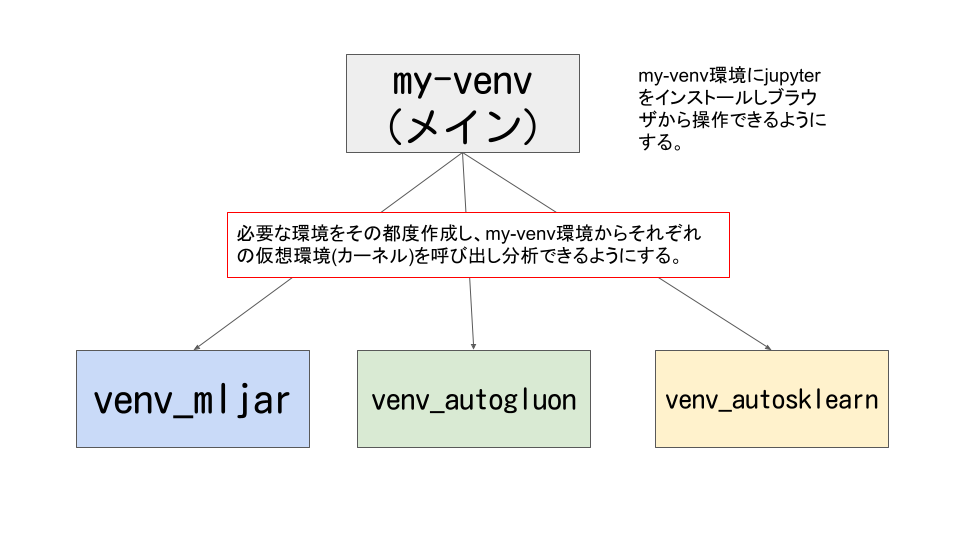
前回はAutoGluonの仮想環境を作成しました。
今回3つ目のauto-sklearnの環境を作成しようと思います。
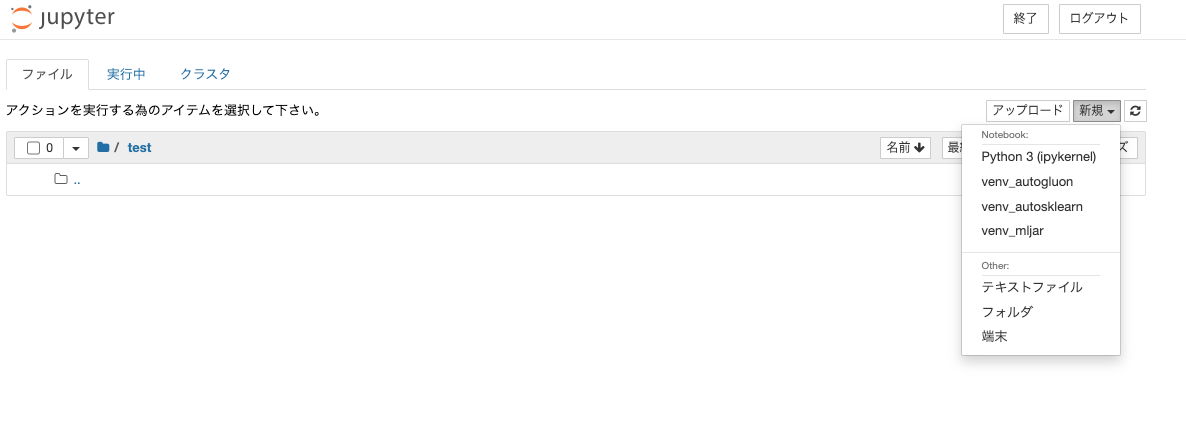
jupyterから確認すると最終的には下記のようにそれぞれのAutoML環境を選択可能になります。
sklearnと聞いたらご存知の方は多いかも知れませんが、AutoML版のsklearnのようです。
まずはAutoSklearnをインストールするにあたり、必須環境をみてみます。
Linux operating system (for example Ubuntu) (get Linux here)
Python (>=3.7) (get Python here),
C++ compiler (with C++11 supports) (get GCC here).
