前回ARモデルの記事を書きました。

結果は1年分の日次予測は難しいかなという結果でした。
今回はMAモデルを試してみます。
時系列モデル一覧
- AR (自己回帰モデル)
- MA (移動平均モデル)
- ARMA (自己回帰移動平均モデル)
- ARIMA (自己回帰和分移動平均モデル)
- ARIMAX (自己回帰和分移動平均モデル with 外因性変数)
- Auto ARIMA (自動ARIMAモデル)
- SARIMA (季節ARIMAモデル)
- SARIMAX (季節ARIMAモデル with 外因性変数)
- ARCH (分散自己回帰モデル)
- GARCH (一般化分散自己回帰モデル)
- VAR (ベクトル自己回帰モデル)
- VARMA (ベクトル自己回帰移動平均モデル)
※ MAモデルについてはWikipedia参照
時系列分析における移動平均モデル(英: moving average model、MAモデル)は現在・過去のホワイトノイズ線形和に定数を加えて単変量の現在値を表現するモデルである
引用: https://ja.wikipedia.org/wiki/移動平均モデル
- アップル引越しの引越し数をMAモデルで予想する
- データの読み込み
- 日付の間隔をasfreqメソッドで変更する
- 欠損値の確認
- 引っ越し数(y)を描画
- yが正規分布に従うかどうかQQプロットを確認
- Mann-Kendall trend検定
- 拡張ディッキー・フラー検定で時系列データが(弱)定常か非定常か確認する
- 非定常過程のデータを定常過程のデータに変換する (階差)
- Mann-Kendall trend検定と拡張ディッキー・フラー検定を定常化したデータで確認する
- MAモデルの作成
- 対数尤度比検定(Log likelihood ratio test)でMA(1)とMA(2)モデルの結果を比較する
- 最適な次数のMAモデルを求める
- 作成したMAモデルの残差分析
- MA(39)モデルを使って引っ越し数を予測する
- まとめ
- 本記事で利用したライブラリのバージョン
アップル引越しの引越し数をMAモデルで予想する
モデル作成するパートまではARモデルと共通になります。
本記事では重複した内容になってしまうので、詳細な説明を省きます。
データの読み込み
# アップル引越しのデータセットを読み込む
import pandas as pd
from matplotlib import pyplot as plt
import pandas as pd
# 訓練データと予測付与用データの読み込み
df = pd.read_csv("/Users/hinomaruc/Desktop/blog/dataset/applehikkoshi/train.csv",parse_dates=['datetime'],index_col='datetime')
df_test = pd.read_csv("/Users/hinomaruc/Desktop/blog/dataset/applehikkoshi/test.csv",parse_dates=['datetime'],index_col='datetime')# 描画設定
from IPython.display import HTML
import seaborn as sns
from matplotlib import ticker
import matplotlib.pyplot as plt
sns.set_style("whitegrid")
from matplotlib import rcParams
rcParams['font.family'] = 'Hiragino Sans' # Macの場合
#rcParams['font.family'] = 'Meiryo' # Windowsの場合
#rcParams['font.family'] = 'VL PGothic' # Linuxの場合
rcParams['xtick.labelsize'] = 12 # x軸のラベルのフォントサイズ
rcParams['ytick.labelsize'] = 12 # y軸のラベルのフォントサイズ
rcParams['axes.labelsize'] = 18 # ラベルのフォントとサイズ
rcParams['figure.figsize'] = 18,8 # 画像サイズの変更(inch)日付の間隔をasfreqメソッドで変更する
asfreqメソッドはpandasのメソッドで日付の粒度を変更してくれたり、足りない日付も作成してくれる便利なメソッドです。
# https://pandas.pydata.org/docs/reference/api/pandas.DataFrame.asfreq.html
# 日付の間隔を「日間隔」に変更 (元から日別のデータですが、、週や月間隔にも変更できます)
df = df.asfreq('d')df.info()DatetimeIndex: 2101 entries, 2010-07-01 to 2016-03-31 Freq: D Data columns (total 5 columns): # Column Non-Null Count Dtype --- ------ -------------- ----- 0 y 2101 non-null int64 1 client 2101 non-null int64 2 close 2101 non-null int64 3 price_am 2101 non-null int64 4 price_pm 2101 non-null int64 dtypes: int64(5) memory usage: 98.5 KB
