このブログも幅広くデータ分析に関する情報をまとめて来ました。
Python環境構築からデータ操作の方法、機械学習でのモデル作成とディープラーニングによる物体検知まで手広くやってみました。
そろそろ原点である「様々なデータを分析する」に戻ろうかと思います 笑 (また寄り道をする可能性はあります)
本当はSIGNATEの「【第36回_Beginner限定コンペ】従業員の離職予測 」がとても面白そうで分析して見たかったのですが、ビギナー限定のようなので昔に登録していた私は参加資格がないので断念。もし全メンバー公開に変更になったら取り組んでみたいと思います。
何か自分が興味ありそうなデータセットということで、今回はUC Irvine Machine Learning RepositoryからHeart Diseaseというデータセットを選択しました。
Heart Diseaseデータセットについて
Heart Diseaseデータセットは血管造影検査を受けている患者の心臓病の有無のデータセットになるようです。詳細はInternational application of a new probability algorithm for the diagnosis of coronary artery disease に記載されています。
具体的には下記4つのデータベースが含まれているデータセットになりますが、Clevelandのデータセットのみが現在も機械学習の研究者に使われているようです。
- Cleveland → Cleveland Clinic in Cleveland, Ohio
- Hungary → Hungarian Institute of Cardiology in Budapest, Hungary
- Switzerland → University Hospitals in Zurich and Basel, Switzerland
- VA Long Beach → Veterans Administration Medical Center in Long Beach, California
また、ペーパーを確認する限りここでいう心臓病とは具体的には「虚血性心疾患」のことのようです。
It was concluded that coronary disease probabilities derived from discriminant functions are reliable and clinically useful when applied to patients with chest pain syndromes and intermediate disease prevalence.
引用: https://pubmed.ncbi.nlm.nih.gov/2756873/
少し検索して見ましたが、Clevelandのデータセットは2022年に公開されているEnhanced Heart Disease Prediction Based on Machine Learning and χ2 Statistical Optimal Feature Selection ModelというタイトルのArticleでも使われていました。
本記事ではClevelandのデータセットを使って分析していこうと思います。
データマイニングプロセスについて
こんな手順で分析を進めていますという記事になります。

本記事はCRISP-DMの下記の部分を掘り下げていこうと思います。
- ビジネスの理解
- データの理解
ビジネスの理解
心臓病についての分析をするので、心臓病に関して知識があるのが望ましいです。
医療系の情報になるので医療団体やクリニックなど信頼できそうなソースから必要最低限の知識を引用していこうと思います。
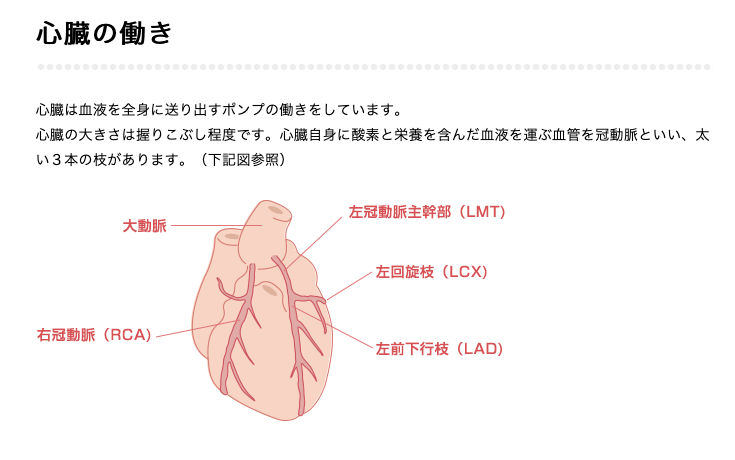
心臓の構造について
図を丸々引用させていただきました。名称と位置関係くらいは知っておくべきかなと思い調べました。
心臓病とは
心臓病とは、心臓の構造や機能(働き)の異常により生じる病気の総称で、その中に、心不全、冠動脈疾患(虚血性心疾患ともいう)、心臓弁膜症、心筋症、不整脈、先天性心疾患などがあります。 心不全は、心臓病の中の1つです。
引用: https://www.jacr.jp/faq/q160/
心臓病にも色々種類があることが分かりますね。
心臓病の危険因子
虚血性心疾患には、狭心症や心筋梗塞があります。・・・虚血性心疾患の3大危険因子は、喫煙・LDLコレステロールの高値・高血圧です。またメタボリックシンドロームも危険因子の一つです。生活習慣では、喫煙のほか、動物性の油に多く含まれる飽和脂肪酸のとりすぎ、お酒の飲み過ぎ、食塩のとりすぎ、運動不足、ストレスが虚血性心疾患のリスクを高くします。一方、魚や野菜、大豆製品には、虚血性心疾患を予防する働きがあります。