・OSはLinux (Ubuntuなど)
・Pythonは3.7以上
・C++コンパイラが必要
とのことです。Windowsでは動作せず、Macは動作するかどうか分からない(検証していない)ようです。
We currently do not know if auto-sklearn works on macOS. There are at least two issues holding us back from actively supporting macOS: 引用: https://automl.github.io/auto-sklearn/master/installation.html#installation
Macは動作するか分からないとのことですが、#155や#360のauto-sklearnのチケットでMacで動かすためのやり取りがされています。
本記事ではチケットに記載されているやり方でMacにインストール出来ることを確認しました。
auto-sklearnの仮想環境を作成する
gccとswigのインストール
事前にauto-sklearnとその依存ライブラリをインストールするために必要なコンパイラなどをインストールします。
# gccとswigのインストール
brew install gcc
brew install swigauto-sklearnの仮想環境作成
# venv-autosklearnという名前の仮想環境を作成
python3.8 -m venv venv-autosklearn
# activateし仮想環境内に入る
source venv-autosklearn/bin/activate
# pip、wheel,setuptoolsのインストールもしくはアップグレード
(venv-autosklearn) % python3 -m pip install pip wheel setuptools --upgradeauto-sklearnのインストール
# auto-sklearnのインストール
(venv-autosklearn) % python3 -m pip uninstall pyrfr auto-sklearn # 再インストールする前に実行
(venv-autosklearn) % curl https://raw.githubusercontent.com/automl/auto-sklearn/master/requirements.txt | xargs -n 1 -L 1 pip install
(venv-autosklearn) % env CC="/usr/bin/gcc -stdlib=libc++ -mmacosx-version-min=10.7" pip install auto-sklearn
(venv-autosklearn) % python3 -m pip install matplotlib seaborn # auto-sklearnで依存関係でインストールされないライブラリ (オプション)
Collecting pyrfr
Downloading pyrfr-0.8.2.tar.gz (296 kB)
━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━ 296.2/296.2 kB 11.2 MB/s eta 0:00:00
Preparing metadata (setup.py) ... done
Collecting auto-sklearn
Downloading auto-sklearn-0.14.7.tar.gz (6.4 MB)
━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━ 6.4/6.4 MB 14.8 MB/s eta 0:00:00
Preparing metadata (setup.py) ... done
・・・省略・・・
Successfully built pyrfr auto-sklearn smac
Installing collected packages: pyrfr, emcee, smac, auto-sklearn
Successfully installed auto-sklearn-0.14.7 emcee-3.1.2 pyrfr-0.8.2 smac-1.2
ipykernelをインストール
my-venvのjupyter notebookから今回作成したvenv_autogluonの仮想環境を呼び出せるようにします。
(venv-autosklearn) % python3 -m pip install ipykernel
(venv-autosklearn) % python3 -m ipykernel install --user --name venv_autosklearn --display-name "venv_autosklearn"Installed kernelspec venv_autosklearn in /Users/hinomaruc/Library/Jupyter/kernels/venv_autosklearn
エラー対応
pyrfrライブラリをインストールするときにエラー
error: command 'swig' failed: No such file or directory
→ brew install gcc swig で解決しました。
import autosklearn.regression したらエラー
ImportError: dlopen(/Users/hinomaruc/Desktop/blog/venv-autosklearn/lib/python3.8/site-packages/pyrfr/_regression.cpython-38-darwin.so, 2): Symbol not found: ZNSt7cxx1112basic_stringIcSt11char_traitsIcESaIcEED1Ev
→ pyrfrとautosklearnを再インストールしました。
auto-sklearnの動作確認
# 必要なライブラリをインポート
import pandas as pd
import numpy as np
from sklearn.model_selection import train_test_split
import autosklearn.regression# データセットをデータフレームに読み込む
df = pd.read_csv("http://lib.stat.cmu.edu/datasets/boston_corrected.txt", encoding='Windows-1252',skiprows=9,sep="\t")# モデリング用の説明変数