欠損値の確認
df.infoメソッドで確認した通り、欠損値は今回存在しませんのでスキップします。
引っ越し数(y)を描画
pandasのplotメソッドで描画できます。
df.y.plot()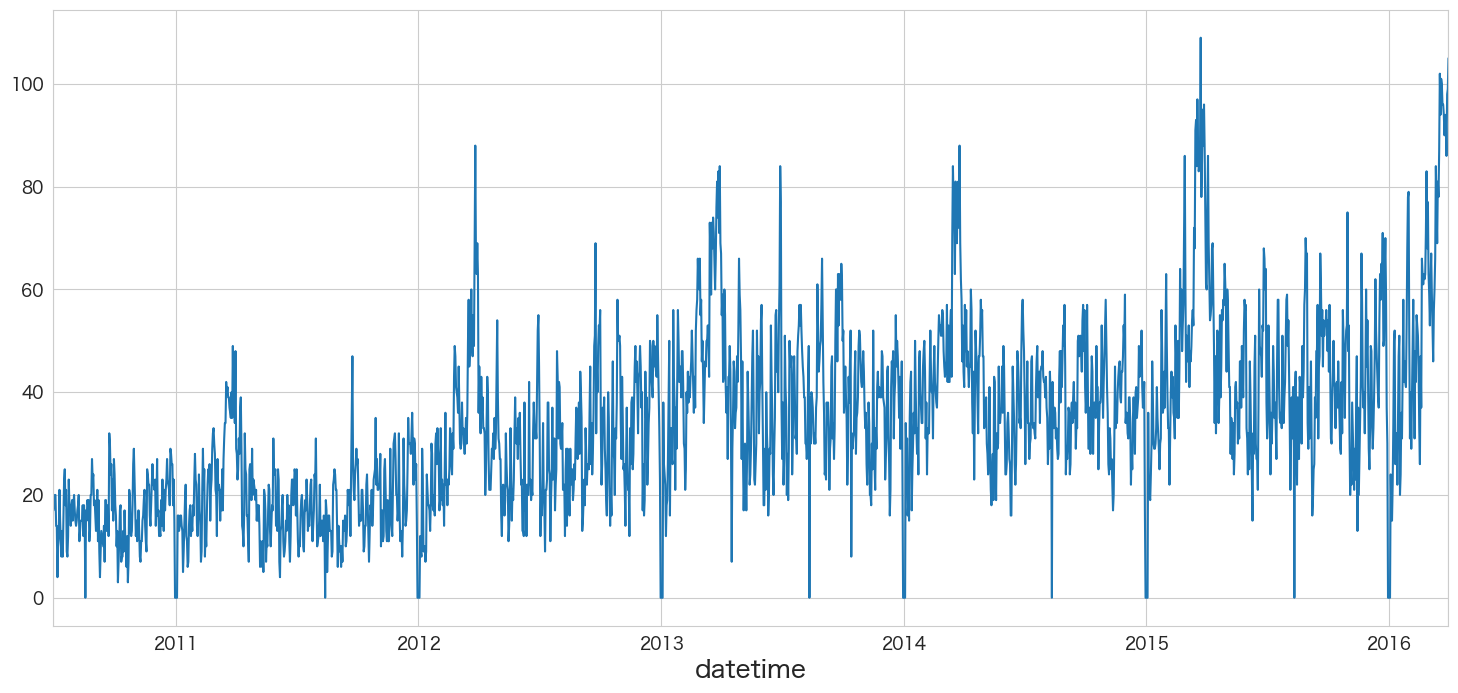
yが正規分布に従うかどうかQQプロットを確認
統計手法を適用するにあたり、おおよそ正規分布を仮定する必要があります。
そのためデータが正規分布に従っているかどうかQQプロットという手法を使って確認します。
# 正規分布に従うかどうかをQQプロットを描画して確認
import scipy.stats as stats
import matplotlib.pyplot as plt
plt.subplot(1,2,1)
sns.histplot(df["y"], kde=True)
plt.subplot(1,2,2)
stats.probplot(df["y"], dist="norm", plot=plt)
plt.show()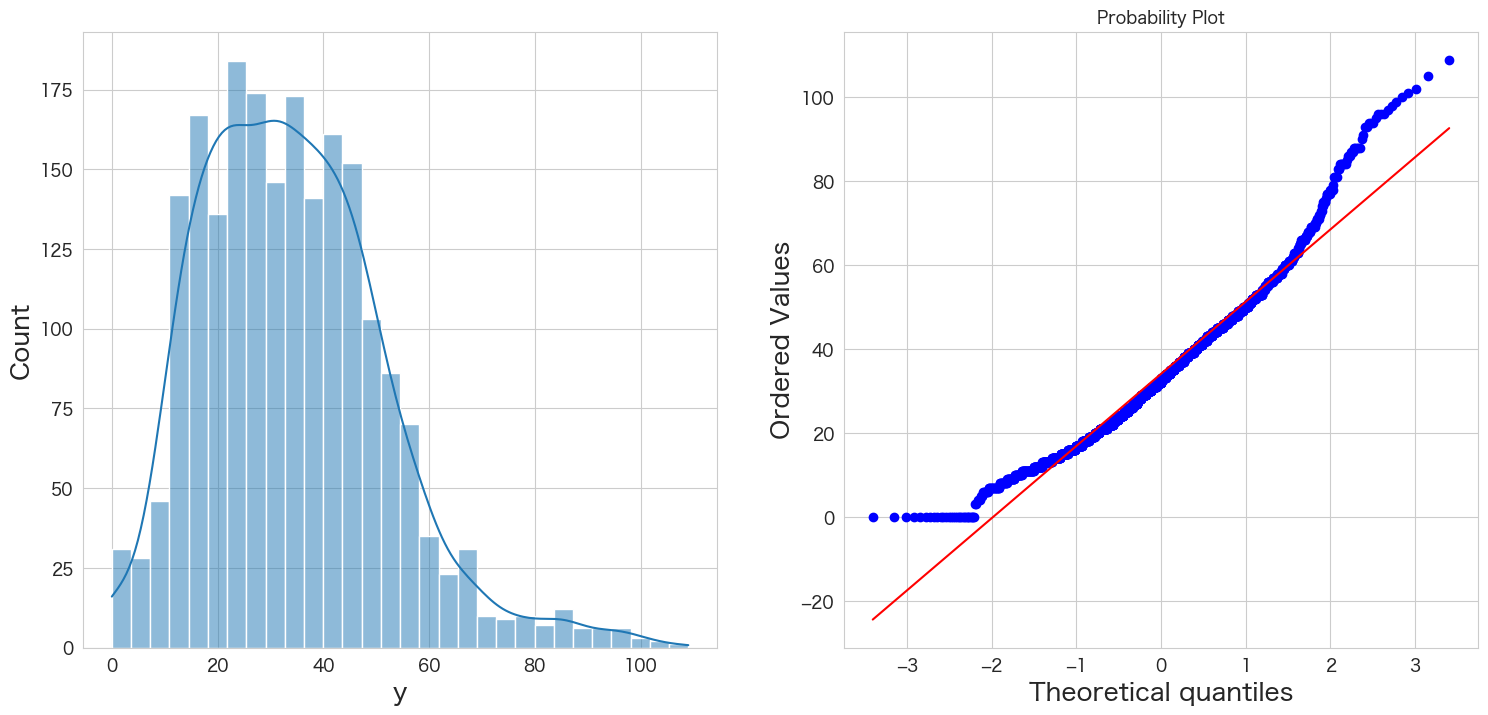
左側のグラフがヒストグラム、右側のグラフがQQプロットです。
青い点が赤い線に沿っていれば正規分布であるという表現方法になっています。
端の部分がずれているようですが、なんとなく正規分布に従っていると仮定します。
Mann-Kendall trend検定
H0: データにトレンドは存在しない
HA: データにトレンドが存在する
# https://pypi.org/project/pymannkendall/
import pymannkendall as mk
mk.original_test(df["y"])Mann_Kendall_Test(trend='increasing', h=True, p=0.0, z=30.51302505819748, Tau=0.4440819564379774, s=979667.0, var_s=1030826418.3333334, slope=0.016624040920716114, intercept=14.544757033248079)
p <= 0.05なので帰無仮説は棄却され、データにトレンドは存在するという結果になりました。
そのため、拡張ディッキー・フラー検定ではトレンドがあるということを示すregression='ct'のオプションを追加しようと思います。
拡張ディッキー・フラー検定で時系列データが(弱)定常か非定常か確認する
帰無仮説と対立仮説は下記になります。
H0: 単位根がある
HA: 単位根がない
# https://www.statsmodels.org/dev/generated/statsmodels.tsa.stattools.adfuller.html
from statsmodels.tsa.stattools import adfuller
# 検定結果を見やすく加工
result = adfuller(df["y"],regression='ct')
labels = ["検定統計量","P値","#ラグ数","#観測数"]
mod_result = pd.Series(result[0:4],index=labels)
for key,val in result[4].items():
mod_result[f'臨界値 (有意水準:{key})'] = val;
mod_result検定統計量 -3.139726 P値 0.097095 #ラグ数 26.000000 #観測数 2074.000000 臨界値 (有意水準:1%) -3.963142 臨界値 (有意水準:5%) -3.412609 臨界値 (有意水準:10%) -3.128298 dtype: float64
P値が0.05以下ではないため帰無仮説を棄却できず「単位根がないとは言えない」という結果になります。
つまりアップル引っ越しのデータセットは弱定常過程ではなく、非定常過程の可能性がありそうです。
非定常過程のデータを定常過程のデータに変換する (階差)
拡張ディッキー・フラー検定で単位根がないとは言えないという結果になったので、本データセットは非定常過程のデータであると思われます。従って階差によって定常過程のデータに変換してモデルを作成します。
# https://pandas.pydata.org/docs/reference/api/pandas.DataFrame.diff.html
# 1階差分を取る
df_diff1 = df.diff(periods=1).dropna()
df_diff1.head()