引用: https://www.e-healthnet.mhlw.go.jp/information/metabolic/m-05-005.html
酒・タバコはNG、魚や野菜中心の生活をし適度な運動をすると長生きをするとはまさにこのことですね 笑
食塩は摂取しすぎている自覚ありますね、、気をつけよう。
心臓病の自覚症状
坂道で息切れしたり、動悸がする
急いで歩いた時、しばらく胸が痛む
夜明け方トイレに起きたときや洗面の時に胸が痛む
胸の痛みと共に不安感、動悸、息切れ、冷や汗、めまい、脱力感を感じる
引用: https://www.okabefujiko-clinic.com/heartdisease/
日常的にあり得そうな症状なので不安になりますね。
虚血性心疾患(coronary artery disease)とは
横浜市立大学附属病院のウェブサイトより引用しました。症状の重さによって狭心症または心筋梗塞という診断になるようですね。
虚血性心疾患は、いわゆる心臓発作と言われる病気です。心臓を栄養している血管である冠動脈に狭窄や閉塞をきたす病気で、大きく分けると、狭心症と心筋梗塞があります。狭心症は、冠動脈が狭くなり、先端の血管の血流が少なくなり、一時的に「息苦しい」・「胸が締め付けられる」といった症状が出ます。心筋梗塞は、さらに症状が悪化し冠動脈が詰まり、心臓の筋肉細胞が死んでしまい機能が低下してしまう病気です。
特に、急性心筋梗塞は、最初の数時間以内の適切な初期治療が生死をわける疾患です。
引用: https://www.yokohama-cu.ac.jp/fukuhp/section/center_disease/kyoketuseisinnsikkann.html
血管造影検査とは
血管造影検査を受けている患者さんのデータなので、血管造影とは何かも調べました。
血管造影検査とは、細い管(カテーテル)を使って造影剤というお薬を血管に流し込み、血管の疾患を調べるための検査です。... 血管が狭くなったり詰まったりしていないか、腫瘍に栄養を送っている血管はどれかなど、血管が関係している疾患を詳しく調べることができます。また、狭くなった血管を広げたり、腫瘍に栄養を送っている血管を詰めたりなど、治療を行うことも可能です。検査・治療時間は30分から数時間となります。
引用: https://sk-kumamoto.jp/departments/examination/5115/
心電図とは
データセットの変数に心電図の結果の変数があったの調べました。T波やSTなど専門用語が出て来ます。
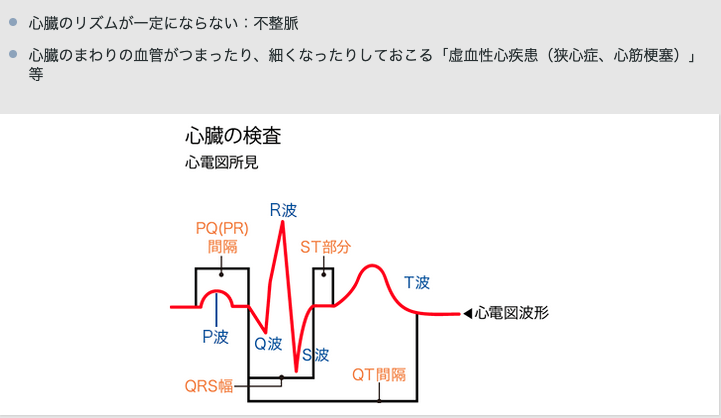
心臓が全身に血液を循環させるために拡張と収縮を繰り返すとき、微弱な活動電流が発生します。その変化を波形として記録することで、例えば心筋梗塞や不整脈などの疾患を診断することができます。
引用: https://y-heart.adic.or.jp/kensa/cardiogram.html
データの理解
次にデータの理解です。
Heart DiseaseからDownloadボタンを押下してデータをダウンロードします。
heart+disease.zipを解答すると下記の様にたくさんファイルが存在します。
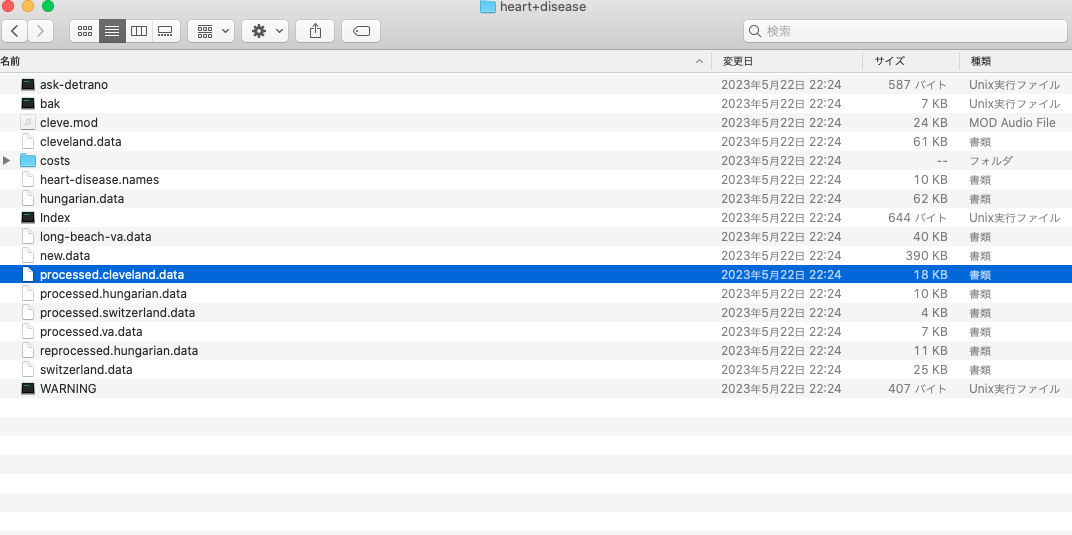
今回利用するのはprocessed.cleveland.dataという名前のファイルになります。
clevelandのデータセットの変数を確認
| No | Attribute Name | Description | 和訳 | 説明 |
|---|---|---|---|---|
| 1 | age | 年齢 | ||
| 2 | sex | 性別 | 1 = male; 0 = female | |
| 3 | cp | chest pain type | 胸痛のタイプ | 1:典型的な狭心症、2:非典型的な狭心症、3:非狭心症痛、4:無症状 |
| 4 | trestbps | resting blood pressure (on admission to the hospital) | 安静時血圧(入院時) | |
| 5 | chol | serum cholestoral | 血清コレステロール | |
| 6 | fbs | fasting blood sugar > 120 mg/dl | 空腹時血糖 > 120 mg/dl | 1:true、0:false |
| 7 | restecg | resting electrocardiographic results | 安静時心電図の結果 | 0: 正常、1:ST-T波異常を示す2:左室肥大の可能性または明確な証拠がある |
| 8 | thalach | maximum heart rate achieved | 最大心拍数 | |
