前回の記事ではタイタニックのデータセットでのデータ加工案をまとめていました。
今回は 1. 欠損値処理 (missing value processing)の作業をしようと思います。
Embarkedは最頻値で補完し、Ageは回帰モデルで欠損値を推定しようと思います。
またAgeは中央値で補完する方法と回帰モデルで推定する方法のどちらの方が精度が良さそうか検証もします。
それでは、欠損値処理をしていきたいと思います。
必要なライブラリのインストール
まずは追加でインストールが必要なライブラリをインストールしておきます。
もうすでにインストール済みである場合は必要ありません。
sklearnのインストール
機械学習ライブラリであるsklearnをインストールします。
$ /Users/hinomaruc/Desktop/notebooks/my-venv/bin/python3 -m pip install sklearn
Collecting sklearn
Downloading sklearn-0.0.tar.gz (1.1 kB)
Preparing metadata (setup.py) ... done
Collecting scikit-learn
Downloading scikit_learn-1.0.2-cp39-cp39-macosx_10_13_x86_64.whl (8.0 MB)
━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━ 8.0/8.0 MB 6.6 MB/s eta 0:00:00
・・・省略・・・
Successfully installed joblib-1.1.0 scikit-learn-1.0.2 sklearn-0.0 threadpoolctl-3.1.0
XGBoostのインストール
欠損値推定モデル作成のためにインストールします。
$ /Users/hinomaruc/Desktop/notebooks/my-venv/bin/python3 -m pip install xgboost
Collecting xgboost
Downloading xgboost-1.5.2.tar.gz (730 kB)
━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━ 730.1/730.1 KB 2.5 MB/s eta 0:00:00
Preparing metadata (setup.py) ... done
Requirement already satisfied: numpy in ./Desktop/notebooks/my-venv/lib/python3.9/site-packages (from xgboost) (1.22.1)
Requirement already satisfied: scipy in ./Desktop/notebooks/my-venv/lib/python3.9/site-packages (from xgboost) (1.8.0)
Using legacy 'setup.py install' for xgboost, since package 'wheel' is not installed.
Installing collected packages: xgboost
Running setup.py install for xgboost ... done
Successfully installed xgboost-1.5.2
データの読み込みと欠損値割合の確認
import pandas as pd
import numpy as np
# タイタニックデータセットの訓練データを読み込み
df = pd.read_csv("/Users/hinomaruc/Desktop/notebooks/titanic/train.csv")# 欠損値割合の確認
chk_null = df.isnull().sum()
chk_null_pct = chk_null / (df.index.max() + 1)
chk_null_tbl = pd.concat([chk_null[chk_null > 0], chk_null_pct[chk_null_pct > 0]], axis=1)
chk_null_tbl.rename(columns={0: "欠損レコード数",1: "欠損割合(missing rows / all rows)"})
欠損レコード数 欠損割合(missing rows / all rows) Age 177 0.198653 Cabin 687 0.771044 Embarked 2 0.002245
以前の記事で確認したことがありますが、再確認しました。
Emparkedは2レコード欠損、Ageは177レコード欠損しています。
Embarkedの欠損値処理
# https://scikit-learn.org/stable/modules/generated/sklearn.impute.SimpleImputer.html
from sklearn.impute import SimpleImputer
# missing_values = int, float, str, np.nan or None
imp = SimpleImputer(missing_values=np.nan, strategy="most_frequent")
imp.fit(np.array(df.loc[:,"Embarked"]).reshape(-1,1))SimpleImputer(strategy='most_frequent')
SimpleImputerというsklearnで実装されているクラスの一つを使いました。
今回はmost_frequent(最頻値)を使いましたが、他にもmean(平均値),median(中央値),constant(固定値)も利用できます。
fitメソッドでEmbarkedの最頻値を求めてくれます。
df["Embarked_fillna"] = imp.transform(np.array(df.loc[:,"Embarked"]).reshape(-1,1))transformメソッドで欠損値に推定値が代入されます。
ちなみに、fitのときに学習させた変数の数とtransformに投入する変数の数が合っていないと、下記エラーになります。
ValueError: X has 1 features, but SimpleImputer is expecting 13 features as input.
