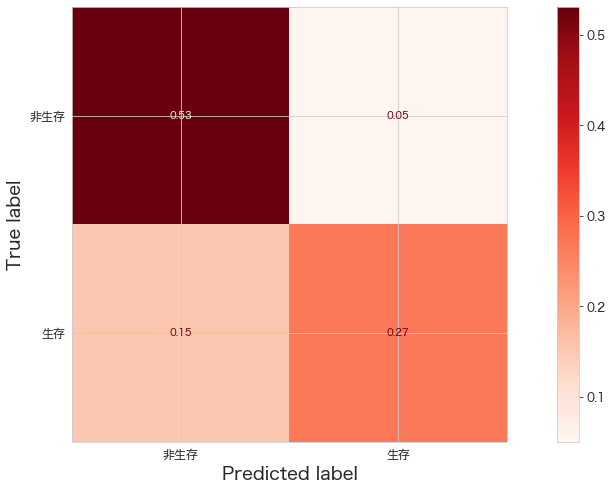
精度確認 (CategoricalNB)
# https://scikit-learn.org/stable/modules/generated/sklearn.metrics.ConfusionMatrixDisplay.html
import matplotlib.pyplot as plt
from sklearn.datasets import make_classification
from sklearn.metrics import ConfusionMatrixDisplay
from sklearn.metrics import confusion_matrix
print(confusion_matrix(Y_test,fit_pipeline.predict(X_test)))
ConfusionMatrixDisplay.from_estimator(fit_pipeline,X_test,Y_test,cmap="Reds",display_labels=["非生存","生存"],normalize="all")
plt.show()[[95 9]
[27 48]]
Kaggleへ予測データをアップロード (CategoricalNB)
df_eval["Survived"] = fit_pipeline.predict(df_eval[FEATURE_COLS])
df_eval[["PassengerId","Survived"]].to_csv("titanic_submission.csv",index=False)
!/Users/hinomaruc/Desktop/notebooks/my-venv/bin/kaggle competitions submit -c titanic -f titanic_submission.csv -m "model #006. CategoricalNB (minmax scaled)"
100%|████████████████████████████████████████| 2.77k/2.77k [00:06<00:00, 457B/s]
Successfully submitted to Titanic - Machine Learning from Disaster
0.76315
現時点の暫定1位の精度が76.7%なので、かなり近いです。
デフォルトの設定でこの精度はかなりいい線をいってるのでないでしょうか。
ナイーブベイズ (MultinomialNB)
モデル作成 (MultinomialNB)
# https://scikit-learn.org/stable/modules/generated/sklearn.naive_bayes.MultinomialNB.html
from sklearn.naive_bayes import MultinomialNB
from sklearn.pipeline import make_pipeline
from sklearn.preprocessing import MinMaxScaler
pipeline = make_pipeline(MinMaxScaler(), MultinomialNB())StandardScalerで標準化してfitしたら下記エラーが発生しました。
ValueError: Negative values in data passed to CategoricalNB (input X)
そのため、0から1の範囲にスケールするMinMaxScalerを使用しました。
fit_pipeline = pipeline.fit(X_train,Y_train)# Return the mean accuracy on the given data and labels.
print("train",fit_pipeline.score(X_train,Y_train))
print("test",fit_pipeline.score(X_test,Y_test))
train 0.7865168539325843
test 0.770949720670391
# モデルパラメータ一覧
fit_pipeline.get_params()
{'memory': None,
'steps': [('minmaxscaler', MinMaxScaler()),
('multinomialnb', MultinomialNB())],
'verbose': False,
'minmaxscaler': MinMaxScaler(),
'multinomialnb': MultinomialNB(),
'minmaxscaler__clip': False,
'minmaxscaler__copy': True,
'minmaxscaler__feature_range': (0, 1),
'multinomialnb__alpha': 1.0,
'multinomialnb__class_prior': None,
'multinomialnb__fit_prior': True}
model_pipeline = fit_pipeline.named_steps["multinomialnb"] # or pipeline.steps[1][1]
model_pipeline.get_params()
{'alpha': 1.0, 'class_prior': None, 'fit_prior': True}
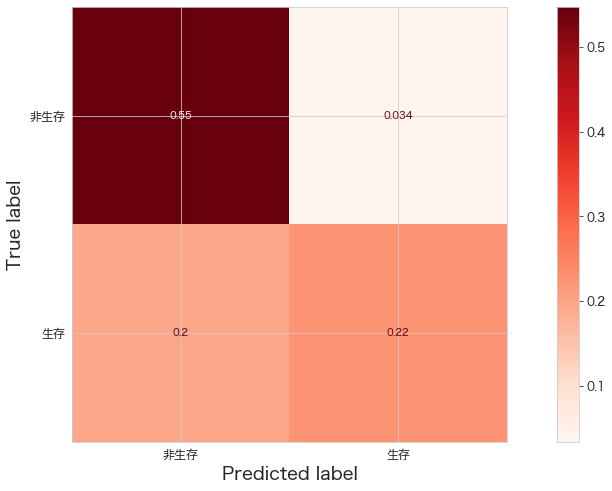
精度確認 (MultinomialNB)
# https://scikit-learn.org/stable/modules/generated/sklearn.metrics.ConfusionMatrixDisplay.html
import matplotlib.pyplot as plt
from sklearn.datasets import make_classification
from sklearn.metrics import ConfusionMatrixDisplay
from sklearn.metrics import confusion_matrix
print(confusion_matrix(Y_test,fit_pipeline.predict(X_test)))