| 9 | exang | exercise induced angina | 運動時に狭心症を誘発 | 1:true、0:false |
| 10 | oldpeak | ST depression induced by exercise relative to rest | [心電図]運動によって誘発されたST低下(安静時と比較) | |
| 11 | slope | the slope of the peak exercise ST segment | [心電図]ピーク運動時のST部分の傾斜 | 1:上向き、2:平坦、3:下降 |
| 12 | ca | number of major vessels (0-3) colored by fluoroscopy | 心臓の主要な血管がフルオロスコピーによって色付けされた数 | |
| 13 | thal | thalassemia | サラセミア | 3:正常、6:固定欠損、7:可逆性欠損 |
| 14 | num | diagnosis of heart disease | 心臓病の診断 | 0:血管狭窄が直径の50%未満、1以上:血管狭窄が直径の50%以上 |
- 「サラセミア」が何のことだが分かりませんでしたが、血液に関連する遺伝子の異常によって引き起こされる血液障害のようです。サラセミアが原因で心臓疾患などを起こすこともあるようです。
サラセミアは溶血性貧血のみならず,脾腫・心臓疾患など多岐にわたって臓器障害を起こす
引用: https://www.jstage.jst.go.jp/article/shinzo/45/7/45_806/_pdf/-char/en
- フルオロスコピー(透視検査)は体内組織の動態画像を生成することが出来る技術のようです。胃の検査だとバリウム検査、心臓病の検査でいうと血管造影検査を指していると思われます。
フルオロスコピーでは、1秒以下程度の周期で撮像と画像再構成とを繰り返すことにより、あたかもX線の透視撮影のように体内組織の動態画像を生成、表示する。
引用: https://patents.google.com/patent/JP2004008398A/ja透視検査とは、Ⅹ線を連続又はパルス出力することによって体内や骨などを観察、処置するための検査です。 バリウム製剤を使用した胃の検査がよく知られていますが、それ以外にも造影剤を使用したさまざまな処置や検査、関節や靭帯の損傷具合をみるための撮影など多岐にわたっています。
引用: https://www.twmu.ac.jp/hospital/rad/ext/imaging/fluoroscopy/Angiography, or angiogram, uses fluoroscopy to identify and diagnose narrowing or blockages in the arteries in your body.
引用: https://my.clevelandclinic.org/health/diagnostics/21992-fluoroscopy
clevelandのデータセットの中身を確認してみる
心臓病に関する知識と出現する医療用語の理解が進んできたので、データを見ていこうと思います。
import pandas as pd
column_names = [
'age', 'sex', 'cp', 'trestbps', 'chol', 'fbs', 'restecg',
'thalach', 'exang', 'oldpeak', 'slope', 'ca', 'thal', 'num'
]
df = pd.read_csv("/Users/hinomaruc/Desktop/blog/dataset/heart+disease/processed.cleveland.data", header=None, names=column_names)
df
age sex cp trestbps chol fbs restecg thalach exang oldpeak slope ca thal num
0 63.0 1.0 1.0 145.0 233.0 1.0 2.0 150.0 0.0 2.3 3.0 0.0 6.0 0
1 67.0 1.0 4.0 160.0 286.0 0.0 2.0 108.0 1.0 1.5 2.0 3.0 3.0 2
2 67.0 1.0 4.0 120.0 229.0 0.0 2.0 129.0 1.0 2.6 2.0 2.0 7.0 1
3 37.0 1.0 3.0 130.0 250.0 0.0 0.0 187.0 0.0 3.5 3.0 0.0 3.0 0
4 41.0 0.0 2.0 130.0 204.0 0.0 2.0 172.0 0.0 1.4 1.0 0.0 3.0 0
... ... ... ... ... ... ... ... ... ... ... ... ... ... ...