# 代入結果の確認
df[["Embarked","Embarked_fillna"]].loc[df.Embarked.isnull()]
Embarked Embarked_fillna 61 NaN S 829 NaN S
推定値はSになった。簡単。1カラムだけだとメリットはあまり感じないかもしれないが、複数カラムを指定すればすべて最頻値で欠損値処理してくれる。
Ageの欠損値処理
Ageカラムの予測モデル作成
Ageを目的変数とした予測モデルを作成します。
モデリング用データ作成 (訓練データ)
OneHotEncoderでPclass、Sex、Embarked(欠損値処理済み)を0/1のカラムに変換します。
# https://scikit-learn.org/stable/modules/generated/sklearn.preprocessing.OneHotEncoder.html
from sklearn.preprocessing import OneHotEncoder
enc = OneHotEncoder(categories='auto',handle_unknown='ignore') #エラーは0になるオプションPclassのダミー変数を作成するため、str型に変換します。
df['Pclass_str'] = df['Pclass'].apply(str)fitします。
enc.fit(df[['Pclass_str','Sex','Embarked_fillna']])OneHotEncoder(handle_unknown='ignore')
# fitしたカラムのカテゴリ値を確認
enc.categories_[array(['1', '2', '3'], dtype=object), array(['female', 'male'], dtype=object), array(['C', 'Q', 'S'], dtype=object)]
# transformメソッドで0/1のダミー変数に変換確認
enc.transform(df[['Pclass_str','Sex','Embarked_fillna']]).toarray()
array([[0., 0., 1., ..., 0., 0., 1.],
[1., 0., 0., ..., 1., 0., 0.],
[0., 0., 1., ..., 0., 0., 1.],
...,
[0., 0., 1., ..., 0., 0., 1.],
[1., 0., 0., ..., 1., 0., 0.],
[0., 0., 1., ..., 0., 1., 0.]])
# 作成されるダミー変数名の確認
enc.get_feature_names_out(['Pclass_str','Sex','Embarked_fillna'])
array(['Pclass_str_1', 'Pclass_str_2', 'Pclass_str_3', 'Sex_female',
'Sex_male', 'Embarked_fillna_C', 'Embarked_fillna_Q',
'Embarked_fillna_S'], dtype=object)
# OneHotEncoderでダミー化した変数をDataFrameに追加
cols=enc.get_feature_names_out(['Pclass_str','Sex','Embarked_fillna'])
df_train = df.join(pd.DataFrame(enc.transform(df[['Pclass_str','Sex','Embarked_fillna']]).toarray(),columns=cols))# データに欠損値が含まれてるとモデル作成時にエラーなどになるので対象レコードは削除する。
df_train = df_train.dropna(subset=['Age'])# 中身の確認
df_train.head()
PassengerId Survived Pclass Name Sex Age SibSp Parch Ticket Fare ... Embarked_fillna Pclass_str Pclass_str_1 Pclass_str_2 Pclass_str_3 Sex_female Sex_male Embarked_fillna_C Embarked_fillna_Q Embarked_fillna_S 0 1 0 3 Braund, Mr. Owen Harris male 22.0 1 0 A/5 21171 7.2500 ... S 3 0.0 0.0 1.0 0.0 1.0 0.0 0.0 1.0 1 2 1 1 Cumings, Mrs. John Bradley (Florence Briggs Th... female 38.0 1 0 PC 17599 71.2833 ... C 1 1.0 0.0 0.0 1.0 0.0 1.0 0.0 0.0 2 3 1 3 Heikkinen, Miss. Laina female 26.0 0 0 STON/O2. 3101282 7.9250 ... S 3 0.0 0.0 1.0 1.0 0.0 0.0 0.0 1.0 3 4 1 1 Futrelle, Mrs. Jacques Heath (Lily May Peel) female 35.0 1 0 113803 53.1000 ... S 1 1.0 0.0 0.0 1.0 0.0 0.0 0.0 1.0 4 5 0 3 Allen, Mr. William Henry male 35.0 0 0 373450 8.0500 ... S 3 0.0 0.0 1.0 0.0 1.0 0.0 0.0 1.0 5 rows × 22 columns