anacols=[
'CRIM' # 1人当たりの犯罪数
, 'ZN' # 町別の25,000平方フィート(7600m2)以上の住居区画の割合
, 'INDUS' #町別の非小売業が占める土地面積の割合
, 'CHAS' # チャールズ川沿いかどうか
, 'NOX' # 町別の窒素酸化物の濃度(1000万分の1)
, 'RM' # 住居の平均部屋数
, 'AGE' # 持ち家住宅比率
, 'DIS' # 5つのボストン雇用センターへの重み付き距離
, 'RAD' # 町別の環状高速道路へのアクセスのしやすさ
, 'TAX' # 町別の$10,000ドルあたりの固定資産税率
, 'PTRATIO' #町別の生徒と先生の比率
, 'B' # 1000*(黒人人口割合 - 0.63)^2
, 'LSTAT' # 貧困人口割合
]# Xとyの作成
X = df[anacols] # 説明変数
y = df["CMEDV"] # 目的変数# 訓練データとテストデータへ分割する
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=100)# auto-sklearnのautomlモデルを作成
automl = autosklearn.regression.AutoSklearnRegressor(
time_left_for_this_task=120,
per_run_time_limit=30,
tmp_folder='autosklearn_regression_example_tmp',
)
# fit
automl.fit(X_train, y_train, dataset_name='boston')
AutoSklearnRegressor(per_run_time_limit=30, time_left_for_this_task=120,
tmp_folder='autosklearn_regression_example_tmp')
# 作成したモデルの一覧
automl.leaderboard()
rank ensemble_weight type cost duration model_id 3 1 0.56 gaussian_process 0.135742 19.743288 7 2 0.44 extra_trees 0.143952 4.990713
# 作成したモデルの概要 (leaderboardより詳細が表示されるようです)
automl.show_models()
{3: {'model_id': 3,
'rank': 1,
'cost': 0.13574170835870003,
'ensemble_weight': 0.56,
'data_preprocessor': ,
'feature_preprocessor': ,
'regressor': ,
'sklearn_regressor': GaussianProcessRegressor(alpha=0.037731974209709904,
kernel=RBF(length_scale=[1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1]),
n_restarts_optimizer=10, normalize_y=True,
random_state=1)},
7: {'model_id': 7,
'rank': 2,
'cost': 0.14395180044569844,
'ensemble_weight': 0.44,
'data_preprocessor': ,
'feature_preprocessor': ,
'regressor': ,
'sklearn_regressor': ExtraTreesRegressor(criterion='mae', max_features=0.9029989558220115,
n_estimators=512, n_jobs=1, random_state=1,
warm_start=True)}}
# テストデータにモデルを適用し住宅価格の予測をする
prediction = automl.predict(X_test)# 予測結果と正解データの比較
from matplotlib import pyplot as plt
plt.plot(y_test, prediction,'.')
plt.xlabel("True value")
plt.ylabel("Predicted value")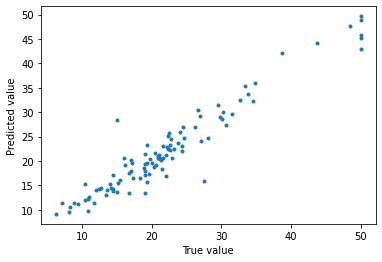
from sklearn.metrics import mean_absolute_error
from sklearn.metrics import mean_squared_error
print("MAE(test)", str(mean_absolute_error(y_test, prediction)))
print("RMSE(test)",str(np.sqrt(mean_squared_error(y_test, prediction))))
MAE(test) 1.9468150494145413
RMSE(test) 2.8329039607127253
xgboost(gridsearchあり)より精度は良いようです。
autogluonもよりもよく、mljarよりは悪いという結果になりました。
精度比較
xgboost (gridsearchあり)
旧ブログでボストンの住宅価格のデータセットで色々なモデルを試しました。その中でもxgboost(グリッドサーチあり)が一番精度がよかったのでautomlとの比較対象とします。
結果:
MAE(test) 2.07
RMSE(test) 2.89
auto-sklearn
結果:
MAE(test) 1.94
RMSE(test) 2.83
AutoGluon
結果:
MAE(test) 2.03
RMSE(test) 2.96
xgboost(grid searchあり)と比較して、MAEはAutoGluonの方がよくて、RMSEはxbgoost(grid searchあり)の方が良さそうです。
mljar
結果:
MAE(test): 1.81
RMSE(test) 2.76
mljarが一番精度が良いようです。
まとめ
やっとmljar,AutoGluon,auto-sklearnの環境をそれぞれ準備することが出来ました。
ボストンの住宅価格のデータセットではmljarが一番精度がよかったです。
簡単にすべて自動でやってくれてしかも精度がいいとなれば、使わずにはいられないですね。