y client close price_am price_pm datetime 2010-07-02 1.0 0.0 0.0 0.0 0.0 2010-07-03 2.0 0.0 0.0 0.0 0.0 2010-07-04 0.0 0.0 0.0 0.0 0.0 2010-07-05 -6.0 0.0 0.0 0.0 0.0 2010-07-06 0.0 0.0 0.0 0.0 0.0
df_diff1.y.plot()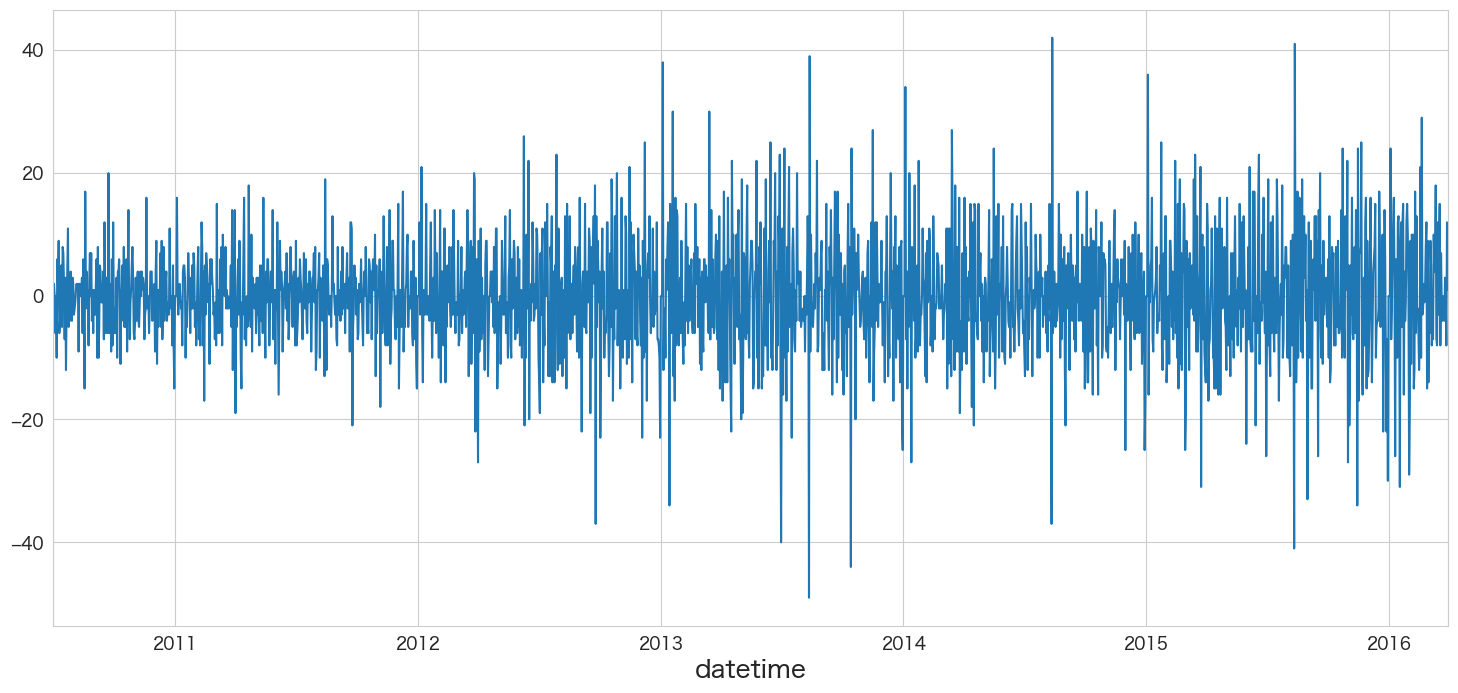
定常過程っぽいデータになりましたね
Mann-Kendall trend検定と拡張ディッキー・フラー検定を定常化したデータで確認する
下記記事と同じ内容になりますので、興味ある方はご確認ください。
まとめると、
・トレンドはなさそう
・(弱)定常過程でありそう
という結果になります。
MAモデルの作成
まずは、1次のMAモデルyt=c +θ1εt-1+εtを作成していこうと思います。
1次からより高次元のMAモデルを作成していきます。
どの次元のMAモデルがいいかは対数尤度比検定(Log likelihood ratio test)で判断するにします。
ただし、Log likelihoood ratio testは自由度が異なるモデル間を検定するらしく、同じ自由度のモデルを比較する場合はAICやBICを使うとよいようです。
それではMAモデルの作成をしていきたいと思います。
from statsmodels.tsa.arima.model import ARIMA
# 1次MAモデルの作成
ma_model = ARIMA(df_diff1.y,order=(0,0,1))
ret = ma_model.fit()
ret.summary()
SARIMAX Results Dep. Variable: y No. Observations: 2100 Model: ARIMA(0, 0, 1) Log Likelihood -7622.801 Date: Mon, 19 Sep 2022 AIC 15251.602 Time: 21:34:26 BIC 15268.552 Sample: 07-02-2010 HQIC 15257.810 - 03-31-2016 Covariance Type: opg
coef std err z P>|z| [0.025 0.975] const 0.0408 0.143 0.285 0.776 -0.240 0.322 ma.L1 -0.2809 0.018 -15.691 0.000 -0.316 -0.246 sigma2 83.2537 1.905 43.714 0.000 79.521 86.987
Ljung-Box (L1) (Q): 4.91 Jarque-Bera (JB): 253.38 Prob(Q): 0.03 Prob(JB): 0.00 Heteroskedasticity (H): 2.48 Skew: -0.09 Prob(H) (two-sided): 0.00 Kurtosis: 4.69
Warnings:
[1] Covariance matrix calculated using the outer product of gradients (complex-step).
ma.L1のP>|z|が一次MAモデルのθ係数の有意性になります。0.05以下なので有意で意味のある係数のようです。
from statsmodels.tsa.arima.model import ARIMA
# 2次MAモデルの作成
ma_model2 = ARIMA(df_diff1.y,order=(0,0,2))
ret2 = ma_model2.fit()
ret2.summary()
SARIMAX Results Dep. Variable: y No. Observations: 2100 Model: ARIMA(0, 0, 2) Log Likelihood -7577.264 Date: Mon, 19 Sep 2022 AIC 15162.528 Time: 21:35:03 BIC 15185.127 Sample: 07-02-2010 HQIC 15170.806 - 03-31-2016 Covariance Type: opg
coef std err z P>|z| [0.025 0.975] const 0.0394 0.090 0.440 0.660 -0.136 0.215 ma.L1 -0.3180 0.018 -17.927 0.000 -0.353 -0.283 ma.L2 -0.2237 0.019 -11.636 0.000 -0.261 -0.186 sigma2 79.7123 1.878 42.456 0.000 76.032 83.392
Ljung-Box (L1) (Q): 2.64 Jarque-Bera (JB): 201.76 Prob(Q): 0.10 Prob(JB): 0.00 Heteroskedasticity (H): 2.54 Skew: -0.06 Prob(H) (two-sided): 0.00 Kurtosis: 4.51
Warnings:
[1] Covariance matrix calculated using the outer product of gradients (complex-step).