298 45.0 1.0 1.0 110.0 264.0 0.0 0.0 132.0 0.0 1.2 2.0 0.0 7.0 1
299 68.0 1.0 4.0 144.0 193.0 1.0 0.0 141.0 0.0 3.4 2.0 2.0 7.0 2
300 57.0 1.0 4.0 130.0 131.0 0.0 0.0 115.0 1.0 1.2 2.0 1.0 7.0 3
301 57.0 0.0 2.0 130.0 236.0 0.0 2.0 174.0 0.0 0.0 2.0 1.0 3.0 1
302 38.0 1.0 3.0 138.0 175.0 0.0 0.0 173.0 0.0 0.0 1.0 ? 3.0 0
303 rows × 14 columns
最後の行のcaの値が「?」になっていますね。元データを見ても「?」になっていました。これは後ほどNaNに変えるなど処理をしたいと思います。
df.info()RangeIndex: 303 entries, 0 to 302 Data columns (total 14 columns): # Column Non-Null Count Dtype --- ------ -------------- ----- 0 age 303 non-null float64 1 sex 303 non-null float64 2 cp 303 non-null float64 3 trestbps 303 non-null float64 4 chol 303 non-null float64 5 fbs 303 non-null float64 6 restecg 303 non-null float64 7 thalach 303 non-null float64 8 exang 303 non-null float64 9 oldpeak 303 non-null float64 10 slope 303 non-null float64 11 ca 303 non-null object 12 thal 303 non-null object 13 num 303 non-null int64 dtypes: float64(11), int64(1), object(2) memory usage: 33.3+ KB
caとthalがobjectになっていますね。「?」みたいにきっと数値以外が入っている可能性が高いので確認して見ます。
print(df[df['ca'].apply(pd.to_numeric, errors='coerce').isnull()])
print("---")
print(df[df['thal'].apply(pd.to_numeric, errors='coerce').isnull()])
age sex cp trestbps chol fbs restecg thalach exang oldpeak \
166 52.0 1.0 3.0 138.0 223.0 0.0 0.0 169.0 0.0 0.0
192 43.0 1.0 4.0 132.0 247.0 1.0 2.0 143.0 1.0 0.1
287 58.0 1.0 2.0 125.0 220.0 0.0 0.0 144.0 0.0 0.4
302 38.0 1.0 3.0 138.0 175.0 0.0 0.0 173.0 0.0 0.0
slope ca thal num
166 1.0 ? 3.0 0
192 2.0 ? 7.0 1
287 2.0 ? 7.0 0
302 1.0 ? 3.0 0
---
age sex cp trestbps chol fbs restecg thalach exang oldpeak \
87 53.0 0.0 3.0 128.0 216.0 0.0 2.0 115.0 0.0 0.0