モデリング用データ作成 (テストデータ)
# テストデータの読み込み
df_test = pd.read_csv("/Users/hinomaruc/Desktop/notebooks/titanic/test.csv")# テストデータの欠損値割合の確認
chk_null_test = df_test.isnull().sum()
chk_null_pct_test = chk_null_test / (df_test.index.max() + 1)
chk_null_tbl_test = pd.concat([chk_null_test[chk_null_test > 0], chk_null_pct_test[chk_null_pct_test > 0]], axis=1)
chk_null_tbl_test.rename(columns={0: "欠損レコード数",1: "欠損割合(missing rows / all rows)"})
欠損レコード数 欠損割合(missing rows / all rows) Age 86 0.205742 Fare 1 0.002392 Cabin 327 0.782297
Age,Fare,Cabinに欠損があるようです。
# Pclassのダミー変数を作成するため、str型に変換します。
df_test['Pclass_str'] = df_test['Pclass'].apply(str)# 学習データと同じカラム名にするため、EmbarkedからEmbarked_fillnaカラムを作成する。
df_test["Embarked_fillna"] = df_test["Embarked"]# 学習データ作成時に使ったSimpleImputer(enc)を再利用する。
df_test = df_test.join(pd.DataFrame(enc.transform(df_test[['Pclass_str','Sex','Embarked_fillna']]).toarray(),columns=cols))# 欠損値が含まれるレコードを除外。Cabinは使用しないので、そのままにしておく。
df_test = df_test.dropna(subset=['Age', 'Fare'])# テストデータの欠損値割合の確認
chk_null_test = df_test.isnull().sum()
chk_null_pct_test = chk_null_test / (df_test.index.max() + 1)
chk_null_tbl_test = pd.concat([chk_null_test[chk_null_test > 0], chk_null_pct_test[chk_null_pct_test > 0]], axis=1)
chk_null_tbl_test.rename(columns={0: "欠損レコード数",1: "欠損割合(missing rows / all rows)"})
欠損レコード数 欠損割合(missing rows / all rows) Cabin 244 0.586538
欠損があるカラムはCabinだけになりました。
xgboostでAgeの予測モデルを作成する
# カラムを確認
df_train.columns
Index(['PassengerId', 'Survived', 'Pclass', 'Name', 'Sex', 'Age', 'SibSp',
'Parch', 'Ticket', 'Fare', 'Cabin', 'Embarked', 'Embarked_fillna',
'Pclass_str', 'Pclass_str_1', 'Pclass_str_2', 'Pclass_str_3',
'Sex_female', 'Sex_male', 'Embarked_fillna_C', 'Embarked_fillna_Q',
'Embarked_fillna_S'],
dtype='object')
FEATURE_COLS=[
# 'PassengerId'
# , 'Survived'
# , 'Pclass'
# , 'Name'
# , 'Sex'
# 'Age'
'SibSp'
, 'Parch'
# , 'Ticket'
, 'Fare'
# , 'Cabin'
# , 'Embarked'
# , 'Embarked_fillna'
# , 'Pclass_str'
, 'Pclass_str_1'
, 'Pclass_str_2'
, 'Pclass_str_3'
, 'Sex_female'
, 'Sex_male'
, 'Embarked_fillna_C'
, 'Embarked_fillna_Q'
, 'Embarked_fillna_S'
]
X_train = df_train[FEATURE_COLS] # 説明変数 (train)
Y_train = df_train["Age"] # 目的変数 (train)
X_test = df_test[FEATURE_COLS] # 説明変数 (test)