2次MAモデルもma.L1とma.L2はP>|z|が0.05以下なので有意であり意味のある係数のようです。
MA(1)とMA(2)のどちらがが良いモデルかLog likelihood ratio testで確認してみます。
対数尤度比検定(Log likelihood ratio test)でMA(1)とMA(2)モデルの結果を比較する
# 参考: https://stackoverflow.com/questions/11725115/p-value-from-chi-sq-test-statistic-in-python
LL1 = ret.llf
LL2 = ret2.llf
LLR = 2 * (LL2-LL1)
from scipy.stats.distributions import chi2
p = chi2.sf(LLR,1).round(3)
if p <= 0.05:
print(f"p値={p}で有意差あり")
else:
print(f"p値={p}で有意差なし")p値=0.0で有意差あり
p値=0.0で有意差ありなのでMA(2)の方が良いモデルのようです。
このように対数尤度比検定を次数を変えたモデルで確認し、最適なMAモデルを探索していこうと思います。
最適な次数のMAモデルを求める
# Log likelihood ratio testの関数作成
"""
Log likelihood ratio test
H0: 2つのモデルの比に有意差はない
HA: 2つのモデルの比に有意差がある
引数1: モデル1のLog Likelihood
引数2: モデル2のLog Likelihood
引数3: 自由度
リターン: p値
"""
def llr_test(llf1,llf2,dof):
LL1 = llf1
LL2 = llf2
LLR = 2 * (LL2-LL1)
from scipy.stats.distributions import chi2
p = chi2.sf(LLR,dof).round(3)
return p# MA(1) ~ MA(40)までで一番良さそうなモデルを探索する。
from statsmodels.tsa.arima.model import ARIMA
import datetime
best_ma_model_fit = None
alpha=0.05
for i in range(1,41):
# MAモデル作成
ma_model = ARIMA(df_diff1["y"],order=(0,0,i))
ma_model_fit = ma_model.fit()
# MA(1)は自動的にベストモデルになる
if i == 1:
best_ma_model_fit = ma_model_fit
else:
# MA(2) 以降の処理
llf1 = best_ma_model_fit.llf
llf2 = ma_model_fit.llf
dof = ma_model_fit.model_orders["ma"] - best_ma_model_fit.model_orders["ma"]
test_result = llr_test(llf1,llf2,dof)
if test_result <= alpha:
# 有意差があれば、ベストモデルを更新
print(f'llr-test result: compare MA({best_ma_model_fit.model_orders["ma"]}) and MA({ma_model_fit.model_orders["ma"]}) -> p値={test_result}')
best_ma_model_fit = ma_model_fit
print(f"{datetime.datetime.now()}: best model is MA({i}) -> Log Likelihood:{best_ma_model_fit.llf}、AIC:{best_ma_model_fit.aic}、BIC:{best_ma_model_fit.bic}、HQIC:{best_ma_model_fit.hqic}")
print("-----")
llr-test result: compare MA(1) and MA(2) -> p値=0.0
2022-09-19 21:42:23.880193: best model is MA(2) -> Log Likelihood:-7577.264168363667、AIC:15162.528336727333、BIC:15185.127107222179、HQIC:15170.805660464326
-----
llr-test result: compare MA(2) and MA(3) -> p値=0.0
2022-09-19 21:42:24.477878: best model is MA(3) -> Log Likelihood:-7551.785447489167、AIC:15113.570894978335、BIC:15141.819358096893、HQIC:15123.917549649577
-----
llr-test result: compare MA(3) and MA(4) -> p値=0.0
2022-09-19 21:42:25.336435: best model is MA(4) -> Log Likelihood:-7529.617259148779、AIC:15071.234518297559、BIC:15105.132674039827、HQIC:15083.650503903049
-----
llr-test result: compare MA(4) and MA(5) -> p値=0.0
2022-09-19 21:42:26.380679: best model is MA(5) -> Log Likelihood:-7517.830028757687、AIC:15049.660057515373、BIC:15089.207905881354、HQIC:15064.145374055113
-----
llr-test result: compare MA(5) and MA(6) -> p値=0.0
2022-09-19 21:42:27.953519: best model is MA(6) -> Log Likelihood:-7510.6704336506755、AIC:15037.340867301351、BIC:15082.538408291042、HQIC:15053.895514775339
-----
llr-test result: compare MA(6) and MA(7) -> p値=0.0
2022-09-19 21:42:29.694591: best model is MA(7) -> Log Likelihood:-7503.860597429184、AIC:15025.721194858368、BIC:15076.568428471772、HQIC:15044.345173266604
-----
llr-test result: compare MA(7) and MA(8) -> p値=0.0
2022-09-19 21:42:31.865103: best model is MA(8) -> Log Likelihood:-7492.227477158641、AIC:15004.454954317282、BIC:15060.951880554398、HQIC:15025.148263659767
-----
llr-test result: compare MA(8) and MA(9) -> p値=0.0
2022-09-19 21:42:34.071557: best model is MA(9) -> Log Likelihood:-7450.974551822975、AIC:14923.94910364595、BIC:14986.095722506776、HQIC:14946.711743922682
-----
llr-test result: compare MA(9) and MA(10) -> p値=0.0
2022-09-19 21:42:36.816402: best model is MA(10) -> Log Likelihood:-7439.756302084381、AIC:14903.512604168762、BIC:14971.3089156533、HQIC:14928.344575379742
-----
llr-test result: compare MA(10) and MA(11) -> p値=0.009
2022-09-19 21:42:40.205474: best model is MA(11) -> Log Likelihood:-7436.311586449203、AIC:14898.623172898406、BIC:14972.069177006655、HQIC:14925.524475043636
-----
llr-test result: compare MA(11) and MA(13) -> p値=0.0
2022-09-19 21:42:53.672968: best model is MA(13) -> Log Likelihood:-7423.893324737082、AIC:14877.786649474165、BIC:14962.532038829837、HQIC:14908.82661348789
-----
llr-test result: compare MA(13) and MA(14) -> p値=0.001
2022-09-19 21:42:58.849630: best model is MA(14) -> Log Likelihood:-7418.025921734631、AIC:14868.051843469262、BIC:14958.446925448647、HQIC:14901.161138417237
-----
llr-test result: compare MA(14) and MA(17) -> p値=0.033
2022-09-19 21:43:18.679459: best model is MA(17) -> Log Likelihood:-7413.6708557022075、AIC:14865.341711404415、BIC:14972.685871254935、HQIC:14904.658999155135
-----
llr-test result: compare MA(17) and MA(18) -> p値=0.028
2022-09-19 21:43:30.072501: best model is MA(18) -> Log Likelihood:-7411.265404910369、AIC:14862.530809820739、BIC:14975.524662294969、HQIC:14903.917428505707
-----
llr-test result: compare MA(18) and MA(20) -> p値=0.016
2022-09-19 21:43:51.716849: best model is MA(20) -> Log Likelihood:-7407.143214332113、AIC:14858.286428664225、BIC:14982.579666385878、HQIC:14903.81170921769
-----
llr-test result: compare MA(20) and MA(21) -> p値=0.0
2022-09-19 21:44:02.960982: best model is MA(21) -> Log Likelihood:-7397.854523477873、AIC:14841.709046955746、BIC:14971.651977301111、HQIC:14889.30365844346
-----
llr-test result: compare MA(21) and MA(22) -> p値=0.047
2022-09-19 21:44:15.658657: best model is MA(22) -> Log Likelihood:-7395.886079199441、AIC:14839.772158398882、BIC:14975.364781367958、HQIC:14889.436100820845
-----
llr-test result: compare MA(22) and MA(24) -> p値=0.035