266 52.0 1.0 4.0 128.0 204.0 1.0 0.0 156.0 1.0 1.0
slope ca thal num
87 1.0 0.0 ? 0
266 2.0 0.0 ? 2
合計で6レコードが「?」になっていました。
clevelandのデータセットの欠損値処理
「?」になっているのをNaNにして、欠損値処理をします。
df['ca'] = pd.to_numeric(df['ca'], errors='coerce')
df['thal'] = pd.to_numeric(df['thal'], errors='coerce')
print(df[df['ca'].apply(pd.to_numeric, errors='coerce').isnull()])
print("---")
print(df[df['thal'].apply(pd.to_numeric, errors='coerce').isnull()])
age sex cp trestbps chol fbs restecg thalach exang oldpeak \
166 52.0 1.0 3.0 138.0 223.0 0.0 0.0 169.0 0.0 0.0
192 43.0 1.0 4.0 132.0 247.0 1.0 2.0 143.0 1.0 0.1
287 58.0 1.0 2.0 125.0 220.0 0.0 0.0 144.0 0.0 0.4
302 38.0 1.0 3.0 138.0 175.0 0.0 0.0 173.0 0.0 0.0
slope ca thal num
166 1.0 NaN 3.0 0
192 2.0 NaN 7.0 1
287 2.0 NaN 7.0 0
302 1.0 NaN 3.0 0
---
age sex cp trestbps chol fbs restecg thalach exang oldpeak \
87 53.0 0.0 3.0 128.0 216.0 0.0 2.0 115.0 0.0 0.0
266 52.0 1.0 4.0 128.0 204.0 1.0 0.0 156.0 1.0 1.0
slope ca thal num
87 1.0 0.0 NaN 0
266 2.0 0.0 NaN 2
NaNになりました。これだけだと欠損値になってしまうので、何かしらの値で置換しようと思います。
置換用に予測モデルを作ってもいいのですが、今回は簡単にnumごとにcaとthalの中央値を計算し埋めてあげようと思います。
ca_median = df.dropna().groupby("num")["ca"].median()
thal_median = df.dropna().groupby("num")["thal"].median()
print("ca_median",ca_median)
print("thal_median",thal_median)ca_median num 0 0.0 1 1.0 2 1.0 3 2.0 4 2.0 Name: ca, dtype: float64 thal_median num 0 3.0 1 7.0 2 7.0 3 7.0 4 7.0 Name: thal, dtype: float64
df['ca'] = df['ca'].fillna(df['num'].map(ca_median))
df['thal'] = df['thal'].fillna(df['num'].map(thal_median))
# 欠損があったレコードを抽出し置換出来ているかを確認
print(df[["ca","thal","num"]].iloc[[166, 192, 287, 302,87, 266]])
ca thal num
166 0.0 3.0 0
192 1.0 7.0 1
287 0.0 7.0 0