Y_test = df_test["Age"] # 目的変数 (test)# 自由度調整済みr2を算出
def adjusted_r2(X,Y,model):
from sklearn.metrics import r2_score
import numpy as np
r_squared = r2_score(Y, model.predict(X))
adjusted_r2 = 1 - (1-r_squared)*(len(Y)-1)/(len(Y)-X.shape[1]-1)
return adjusted_r2# モデル評価指標算出
def get_model_evaluations(X_train,Y_train,X_test,Y_test,model):
from sklearn.metrics import explained_variance_score
from sklearn.metrics import mean_absolute_error
from sklearn.metrics import mean_squared_error
from sklearn.metrics import mean_squared_log_error
from sklearn.metrics import median_absolute_error
# 評価指標確認
# 参考: https://funatsu-lab.github.io/open-course-ware/basic-theory/accuracy-index/
yhat_test = model.predict(X_test)
return "adjusted_r2(train) :" + str(adjusted_r2(X_train,Y_train,model)) \
, "adjusted_r2(test) :" + str(adjusted_r2(X_test,Y_test,model)) \
, "平均誤差率(test) :" + str(np.mean(abs((yhat_test - Y_test) / yhat_test))) \
, "MAE(test) :" + str(mean_absolute_error(Y_test, yhat_test)) \
, "MedianAE(test) :" + str(median_absolute_error(Y_test, yhat_test)) \
, "RMSE(test) :" + str(np.sqrt(mean_squared_error(Y_test, yhat_test))) \
, "RMSE(test) / MAE(test) :" + str(np.sqrt(mean_squared_error(Y_test, yhat_test)) / mean_absolute_error(Y_test, yhat_test)) #better if result = 1.253# モデル作成
model = xgb.XGBRegressor(objective ='reg:squarederror')
# 学習
model.fit(X_train,Y_train)
# 精度確認
get_model_evaluations(X_train,Y_train,X_test,Y_test,model)
('adjusted_r2(train) :0.7286511966742983',
'adjusted_r2(test) :0.008018507221561166',
'平均誤差率(test) :0.8408683085418738',
'MAE(test) :10.399103224997795',
'MedianAE(test) :8.118385314941406',
'RMSE(test) :13.790914307875354',
'RMSE(test) / MAE(test) :1.3261638056177945')
r2を確認するとtrainデータへの当てはまり(0.72)はまぁまぁですが、testデータには全然当てはまっていない(0.008)ようです。
MAE(test)では10.39歳の誤差があり、平均誤差率は84%でした。
import seaborn as sns
# 描画設定
from matplotlib import rcParams
rcParams['xtick.labelsize'] = 12 # x軸のラベルのフォントサイズ
rcParams['ytick.labelsize'] = 12 # y軸のラベルのフォントサイズ
rcParams['figure.figsize'] = 18,8 # 画像サイズの変更(inch)
import matplotlib.pyplot as plt
from matplotlib import ticker
sns.set_style("whitegrid") # seabornのスタイルセットの一つ
sns.set_color_codes() # デフォルトカラー設定 (deepになってる)plt.figure()
ax = sns.regplot(x=Y_test, y=model.predict(X_test), fit_reg=False,color='#4F81BD')
ax.set_xlabel(u"Age")
ax.set_ylabel(u"(Predicted) Age")
ax.get_xaxis().set_major_formatter(ticker.FuncFormatter(lambda x, p: format(int(x), ',')))