2022-09-19 21:44:46.954873: best model is MA(24) -> Log Likelihood:-7392.530385301556、AIC:14837.060770603111、BIC:14983.95277881961、HQIC:14890.863374893572
-----
llr-test result: compare MA(24) and MA(27) -> p値=0.0
2022-09-19 21:45:55.412235: best model is MA(27) -> Log Likelihood:-7383.035234065892、AIC:14824.070468131784、BIC:14987.911554219418、HQIC:14884.08106522499
-----
llr-test result: compare MA(27) and MA(28) -> p値=0.006
2022-09-19 21:46:21.400512: best model is MA(28) -> Log Likelihood:-7379.264418692975、AIC:14818.52883738595、BIC:14988.019616097296、HQIC:14880.608765413403
-----
llr-test result: compare MA(28) and MA(31) -> p値=0.033
2022-09-19 21:48:03.849871: best model is MA(31) -> Log Likelihood:-7374.887777850632、AIC:14815.775555701264、BIC:15002.215412283744、HQIC:14884.063476531463
-----
llr-test result: compare MA(31) and MA(36) -> p値=0.047
2022-09-19 21:52:35.675352: best model is MA(36) -> Log Likelihood:-7369.25963354405、AIC:14814.5192670881、BIC:15029.207586789138、HQIC:14893.153842589541
-----
/Users/hinomaruc/Desktop/blog/my-venv/lib/python3.8/site-packages/statsmodels/base/model.py:604: ConvergenceWarning: Maximum Likelihood optimization failed to converge. Check mle_retvals warnings.warn("Maximum Likelihood optimization failed to
llr-test result: compare MA(36) and MA(37) -> p値=0.0
2022-09-19 21:55:42.786608: best model is MA(37) -> Log Likelihood:-7357.480059109044、AIC:14792.960118218089、BIC:15013.298130542838、HQIC:14873.664024653777
-----
/Users/hinomaruc/Desktop/blog/my-venv/lib/python3.8/site-packages/statsmodels/base/model.py:604: ConvergenceWarning: Maximum Likelihood optimization failed to converge. Check mle_retvals warnings.warn("Maximum Likelihood optimization failed to
llr-test result: compare MA(37) and MA(38) -> p値=0.0
2022-09-19 21:59:06.979033: best model is MA(38) -> Log Likelihood:-7348.874962628264、AIC:14777.749925256529、BIC:15003.737630204989、HQIC:14860.523162626467
-----
/Users/hinomaruc/Desktop/blog/my-venv/lib/python3.8/site-packages/statsmodels/base/model.py:604: ConvergenceWarning: Maximum Likelihood optimization failed to converge. Check mle_retvals warnings.warn("Maximum Likelihood optimization failed to
llr-test result: compare MA(38) and MA(39) -> p値=0.0
2022-09-19 22:01:40.971223: best model is MA(39) -> Log Likelihood:-7341.598684201929、AIC:14765.197368403858、BIC:14996.834765976031、HQIC:14850.039936708044
-----
/Users/hinomaruc/Desktop/blog/my-venv/lib/python3.8/site-packages/statsmodels/base/model.py:604: ConvergenceWarning: Maximum Likelihood optimization failed to converge. Check mle_retvals warnings.warn("Maximum Likelihood optimization failed to
途中warningが出てしまいましたが、MA(39)がベストモデルのようです。
ちなみにConvergenceWarning: Maximum Likelihood optimization failed to convergeはモデルの当てはまりが悪いなどでパラメーターの探索がうまくいってない場合に発生するようです。
This message suggests that the optimizer is having a hard time determining good values for all of the parameters. There are a number of possible reasons why this could happen, but one reason is if the model is not a good fit for your data.
引用: https://github.com/statsmodels/statsmodels/issues/8314
# ベストモデルのサマリ情報の確認
best_ma_model_fit.summary()
SARIMAX Results Dep. Variable: y No. Observations: 2100 Model: ARIMA(0, 0, 39) Log Likelihood -7341.599 Date: Mon, 19 Sep 2022 AIC 14765.197 Time: 22:08:33 BIC 14996.835 Sample: 07-02-2010 HQIC 14850.040 - 03-31-2016 Covariance Type: opg
coef std err z P>|z| [0.025 0.975] const 0.0181 0.002 7.912 0.000 0.014 0.023 ma.L1 -0.3987 0.018 -21.865 0.000 -0.434 -0.363 ma.L2 -0.1053 0.023 -4.577 0.000 -0.150 -0.060 ma.L3 -0.0696 0.023 -2.968 0.003 -0.116 -0.024 ma.L4 -0.1197 0.023 -5.275 0.000 -0.164 -0.075 ma.L5 -0.0627 0.024 -2.622 0.009 -0.110 -0.016 ma.L6 0.0811 0.023 3.595 0.000 0.037 0.125 ma.L7 0.1130 0.024 4.806 0.000 0.067 0.159 ma.L8 -0.0576 0.024 -2.388 0.017 -0.105 -0.010 ma.L9 -0.1152 0.024 -4.880 0.000 -0.161 -0.069 ma.L10 -0.0575 0.024 -2.415 0.016 -0.104 -0.011 ma.L11 -0.0723 0.024 -3.063 0.002 -0.119 -0.026 ma.L12 -0.0917 0.024 -3.854 0.000 -0.138 -0.045 ma.L13 0.0683 0.025 2.738 0.006 0.019 0.117 ma.L14 0.0831 0.025 3.345 0.001 0.034 0.132 ma.L15 -0.0340 0.024 -1.404 0.160 -0.081 0.013 ma.L16 -0.0117 0.025 -0.477 0.634 -0.060 0.036 ma.L17 -0.0447 0.024 -1.867 0.062 -0.092 0.002 ma.L18 -0.0661 0.023 -2.836 0.005 -0.112 -0.020 ma.L19 -0.0256 0.022 -1.145 0.252 -0.069 0.018 ma.L20 0.0342 0.022 1.534 0.125 -0.010 0.078 ma.L21 0.1104 0.023 4.708 0.000 0.064 0.156 ma.L22 -0.0362 0.024 -1.531 0.126 -0.082 0.010 ma.L23 0.0314 0.024 1.327 0.184 -0.015 0.078 ma.L24 -0.0614 0.024 -2.576 0.010 -0.108 -0.015 ma.L25 -0.0385 0.025 -1.542 0.123 -0.087 0.010 ma.L26 -0.0112 0.024 -0.469 0.639 -0.058 0.035 ma.L27 0.0665 0.025 2.704 0.007 0.018 0.115 ma.L28 0.0644 0.024 2.692 0.007 0.018 0.111 ma.L29 0.0373 0.024 1.553 0.121 -0.010 0.084 ma.L30 0.0362 0.024 1.524 0.128 -0.010 0.083 ma.L31 -0.0670 0.025 -2.726 0.006 -0.115 -0.019 ma.L32 -0.0185 0.024 -0.760 0.447 -0.066 0.029 ma.L33 -0.0453 0.024 -1.898 0.058 -0.092 0.001 ma.L34 0.0595 0.024 2.496 0.013 0.013 0.106 ma.L35 0.0353 0.023 1.551 0.121 -0.009 0.080 ma.L36 -0.0157 0.022 -0.700 0.484 -0.060 0.028 ma.L37 -0.0484 0.024 -1.994 0.046 -0.096 -0.001 ma.L38 -0.0519 0.024 -2.207 0.027 -0.098 -0.006 ma.L39 -0.0901 0.021 -4.252 0.000 -0.132 -0.049 sigma2 63.3374 1.553 40.777 0.000 60.293 66.382
Ljung-Box (L1) (Q): 0.00 Jarque-Bera (JB): 306.78 Prob(Q): 1.00 Prob(JB): 0.00 Heteroskedasticity (H): 2.27 Skew: -0.22 Prob(H) (two-sided): 0.00 Kurtosis: 4.82
Warnings:
[1] Covariance matrix calculated using the outer product of gradients (complex-step).