302 0.0 3.0 0
87 0.0 3.0 0
266 0.0 7.0 2
きちんと置換できているようです。
clevelandのデータセットの各変数の統計量を確認
df.describe(include='all',percentiles=[0.1,0.2,0.3,0.4,0.5,0.6,0.7,0.8,0.9,0.95,0.99]).transpose()| col | count | mean | std | min | 10% | 20% | 30% | 40% | 50% | 60% | 70% | 80% | 90% | 95% | 99% | max |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| age | 303.0 | 54.438944 | 9.038662 | 29.0 | 42.0 | 45.0 | 50.0 | 53.00 | 56.0 | 58.00 | 59.4 | 62.0 | 66.0 | 68.0 | 71.00 | 77.0 |
| sex | 303.0 | 0.679868 | 0.467299 | 0.0 | 0.0 | 0.0 | 0.0 | 1.00 | 1.0 | 1.00 | 1.0 | 1.0 | 1.0 | 1.0 | 1.00 | 1.0 |
| cp | 303.0 | 3.158416 | 0.960126 | 1.0 | 2.0 | 2.0 | 3.0 | 3.00 | 3.0 | 4.00 | 4.0 | 4.0 | 4.0 | 4.0 | 4.00 | 4.0 |
| trestbps | 303.0 | 131.689769 | 17.599748 | 94.0 | 110.0 | 120.0 | 120.0 | 126.00 | 130.0 | 134.00 | 140.0 | 144.6 | 152.0 | 160.0 | 180.00 | 200.0 |
| chol | 303.0 | 246.693069 | 51.776918 | 126.0 | 188.8 | 204.0 | 218.0 | 230.00 | 241.0 | 254.00 | 268.4 | 286.0 | 308.8 | 326.9 | 406.74 | 564.0 |
| fbs | 303.0 | 0.148515 | 0.356198 | 0.0 | 0.0 | 0.0 | 0.0 | 0.00 | 0.0 | 0.00 | 0.0 | 0.0 | 1.0 | 1.0 | 1.00 | 1.0 |
| restecg | 303.0 | 0.990099 | 0.994971 | 0.0 | 0.0 | 0.0 | 0.0 | 0.00 | 1.0 | 2.00 | 2.0 | 2.0 | 2.0 | 2.0 | 2.00 | 2.0 |
| thalach | 303.0 | 149.607261 | 22.875003 | 71.0 | 116.0 | 130.0 | 140.6 | 146.00 | 153.0 | 159.00 | 163.0 | 170.0 | 176.6 | 181.9 | 191.96 | 202.0 |
| exang | 303.0 | 0.326733 | 0.469794 | 0.0 | 0.0 | 0.0 | 0.0 | 0.00 | 0.0 | 0.00 | 1.0 | 1.0 | 1.0 | 1.0 | 1.00 | 1.0 |
| oldpeak | 303.0 | 1.039604 | 1.161075 | 0.0 | 0.0 | 0.0 | 0.0 | 0.38 | 0.8 | 1.12 | 1.4 | 1.9 | 2.8 | 3.4 | 4.20 | 6.2 |
