
前回の記事ではロジスティック回帰で心臓病かどうかを当てるモデルを作成しました。
今回はKaggleのheart disease NN 98%というノートブックを参考にニューラルネットワークでモデルを作成してみようと思います。
ニューラルネットワークに関しては下記記事でまとめたことがあります。
- (その1) Pythonでニューラルネットワークを構築しながらディープラーニングを勉強してみる
- (その2) Pythonでニューラルネットワークを構築しながらディープラーニングを勉強してみる
- MNISTデータセットで手書き数字をニューラルネットワークで判別してみる
モデリング用データの準備
モデリング用データの準備
import pandas as pd
column_names = [
'age', 'sex', 'cp', 'trestbps', 'chol', 'fbs', 'restecg',
'thalach', 'exang', 'oldpeak', 'slope', 'ca', 'thal', 'num'
]
df = pd.read_csv("/Users/hinomaruc/Desktop/blog/dataset/heart+disease/processed.cleveland.data", header=None, names=column_names)
# 数値型でない行の値をNaNにする
df['ca'] = pd.to_numeric(df['ca'], errors='coerce')
df['thal'] = pd.to_numeric(df['thal'], errors='coerce')
# 欠損値処理
ca_median = df.dropna().groupby("num")["ca"].median()
thal_median = df.dropna().groupby("num")["thal"].median()
df['ca'] = df['ca'].fillna(df['num'].map(ca_median))
df['thal'] = df['thal'].fillna(df['num'].map(thal_median))
# 目的変数の作成
df['target'] = df['num'].apply(lambda x: 1 if x >= 1 else 0)
from sklearn.preprocessing import OneHotEncoder
# OneHotEncoderの定義 (各特徴量の最初の区分を落とす)
OneHotEnc = OneHotEncoder(categories='auto',drop='first',handle_unknown='ignore') #エラーは0になるオプション
# OneHotコンバート対象の変数
OneHotCols=["cp","restecg","slope","thal"]
# fit_transformして、ダミー変数の作成
get_dummies = OneHotEnc.fit_transform(df[OneHotCols])
# ダミー変数名取得
dummy_cols = OneHotEnc.get_feature_names_out()
# 元のデータフレームにダミー変数を追加する
df = df.join(pd.DataFrame(get_dummies.toarray(),columns=dummy_cols))
# ダミー化した変数を除外
df = df.drop(columns=OneHotCols)
df = df.drop(columns=["num"])
# 訓練データとテストデータに分割する。
from sklearn.model_selection import train_test_split
train, test = train_test_split(df, test_size=0.20,random_state=100)
X_train = train.drop(columns=["target"]) # 説明変数 (train)
y_train = train["target"] # 目的変数 (train)
X_test = test.drop(columns=["target"]) # 説明変数 (test)
y_test = test["target"] # 目的変数 (test)
#シェイプの確認
print(X_train.shape)
print(y_train.shape)
print(X_test.shape)
print(y_test.shape)Out[0]
(242, 18) (242,) (61, 18) (61,)
訓練用データが242レコード、テスト用データが61レコードあります。
ニューラルネットワークモデルの定義と学習
分かりづらいので説明を追加しました。
- Sequential: 層を順番に追加するためのモデルタイプです。
- Dense: 全結合(密結合)層を表します。最初の層は入力データの特徴量が18であることを指定しています(input_dim=18)。説明変数の数と合わせました。
- activation='relu': 隠れ層で使用される活性化関数はRectified Linear Unit(ReLU)であり、ディープラーニングモデルの隠れ層に一般的に用いられます。
- activation='softmax': 出力層で使用される活性化関数はSoftmaxです。Softmaxは2つの出力ユニットの生のスコアを確率値に変換し、マルチクラス分類タスクに適しています。
- loss='categorical_crossentropy': トレーニング中に使用される損失関数です。categorical_crossentropyはワンホットエンコードされたターゲットラベルに適しています。
- optimizer='adam': トレーニング中に使用される最適化アルゴリズムはAdamであり、ニューラルネットワークの中でよく使われます。
- metrics=['accuracy']: トレーニングとテスト中にモデルのパフォーマンスを評価するために使用される評価指標として正解率が含まれます。val_lossもよく使います。
NNモデルの定義
from keras.models import Sequential
from keras.layers import Dense
from sklearn.metrics import classification_report,accuracy_score
from tensorflow.keras.utils import to_categorical
from sklearn.preprocessing import StandardScaler
# データの標準化
scaled=StandardScaler()
X_train=scaled.fit_transform(X_train)
X_test=scaled.transform(X_test)
y_cat_train = to_categorical(y_train)
y_cat_test = to_categorical(y_test)
# NNモデルの定義
model = Sequential()
model.add(Dense(128, input_dim=18, activation='relu'))
model.add(Dense(128, activation='relu'))
model.add(Dense(2, activation='softmax'))
model.compile(loss='categorical_crossentropy', optimizer='adam',metrics=['accuracy'])