ax.get_yaxis().set_major_formatter(ticker.FuncFormatter(lambda y, p: format(int(y), ',')))
ax.plot([0,10,20,30,40,50],[0,10,20,30,40,50], linewidth=2, color="#C0504D",ls="--")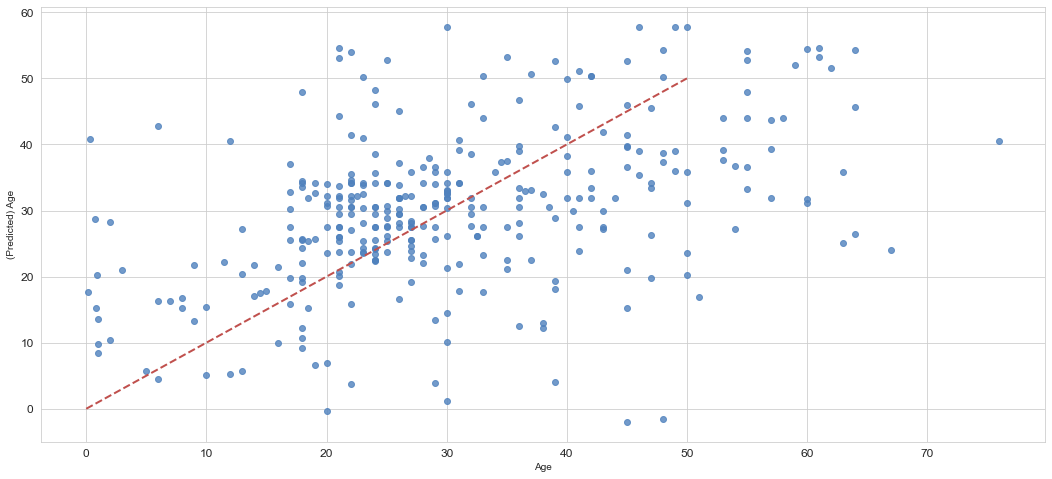
年齢がマイナス値で予測されていそうなものもありますね。マイナスは0にするなどという処理も必要かもしれません。
# xgboostが算出してくれた変数の重要度
xgb.plot_importance(model)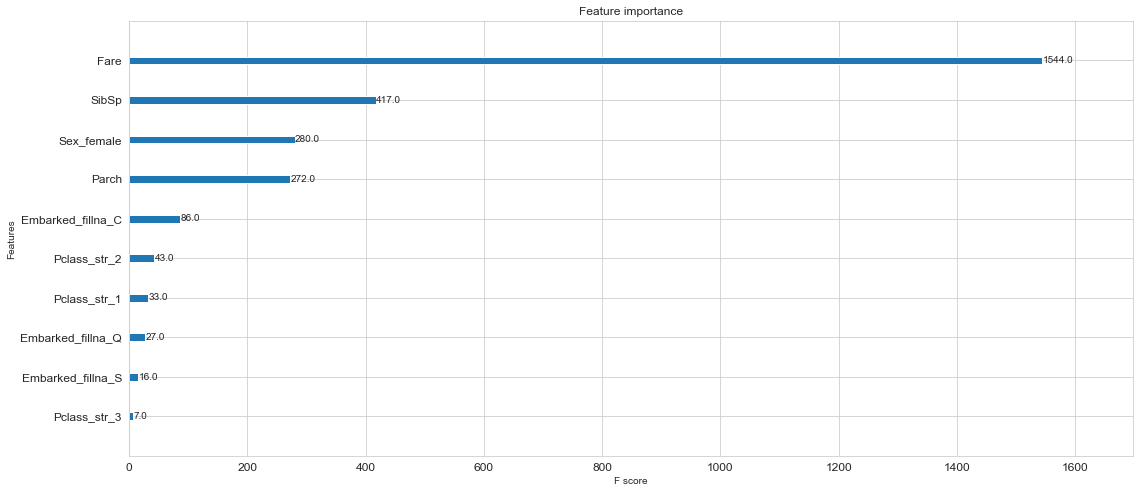
FareがAge予測するにあたり、一番重要度が高いようです。
xgboostでAgeの予測モデルを作成する (パラメータチューニングあり)
デフォルトの設定だとイマイチでしたので、GridSearchでパラメータのチューニングをして精度をあげようと思います。
from sklearn.model_selection import GridSearchCV
from sklearn.model_selection import KFold
# Grid Search用のパラメータ作成。
# あまり組み合わせが多いと時間がかかる
params = {
'eta': [0.2,0.3,0.4], # default = 0.3
'gamma': [0,1,2,3], # default = 0
'max_depth': [3,4,5,6,7,8,9], # default = 6
'min_child_weight': [1], # default = 1
'subsample': [0.1,0.5,0.8,1.0], # default = 1
'colsample_bytree': [0,1,0.5,0.8,1.0], # default = 1
}
# K-分割交差検証を使い、overfitting対策
kf = KFold(n_splits=5, shuffle = True, random_state = 1)
# モデル作成
model = xgb.XGBRegressor(objective ='reg:squarederror')
# GridSearch設定
grid = GridSearchCV(estimator=model, param_grid=params, scoring='neg_mean_squared_error', n_jobs=2, cv=kf.split(X_train,Y_train), verbose=3)# fitし学習させる。ヒノマルクの環境だと時間かかる。
grid.fit(X_train,Y_train)Fitting 5 folds for each of 1680 candidates, totalling 8400 fits [CV 2/5] END colsample_bytree=0, eta=0.2, gamma=0, max_depth=3, min_child_weight=1, subsample=0.1;, score=-171.535 total time= 0.1s [CV 3/5] END colsample_bytree=0, eta=0.2, gamma=0, max_depth=3, min_child_weight=1, subsample=0.1;, score=-181.272 total time= 0.1s [CV 1/5] END colsample_bytree=0, eta=0.2, gamma=0, max_depth=3, min_child_weight=1, subsample=0.5;, score=-152.707 total time= 0.1s ・・・省略・・・ [CV 5/5] END colsample_bytree=1.0, eta=0.4, gamma=2, max_depth=7, min_child_weight=1, subsample=1.0;, score=-172.000 total time= 0.2s [CV 5/5] END colsample_bytree=1.0, eta=0.4, gamma=2, max_depth=8, min_child_weight=1, subsample=0.1;, score=-205.571 total time= 0.2s [CV 1/5] END colsample_bytree=1.0, eta=0.4, gamma=2, max_depth=8, min_child_weight=1, subsample=0.5;, score=-225.756 total time= 0.4s