| slope | 303.0 | 1.600660 | 0.616226 | 1.0 | 1.0 | 1.0 | 1.0 | 1.00 | 2.0 | 2.00 | 2.0 | 2.0 | 2.0 | 3.0 | 3.00 | 3.0 |
| ca | 303.0 | 0.666667 | 0.933790 | 0.0 | 0.0 | 0.0 | 0.0 | 0.00 | 0.0 | 1.00 | 1.0 | 1.0 | 2.0 | 3.0 | 3.00 | 3.0 |
| thal | 303.0 | 4.735974 | 1.940231 | 3.0 | 3.0 | 3.0 | 3.0 | 3.00 | 3.0 | 6.00 | 7.0 | 7.0 | 7.0 | 7.0 | 7.00 | 7.0 |
| num | 303.0 | 0.937294 | 1.228536 | 0.0 | 0.0 | 0.0 | 0.0 | 0.00 | 0.0 | 1.00 | 1.0 | 2.0 | 3.0 | 3.0 | 4.00 | 4.0 |
・年齢は29歳~77歳までと幅広い年齢層のようです。
・性別は1:男性が7割と多いデータになっています。
・胸痛のタイプは4割が無症状
といった情報が分かりました。
clevelandのデータセットの目的変数の作成
#numは0~4までの値が存在するようです。0と1が心臓病の疑いがあるためフラグに変更しておきます。
df['target'] = df['num'].apply(lambda x: 1 if x >= 1 else 0)
print(df["target"].quantile([0,0.1, 0.2, 0.3, 0.4, 0.5, 0.6, 0.7, 0.8, 0.9, 0.95, 0.99,1.0]))0.00 0.0 0.10 0.0 0.20 0.0 0.30 0.0 0.40 0.0 0.50 0.0 0.60 1.0 0.70 1.0 0.80 1.0 0.90 1.0 0.95 1.0 0.99 1.0 1.00 1.0 Name: target, dtype: float64
だいたい半数が心臓病ありのようです。モデル作成のためにバランスデータになっているのでしょうか。
グラフにしてデータの視覚化
そんなにデータ量も変数の数を多くないデータセットなのでさくっと確認して見ます。
各変数の分布の確認
# 各変数の分布確認
fig = plt.figure(figsize=(18,50))
for index in range(len(numerical_df.columns)):
plt.subplot(10,4,index+1)
sns.histplot(data=numerical_df.iloc[:,index].dropna(),bins=20)
fig.tight_layout(pad=1.0)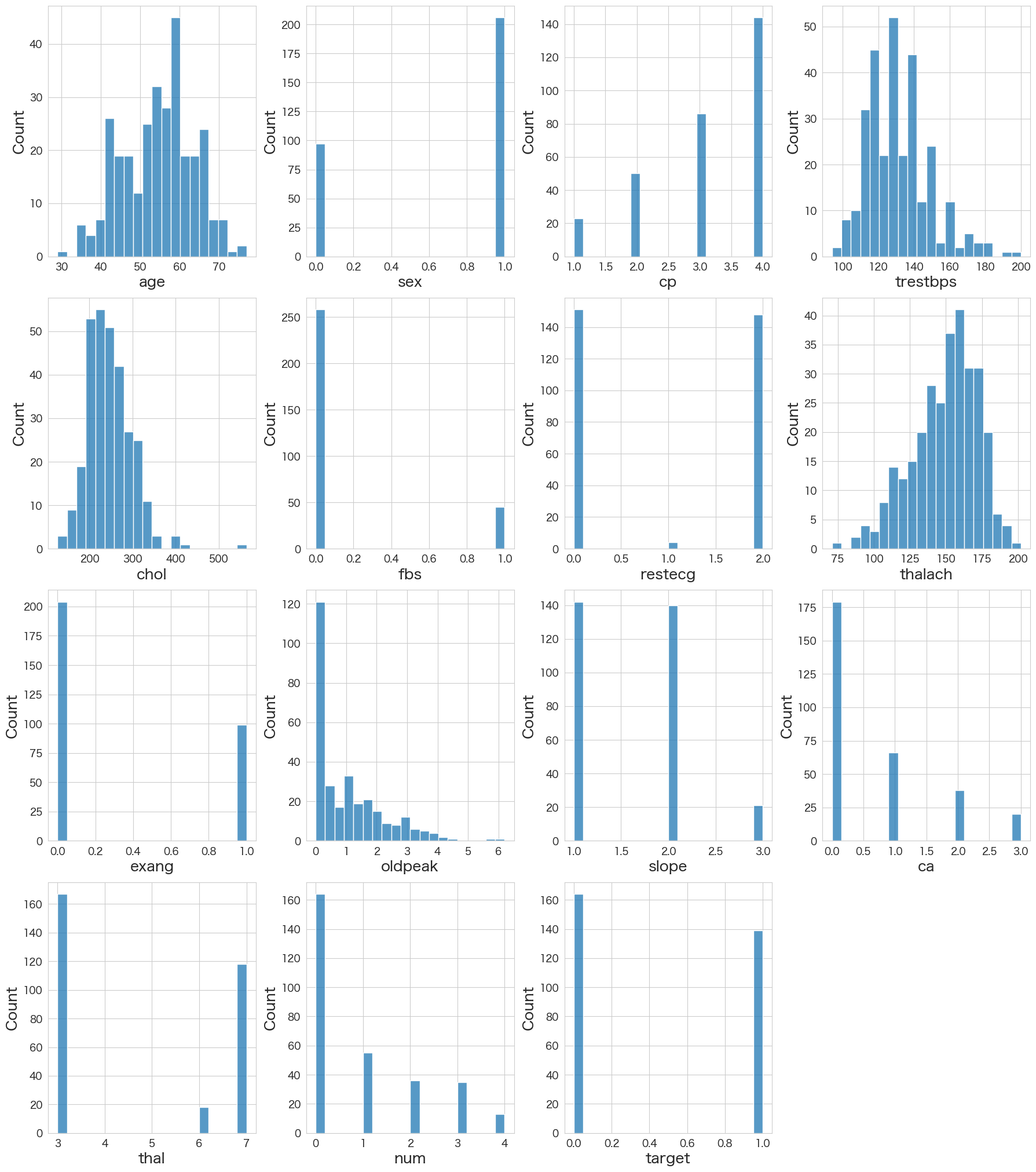
- 年齢は50~60台が多い
- 男性が多い
- 心臓病有無は大体半数ずつでバランスが取れている
num変数で色分けした分布を確認
# 各変数の分布確認 (num変数ごとに色分け)
fig = plt.figure(figsize=(18,50))
for index in range(len(numerical_df.columns)):
plt.subplot(10,4,index+1)
sns.histplot(data=numerical_df,x=numerical_df.iloc[:,index].dropna(),hue="num",multiple="stack",bins=20)
fig.tight_layout(pad=1.0)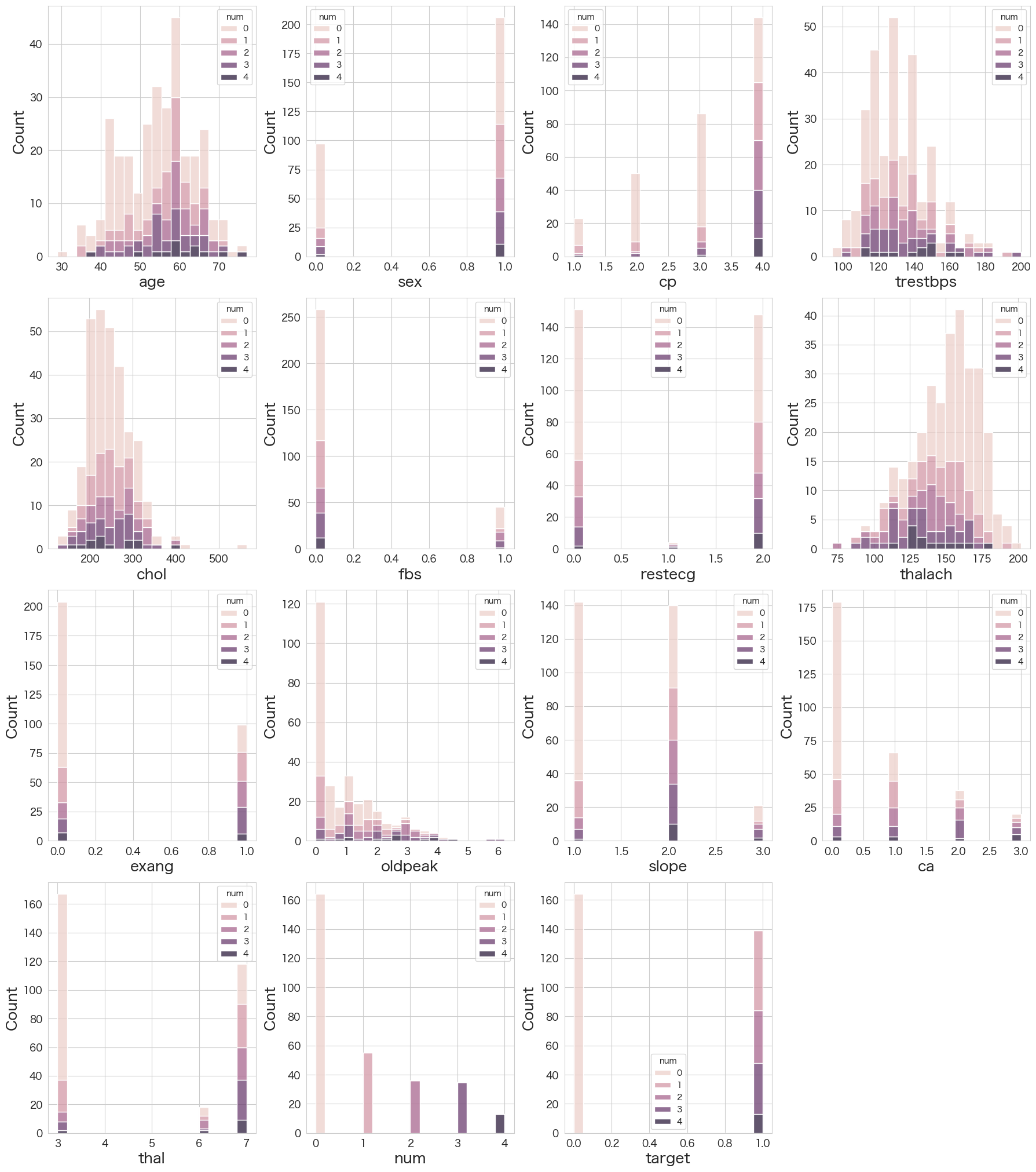
グラフから読み取れるのは下記でしょうか。
- 男性の方が心臓病の確率が高い (たまたまかな?)