print(model.summary())Out[0]
Model: "sequential" _________________________________________________________________ Layer (type) Output Shape Param # ================================================================= dense (Dense) (None, 128) 2432 dense_1 (Dense) (None, 128) 16512 dense_2 (Dense) (None, 2) 258 ================================================================= Total params: 19202 (75.01 KB) Trainable params: 19202 (75.01 KB) Non-trainable params: 0 (0.00 Byte) _________________________________________________________________ None
過学習を防ぐため、Dropoutを追加しても良かったかも。Denseの後にmodel.add(Dropout(0.2))でDropout層を追加できます。
NNモデルの学習
#エポック数は5回で試してみる
model.fit(X_train,y_cat_train,epochs=5,validation_data=(X_test,y_cat_test))Out[0]
Epoch 1/5 8/8 [==============================] - 1s 46ms/step - loss: 0.6474 - accuracy: 0.6157 - val_loss: 0.4756 - val_accuracy: 0.8361 Epoch 2/5 8/8 [==============================] - 0s 9ms/step - loss: 0.4710 - accuracy: 0.8223 - val_loss: 0.3493 - val_accuracy: 0.8361 Epoch 3/5 8/8 [==============================] - 0s 10ms/step - loss: 0.3922 - accuracy: 0.8306 - val_loss: 0.3035 - val_accuracy: 0.8689 Epoch 4/5 8/8 [==============================] - 0s 9ms/step - loss: 0.3569 - accuracy: 0.8430 - val_loss: 0.2855 - val_accuracy: 0.8852 Epoch 5/5 8/8 [==============================] - 0s 9ms/step - loss: 0.3343 - accuracy: 0.8512 - val_loss: 0.2880 - val_accuracy: 0.8852
作成したモデルの精度などの確認
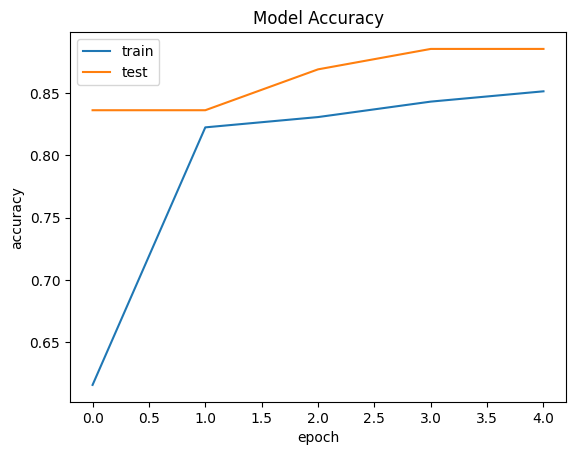
学習のされ方を確認します。学習するにつれ精度が下がったり、損失の値が上昇したりすると過学習傾向にある可能性があります。
Accuracyの確認
精度の確認
import matplotlib.pyplot as plt
plt.plot(model.history.history['accuracy'])
plt.plot(model.history.history['val_accuracy'])
plt.title('Model Accuracy')
plt.ylabel('accuracy')
plt.xlabel('epoch')
plt.legend(['train', 'test'])
plt.show()Out[0]
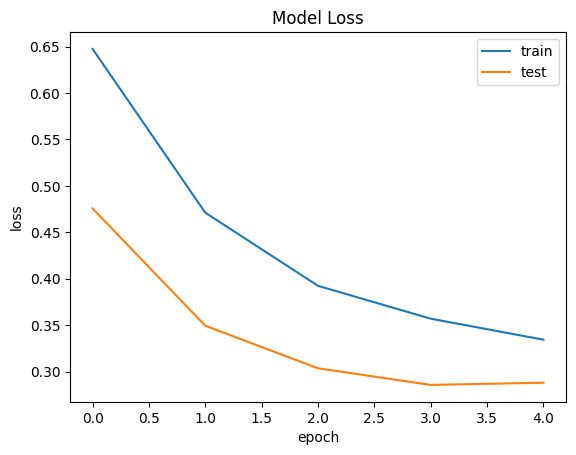
損失の確認
training lossとval lossの確認
plt.plot(model.history.history['loss'])
plt.plot(model.history.history['val_loss'])
plt.title('Model Loss')
plt.ylabel('loss')
plt.xlabel('epoch')
plt.legend(['train', 'test'])
plt.show()Out[0]
訓練データとテストデータに対してモデルを適用し精度を確認
両方のデータに対してモデルの当てはまりを確認
print ("訓練データへの当てはまり:" )
scores_train = model.evaluate(X_train, y_cat_train)
print ("テストデータへの当てはまり:")
scores_test = model.evaluate(X_test, y_cat_test)Out[0]
訓練データへの当てはまり: 8/8 [==============================] - 0s 3ms/step - loss: 0.3171 - accuracy: 0.8512 テストデータへの当てはまり: 2/2 [==============================] - 0s 7ms/step - loss: 0.2880 - accuracy: 0.8852
訓練データの精度とテストデータの精度への差があまりないので過学習はしていなさそうです。
classification_reportの確認
Accuracy以外にも主要な精度指標を確認します。
classification_reportの確認
# テストデータへモデルを適用
# 本当はvalデータとtestデータは分けた方がいい
predictions = model.predict(X_test)
# 予測の確率
prob_pred = np.argmax(predictions, axis=1)
print("**prob_pred**",prob_pred,"\n")
print("**accuracy_score**",accuracy_score(y_test, prob_pred),"\n")
print("**classification_report**",classification_report(y_test, prob_pred))Out[0]
2/2 [==============================] - 0s 4ms/step
**prob_pred** [0 1 0 0 0 0 1 0 0 0 0 1 1 0 1 1 1 0 0 0 1 0 0 1 0 0 0 0 0 1 1 0 1 0 1 0 1
0 0 0 0 0 0 0 0 0 1 1 1 1 0 0 0 0 1 0 1 1 0 0 1]
**accuracy_score** 0.8852459016393442
**classification_report** precision recall f1-score support
0 0.85 0.97 0.90 34
1 0.95 0.78 0.86 27
accuracy 0.89 61
macro avg 0.90 0.87 0.88 61
weighted avg 0.89 0.89 0.88 61
まとめ
sklearnのニューラルネットワークではなく、keras(TensorFlow)を使って見ました。
精度は残念ながらロジスティック回帰と同程度の88.5%でした。