GridSearchCV(cv=, estimator=XGBRegressor(base_score=None, booster=None, colsample_bylevel=None, colsample_bynode=None, colsample_bytree=None, enable_categorical=False, gamma=None, gpu_id=None, importance_type=None, interaction_constraints=None, learning_rate=None, max_delta_step=None, max_depth=None, min_child_weight... random_state=None, reg_alpha=None, reg_lambda=None, scale_pos_weight=None, subsample=None, tree_method=None, validate_parameters=None, verbosity=None), n_jobs=2, param_grid={'colsample_bytree': [0, 1, 0.5, 0.8, 1.0], 'eta': [0.2, 0.3, 0.4], 'gamma': [0, 1, 2, 3], 'max_depth': [3, 4, 5, 6, 7, 8, 9], 'min_child_weight': [1], 'subsample': [0.1, 0.5, 0.8, 1.0]}, scoring='neg_mean_squared_error', verbose=3)
print('ベストスコア:',grid.best_score_, sep="\n")
print('\n')
print('ベストestimator:',grid.best_estimator_,sep="\n")
print('\n')
print('ベストparams:',grid.best_params_,sep="\n")
ベストスコア:
-159.2734298880375
ベストestimator:
XGBRegressor(base_score=0.5, booster='gbtree', colsample_bylevel=1,
colsample_bynode=1, colsample_bytree=0, enable_categorical=False,
eta=0.2, gamma=3, gpu_id=-1, importance_type=None,
interaction_constraints='', learning_rate=0.200000003,
max_delta_step=0, max_depth=3, min_child_weight=1, missing=nan,
monotone_constraints='()', n_estimators=100, n_jobs=1,
num_parallel_tree=1, predictor='auto', random_state=0, reg_alpha=0,
reg_lambda=1, scale_pos_weight=1, subsample=0.8,
tree_method='exact', validate_parameters=1, verbosity=None)
ベストparams:
{'colsample_bytree': 0, 'eta': 0.2, 'gamma': 3, 'max_depth': 3, 'min_child_weight': 1, 'subsample': 0.8}
# Grid Searchで一番精度が良かったモデル
bestmodel = grid.best_estimator_このモデルをpicleなどで保存しておくといいかもしれません。(また1から学習し直すのは大変なので)
# 精度確認
get_model_evaluations(X_train,Y_train,X_test,Y_test,bestmodel)
('adjusted_r2(train) :0.3315393229940612',
'adjusted_r2(test) :0.24952270465898052',
'平均誤差率(test) :0.3497748605577836',
'MAE(test) :9.478654452321033',
'MedianAE(test) :7.799215316772461',
'RMSE(test) :11.995270720473913',
'RMSE(test) / MAE(test) :1.2655035354239164')
r2trainとr2testの差があまりなさそうなので、overfittingは避けることができました。
MAEや平均誤差率の値もよくなりました。
plt.figure()
ax = sns.regplot(x=Y_test, y=bestmodel.predict(X_test), fit_reg=False,color='#4F81BD')
ax.set_xlabel(u"Age")
ax.set_ylabel(u"(Predicted) Age")
ax.get_xaxis().set_major_formatter(ticker.FuncFormatter(lambda x, p: format(int(x), ',')))
ax.get_yaxis().set_major_formatter(ticker.FuncFormatter(lambda y, p: format(int(y), ',')))
ax.plot([0,10,20,30,40,50],[0,10,20,30,40,50], linewidth=2, color="#C0504D",ls="--")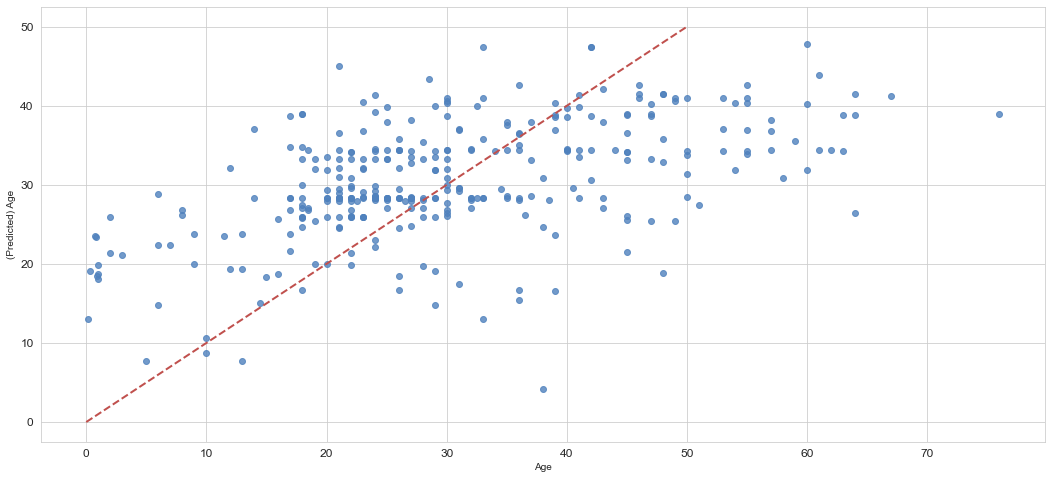
前のモデルより若干線形になったような気がする?