ConfusionMatrixDisplay.from_estimator(fit_pipeline,X_test,Y_test,cmap="Reds",display_labels=["非生存","生存"],normalize="all")
plt.show()[[98 6]
[35 40]]
Kaggleへ予測データをアップロード (MultinomialNB)
df_eval["Survived"] = fit_pipeline.predict(df_eval[FEATURE_COLS])
df_eval[["PassengerId","Survived"]].to_csv("titanic_submission.csv",index=False)
!/Users/hinomaruc/Desktop/notebooks/my-venv/bin/kaggle competitions submit -c titanic -f titanic_submission.csv -m "model #006. multinomialnb (minmax scaled)"
100%|████████████████████████████████████████| 2.77k/2.77k [00:04<00:00, 591B/s]
Successfully submitted to Titanic - Machine Learning from Disaster
0.75598
ナイーブベイズ (BernoulliNB)
モデル作成 (BernoulliNB)
# https://scikit-learn.org/stable/modules/generated/sklearn.naive_bayes.GaussianNB.html
from sklearn.naive_bayes import BernoulliNB
from sklearn.pipeline import make_pipeline
from sklearn.preprocessing import StandardScaler
pipeline = make_pipeline(StandardScaler(), BernoulliNB())fit_pipeline = pipeline.fit(X_train,Y_train)# Return the mean accuracy on the given data and labels.
print("train",fit_pipeline.score(X_train,Y_train))
print("test",fit_pipeline.score(X_test,Y_test))
train 0.7485955056179775
test 0.7374301675977654
# モデルパラメータ一覧
fit_pipeline.get_params()
{'memory': None,
'steps': [('standardscaler', StandardScaler()),
('bernoullinb', BernoulliNB())],
'verbose': False,
'standardscaler': StandardScaler(),
'bernoullinb': BernoulliNB(),
'standardscaler__copy': True,
'standardscaler__with_mean': True,
'standardscaler__with_std': True,
'bernoullinb__alpha': 1.0,
'bernoullinb__binarize': 0.0,
'bernoullinb__class_prior': None,
'bernoullinb__fit_prior': True}
model_pipeline = fit_pipeline.named_steps["bernoullinb"] # or pipeline.steps[1][1]
model_pipeline.get_params()
{'alpha': 1.0, 'binarize': 0.0, 'class_prior': None, 'fit_prior': True}
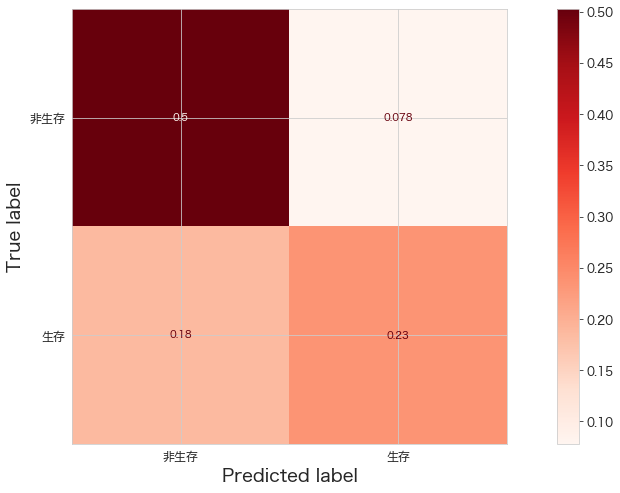
精度確認 (BernoulliNB)
# https://scikit-learn.org/stable/modules/generated/sklearn.metrics.ConfusionMatrixDisplay.html
import matplotlib.pyplot as plt
from sklearn.datasets import make_classification
from sklearn.metrics import ConfusionMatrixDisplay
from sklearn.metrics import confusion_matrix
print(confusion_matrix(Y_test,fit_pipeline.predict(X_test)))
ConfusionMatrixDisplay.from_estimator(fit_pipeline,X_test,Y_test,cmap="Reds",display_labels=["非生存","生存"],normalize="all")
plt.show()[[90 14]
[33 42]]
Kaggleへ予測データをアップロード (BernoulliNB)
df_eval["Survived"] = fit_pipeline.predict(df_eval[FEATURE_COLS])
df_eval[["PassengerId","Survived"]].to_csv("titanic_submission.csv",index=False)
!/Users/hinomaruc/Desktop/notebooks/my-venv/bin/kaggle competitions submit -c titanic -f titanic_submission.csv -m "model #006. bernoullinb (normalized)"
100%|████████████████████████████████████████| 2.77k/2.77k [00:03<00:00, 729B/s]
400 - Bad Request
0.72248
まとめ
ベイズはよく業務で使いますが、ナイーブベイズにも色々名称が付いていたのは知らなかったです 笑