MA(1) ~ MA(40) まで確認をして、MA(39)が良さそうなモデルだという結果になりました。
ma.L39のp値も0.05以下なので有意な係数のようです。また、AICの値もMA(38)より低くなっているので問題なさそうです。今回はMA(39)を採用したいと思います。
次は作成したモデルが適切かどうか残差分析を行います。
作成したMAモデルの残差分析
残差の正規性はQQプロットで確認することにします。残差の間に相関がない(独立している)ことはLjung-Box検定で確認します。
resid = best_ma_model_fit.resid
# MA(39)の残差データを確認
resid.plot()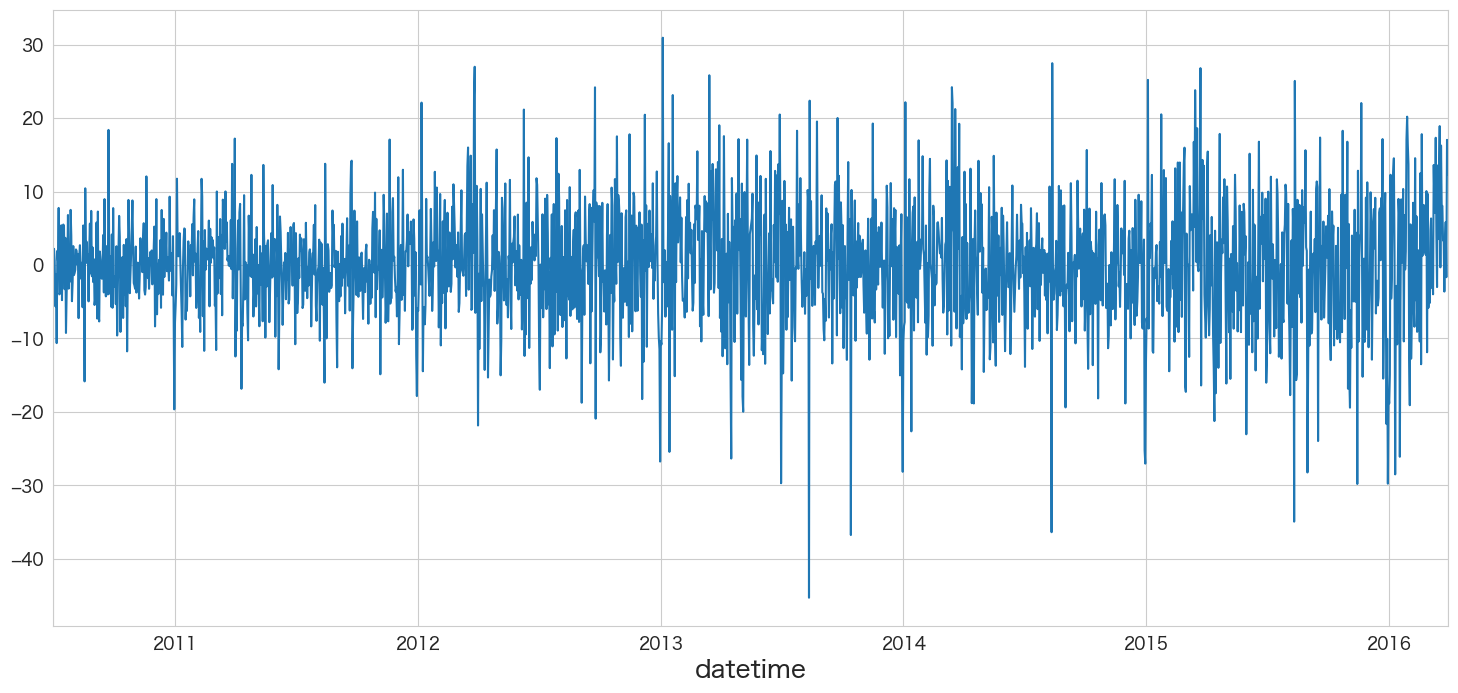
残差の平均と分散を確認
print(f"mean:{resid.mean()}、variance:{resid.var()}")mean:0.02523054696107296、variance:63.628592870029266
残差の正規性の確認
# 正規分布に従うかどうかをQQプロットを描画して確認
import scipy.stats as stats
import matplotlib.pyplot as plt
plt.subplot(1,2,1)
sns.histplot(resid, kde=True)
plt.subplot(1,2,2)
stats.probplot(resid, dist="norm", plot=plt)
plt.show()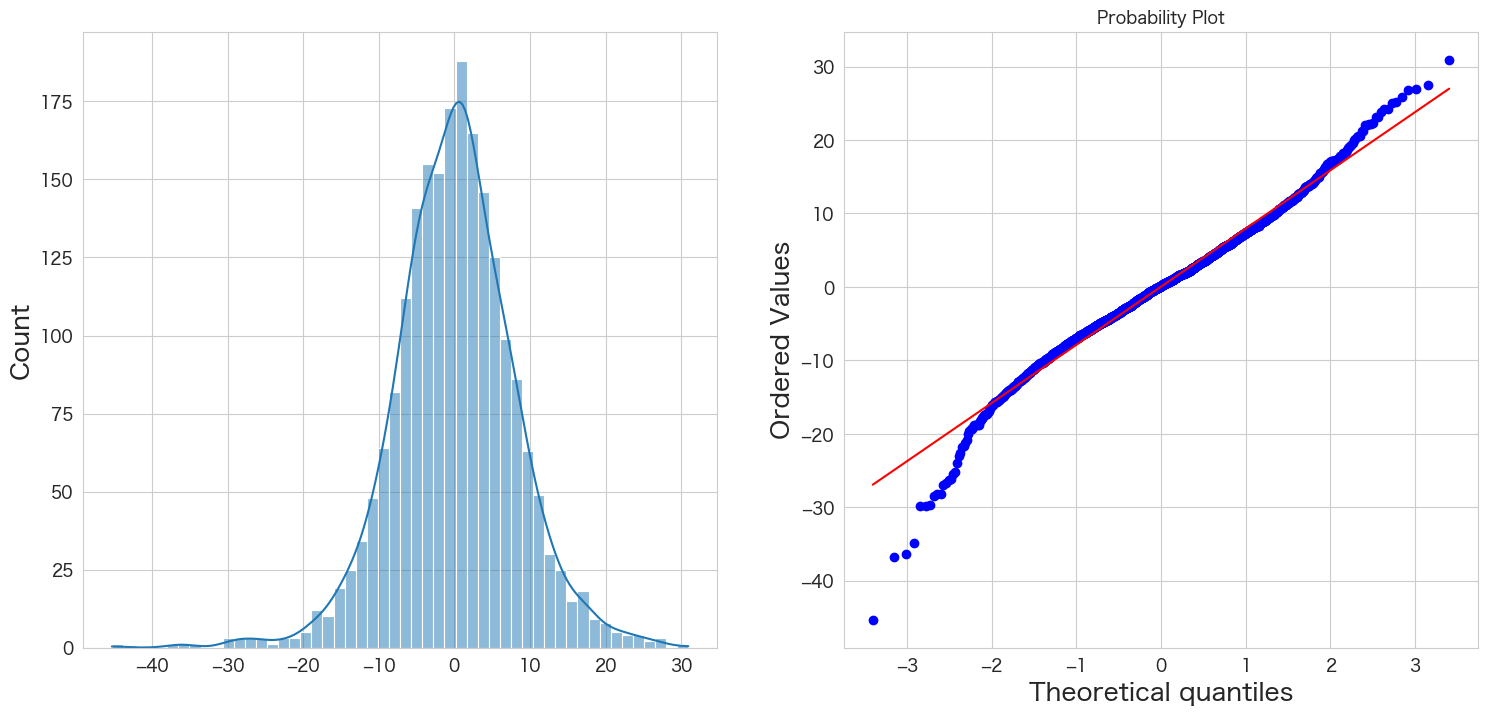
概ね正規分布に従っていそうです。
自己相関係数の確認
# 自己相関係数の確認
import pandas as pd
import matplotlib.pyplot as plt
from statsmodels.graphics.tsaplots import plot_acf
import numpy as np
fig, ax = plt.subplots(figsize=(16,8))
plot_acf(resid, lags=50, zero=False, title="自己相関係数 (autocorrelation)", ax=ax, alpha=0.01)
plt.ylim([0,1])
plt.yticks(np.arange(0.1, 1.1, 0.1))
plt.xticks(np.arange(1, 51, 1))
plt.show()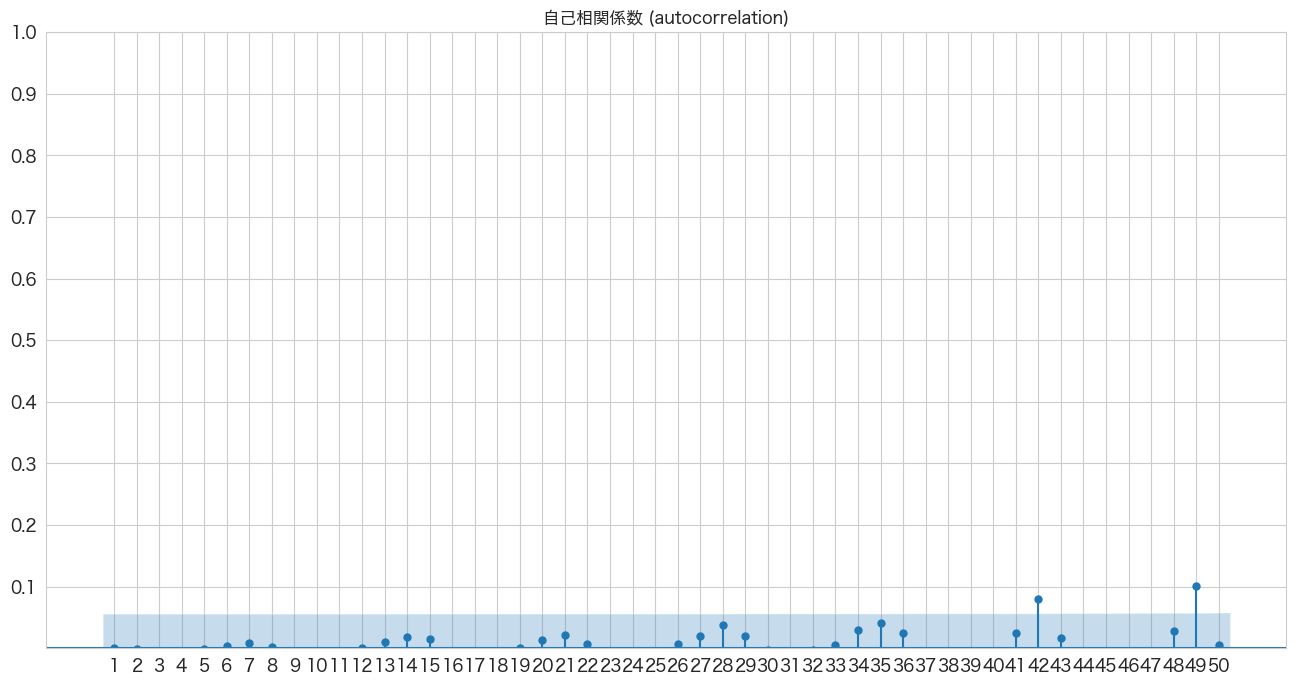
若干はみ出ている箇所はありますが、ほとんど青いエリア内なので自己相関はなさそうですね。
Ljung-Box検定で残差の独立性の確認
H0: 残差は独立分布している
HA: 残差は独立分布ではない
残差が独立分布していることが望ましいので帰無仮説を棄却しない(P値 >= 0.05)結果になることを期待したいと思います。
# https://www.statsmodels.org/stable/generated/statsmodels.stats.diagnostic.acorr_ljungbox.html
import statsmodels.api as sm
sm.stats.acorr_ljungbox(resid,lags=50)
lb_stat lb_pvalue 1 0.000078 0.992973 2 0.003568 0.998217 3 0.044528 0.997534 4 0.078841 0.999243 5 0.081553 0.999902 6 0.115631 0.999969 7 0.252315 0.999944 8 0.269251 0.999988 9 0.347259 0.999994 10 0.757735 0.999952 11 0.964442 0.999958 12 0.966976 0.999988 13 1.195472 0.999989 14 1.952781 0.999928 15 2.472935 0.999881 16 