medianのみで代入した場合とxgboostで予測し代入する場合とでどちらが精度がよいのか
予測モデルを作成して欠損値処理をしてあげる場合と、単純に特定条件の中央値を代入してあげる場合とでどちらが精度がよい推定が出来るのか確認。
訓練データを①trainデータと②testデータに分割し、②testデータのAgeを予測もしくは中央値で代入した値と実際の値で精度を確認してみようと思います。
パターン1: Age予測モデル作成
# 訓練データ(df_train)をさらにtrainとtestデータに分割する。
from sklearn.model_selection import train_test_split
train, test = train_test_split(df_train, test_size=0.20,random_state=100)X_train = train[FEATURE_COLS] # 説明変数 (train)
Y_train = train["Age"] # 目的変数 (train)
X_test = test[FEATURE_COLS] # 説明変数 (test)
Y_test = test["Age"] # 目的変数 (test)# xgboostの結果 (GridSearchで作成したモデルを使います)
get_model_evaluations(X_train,Y_train,X_test,Y_test,bestmodel)
('adjusted_r2(train) :0.3159517735183577',
'adjusted_r2(test) :0.34198324621634624',
'平均誤差率(test) :0.3153205018656609',
'MAE(test) :8.65396466235181',
'MedianAE(test) :7.120338439941406',
'RMSE(test) :11.22234801467108',
'RMSE(test) / MAE(test) :1.2967869008632265')
plt.figure()
ax = sns.regplot(x=Y_test, y=bestmodel.predict(X_test), fit_reg=False,color='#4F81BD')
ax.set_xlabel(u"Age")
ax.set_ylabel(u"(Predicted) Age")
ax.get_xaxis().set_major_formatter(ticker.FuncFormatter(lambda x, p: format(int(x), ',')))
ax.get_yaxis().set_major_formatter(ticker.FuncFormatter(lambda y, p: format(int(y), ',')))
ax.plot([0,10,20,30,40,50],[0,10,20,30,40,50], linewidth=2, color="#C0504D",ls="--")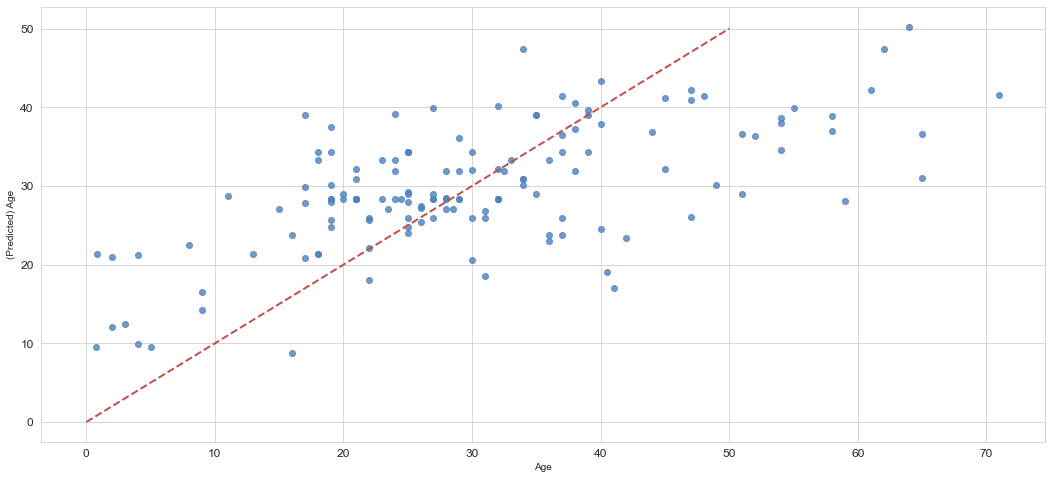
パターン2: 中央値で代入
①trainデータからmedianの値を取得し、②testデータは欠損値だったと見做してAgeを代入。実際の値と比較する。
# SexとPclassごとのAgeの中央値を算出
train.groupby(['Sex', 'Pclass'])['Age'].median()
Sex Pclass
female 1 35.0
2 29.0
3 21.0
male 1 38.0
2 30.5
3 25.0
Name: Age, dtype: float64
def set_age_median_val(row):
if (row.Sex == 'female') & (row.Pclass == 1):
return 35.0
elif (row.Sex == 'female') & (row.Pclass == 2):
return 29.0
elif (row.Sex == 'female') & (row.Pclass == 3):
return 21.0
elif (row.Sex == 'male') & (row.Pclass == 1):
return 38.0
elif (row.Sex == 'male') & (row.Pclass == 2):
return 30.5
elif (row.Sex == 'male') & (row.Pclass == 3):
return 25.0
else:
return 0# 中央値代入の関数を適用し、Age_medianカラムの作成
test["Age_median"] = test.apply(set_age_median_val, axis = 1)