- thalach(最大心拍数)は低いほど心臓病の確率が高い
- 感覚とズレますが、cp(胸痛のタイプ)が無症状ほど心臓病の確率が高い
- ca(色づけされた血管の数)が大きいほど心臓病の確率が高い
- slope(ピーク運動時のST部分の傾斜)が平坦か下降だと心臓病の確率が高い
相関係数の確認
# 相関係数確認 (r < 0.3は非表示)
import matplotlib.pyplot as plt
plt.figure(figsize=(18,14))
corr=df.drop(columns=df.columns[[0]]).corr()
sns.heatmap(corr, vmax=1, vmin=-1, center=0, mask = abs(corr) < 0.3,linecolor="black",linewidth=0.5, annot=True,annot_kws={"size":8})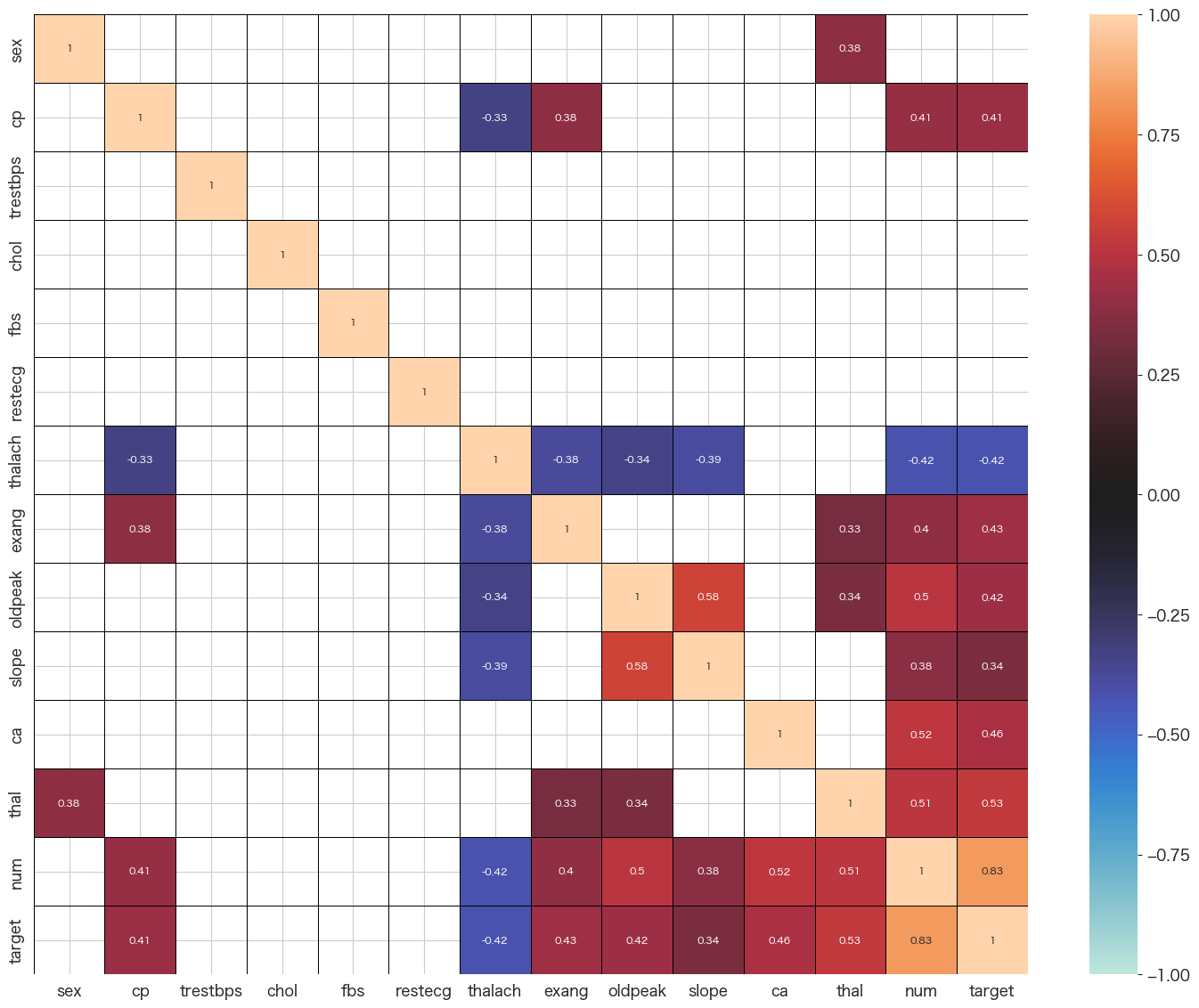
- num x thalachは負の相関がある
- num x oldpeak/ca/thalあたりが正の相関あり
- oldpeak x slopeも正の相関あり
まとめ
医療データの分析は初めてですが、実際にこのようなデータが人々の心臓病へのリスクを発見するのに役立って来たのかと思うとデータ分析を仕事に選んできて良かったなと思います。
今回はビジネスの理解とデータの理解を中心にやりましたので、次回は実際に心臓病かどうかを当てるモデルを作成していきたいと思います。