2.515608 0.999949 17 2.646262 0.999972 18 2.738052 0.999986 19 2.739405 0.999995 20 3.125121 0.999994 21 4.045260 0.999978 22 4.126641 0.999989 23 4.455245 0.999990 24 5.323920 0.999977 25 5.669950 0.999980 26 5.757076 0.999989 27 6.645206 0.999978 28 9.569854 0.999541 29 10.471284 0.999370 30 10.486461 0.999631 31 10.590115 0.999766 32 10.603301 0.999867 33 10.658329 0.999921 34 12.636471 0.999686 35 16.191105 0.997236 36 17.490401 0.995997 37 18.087330 0.996202 38 19.060069 0.995574 39 20.660511 0.993022 40 22.055875 0.990474 41 23.327631 0.988012 42 37.115473 0.684949 43 37.691263 0.700257 44 38.525889 0.704629 45 42.106093 0.595266 46 50.459860 0.301610 47 50.546285 0.335285 48 52.258628 0.312054 49 74.432114 0.011039 50 74.493315 0.013920
1~50のラグで検定してみました。ラグ48まではP値が0.05以上なので帰無仮説を棄却できず残差は独立分布ではないとは言えないという結果になりました。
残差分析の結果
残差分析の結果は、MA(39)の残差が平均0の正規分布に従い、かつ残差の間にはラグ48まで相関がありませんでしたので良しとします。
MA(39)モデルを使って引っ越し数を予測する
やっとここまで来ました。作成したMAモデルで引っ越し数を予測したいと思います。
# 2016-04-01 ~ 2017-03-31までの階差を予測
best_ma_model_fit.predict(start = df_test.index[0],end = df_test.index[-1]).plot()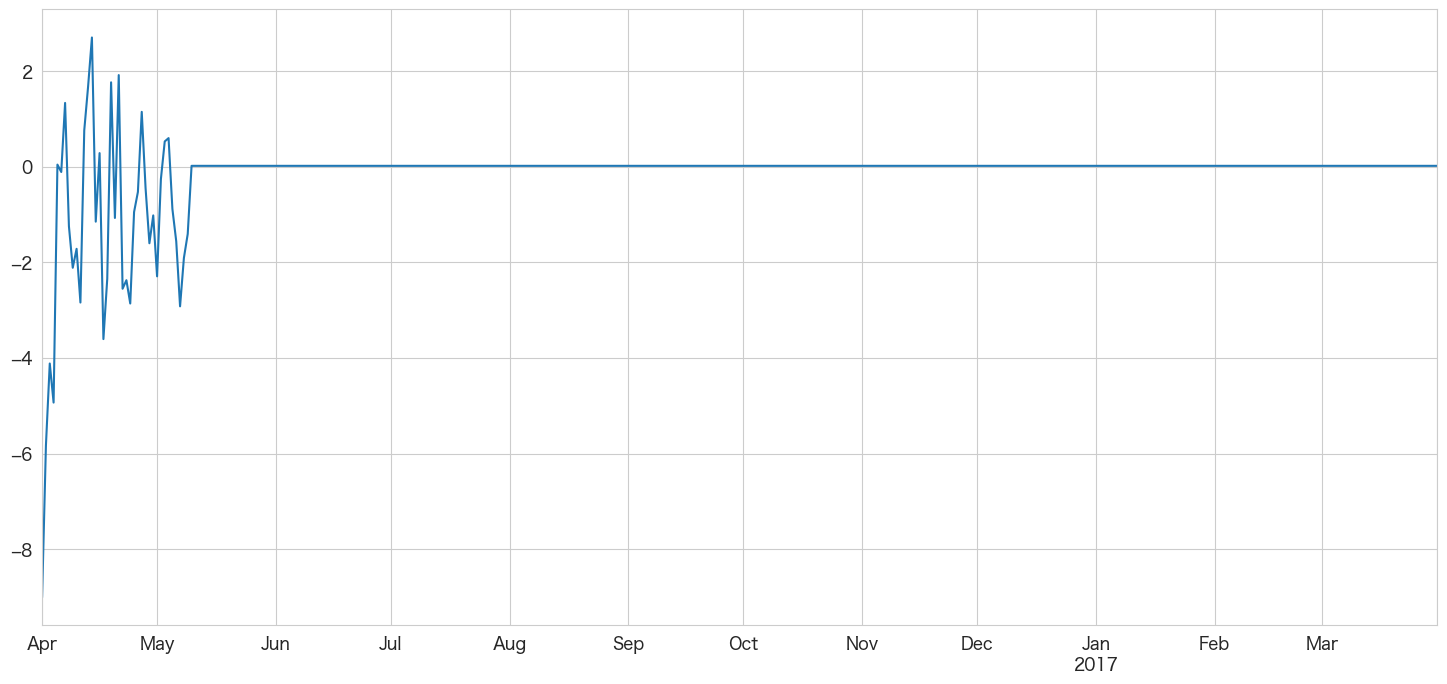
未来の日付が後ろの方になるにつれ予測値が0に近づいてきますね。あまり長い期間の予測には向いていないのかもしれません。月次で12ヶ月先までの予測などに利用した方がいいかも?
上記のグラフは階差の予測なので2016-03-31の引っ越し数から順に足していけば予測値になりそうです。
# 学習データの一番最後の引っ越し数を確認
df.iloc[-1]y 105 client 1 close 0 price_am 5 price_pm 4 Name: 2016-03-31 00:00:00, dtype: int64
yの値を使います。
predict_diff = best_ma_model_fit.predict(start = df_test.index[0],end = df_test.index[-1])
predict_diff.head(50)2016-04-01 -9.008923 2016-04-02 -5.828605 2016-04-03 -4.115716 2016-04-04 -4.932919 2016-04-05 0.043915 2016-04-06 -0.110975 2016-04-07 1.333777 2016-04-08 -1.244749 2016-04-09 -2.113211 2016-04-10 -1.717537 2016-04-11 -2.840702 2016-04-12 0.760685 2016-04-13 1.674085 2016-04-14 2.702530 2016-04-15 -1.149339 2016-04-16 0.284373 2016-04-17 -3.605049 2016-04-18 -2.342912 2016-04-19 1.764765 2016-04-20 -1.071857 2016-04-21 1.915940 2016-04-22 -2.552469 2016-04-23 -2.373760 2016-04-24 -2.860891 2016-04-25 -0.947279 2016-04-26 -0.527892 2016-04-27 1.147196 2016-04-28 -0.447842 2016-04-29 -1.600789 2016-04-30 -1.018565 2016-05-01 -2.293113 2016-05-02 -0.258122 2016-05-03 0.528121 2016-05-04 0.598058 2016-05-05 -0.883219 2016-05-06 -1.560358 2016-05-07 -2.920080 2016-05-08 -1.909093 2016-05-09 -1.406181 2016-05-10 0.018087 2016-05-11 0.018087 2016-05-12 0.018087 2016-05-13 0.018087 2016-05-14 0.018087 2016-05-15 0.018087 2016-05-16 0.018087 2016-05-17 0.018087 2016-05-18 0.018087 2016-05-19 0.018087 2016-05-20 0.018087 Freq: D, Name: predicted_mean, dtype: float64
ARモデルの時はまだ変化があったのですが、39次のMAモデルだと39日目までしか予測っぽいことがされませんでした。これでは365日の予測は難しそうです。
y_pred = df.y.iloc[-1]
y_pred_list = []
for idx,val in enumerate(predict_diff):
y_pred_list.append((y_pred + val))
# テストデータに予測結果を追加
df_test["y_pred"] = y_pred_listplt.figure(figsize=(20, 3))
ytrue = df.y.iloc[-31:]
ypred = df_test.y_pred
plt.plot(ytrue, label="Training Data")
plt.plot(ypred, label="Forecasts")
plt.title("apple-hikkoshi prediction")
_ = plt.legend()
39日目以降は横一直線になってしまい予測できていません。またしてもこれでは予測精度を確認しても意味がないので本記事ではここまでの確認とします。
まとめ
MAモデルでも1年分の日別予測は難しかったです。
次はARとMAを組み合わせたARMAモデルを試してみたいと思います。
本記事で利用したライブラリのバージョン
import pandas as pd
import numpy as np
import statsmodels as sm
import matplotlib as mpl
import pymannkendall as mk
import scipy as scp
print('pandas',pd.__version__)
print('numpy',np.__version__)
print('statsmodels',sm.__version__)
print('matplotlib',mpl.__version__)
print('pymannkendall',mk.__version__)
print('scipy',scp.__version__)pandas 1.4.3 numpy 1.23.2 statsmodels 0.13.2 matplotlib 3.5.3 pymannkendall 1.4.2 scipy 1.9.1