# 今回は出番がありませんでしたが、同じDataFrame内で完結する場合は下記でAge_medianが作成できます。
#df_test['Age_median'] = df_test.groupby(['Sex', 'Pclass'])['Age'].transform('median')# 作成したデータの確認
test[["Age","Age_median"]]
Age Age_median 721 17.0 25.0 607 27.0 38.0 357 38.0 29.0 191 19.0 30.5 555 62.0 38.0 ... ... ... 3 35.0 35.0 265 36.0 30.5 801 31.0 29.0 577 39.0 35.0 343 25.0 30.5 143 rows × 2 columns
from sklearn.metrics import mean_absolute_error
from sklearn.metrics import median_absolute_error
"平均誤差率(test) :" + str(np.mean(abs((test["Age_median"] - test["Age"]) / test["Age_median"]))) \
, "MAE(test) :" + str(mean_absolute_error(test["Age"], test["Age_median"])) \
, "MedianAE(test) :" + str(median_absolute_error(test["Age"], test["Age_median"]))
('平均誤差率(test) :0.363867123821603',
'MAE(test) :10.051888111888113',
'MedianAE(test) :8.0')
そんなに悪くないです。MAEはxgboostのデフォルトパラメータの結果と同じくらいですね。
plt.figure()
ax = sns.regplot(x=test["Age"], y=test["Age_median"], fit_reg=False,color='#4F81BD')
ax.set_xlabel(u"Age")
ax.set_ylabel(u"Age_median")
ax.get_xaxis().set_major_formatter(ticker.FuncFormatter(lambda x, p: format(int(x), ',')))
ax.get_yaxis().set_major_formatter(ticker.FuncFormatter(lambda y, p: format(int(y), ',')))
ax.plot([0,10,20,30,40,50],[0,10,20,30,40,50], linewidth=2, color="#C0504D",ls="--")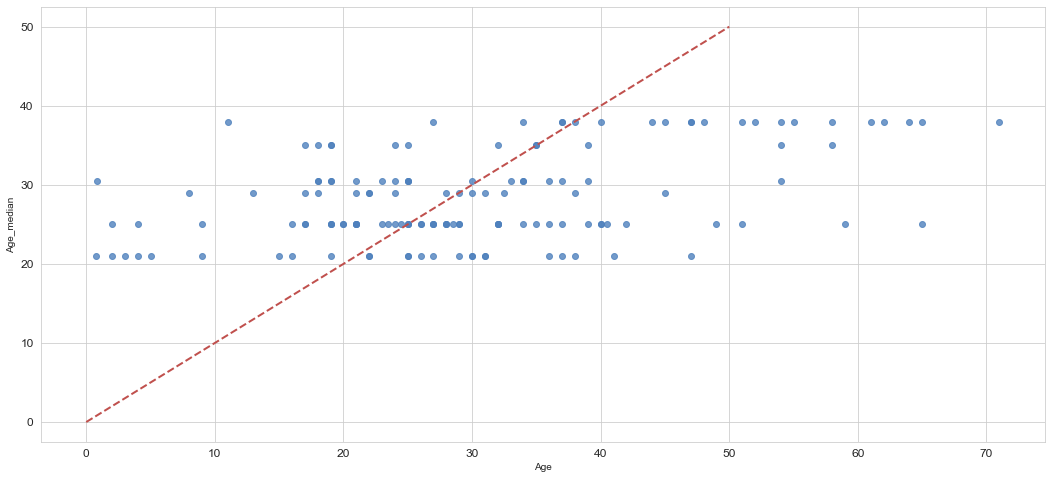
代入方法の特性上、線形の分布にはならないようです。
予測モデル作成と中央値代入の結果の比較
パターン1: Age予測モデル作成
'平均誤差率(test) :0.3153205018656609',
'MAE(test) :8.65396466235181',
'MedianAE(test) :7.120338439941406'
パターン2: 中央値で代入
'平均誤差率(test) :0.363867123821603',
'MAE(test) :10.051888111888113',
'MedianAE(test) :8.0'
予測モデルを使った方がより精度よく欠損値の補完が出来そうなことが分かりました。
ただ手間などを考えると中央値で代入でもまずはいいのかもしれません。
精度がシビアに問われる場合だと手間をかけてでも予測モデルを作成するというオプションがあるかもしれません。
まとめ
タイタニックの欠損値処理の方法をまとめてみました。
Embarkedは最頻値、Ageはxgboostで予測モデルを作成し欠損値を予測し補完してあげる方法が良さそうという結果になりました。
次は外れ値の処理・対応になります。
参考
https://www.geeksforgeeks.org/fastest-way-to-convert-integers-to-strings-in-pandas-dataframe/
https://stackoverflow.com/questions/40532303/pandas-groupby-and-correct-with-median-in-new-column
https://pandas.pydata.org/docs/reference/api/pandas.DataFrame.transform.html

