今回はauto-sklearnを試してみたいと思います。
バージョンは0.14.7でまだ22年8月現在は最新版をインストール済みですので、アップグレードはしません。
MacでAutoMLの環境をする方法は下記記事にまとめています。pipでインストールしているのがほとんどですので、Linuxでも同じようなコードでインストールできるかと思います。
※ brew install しているのは yum や apt に置き換える必要はあります。
(MLJAR) Pythonで3つのAutoML環境を用意してみた
(AutoGluon) Pythonで3つのAutoML環境を用意してみた
(auto-sklearn) Pythonで3つのAutoML環境を用意してみた
それではやってみます。
評価指標
住宅IdごとのSalePrice(販売価格)を予測するコンペです。
評価指標は予測SalePriceと実測SalePriceの対数を取ったRoot-Mean-Squared-Error(RMSE)の値のようです。

auto-sklearn
分析用データの準備
事前に欠損値処理や特徴量エンジニアリングを実施してデータをエクスポートしています。
本記事と同じ結果にするためには事前に下記記事を確認してデータを用意してください。
(その3-2) エイムズの住宅価格のデータセットのデータ加工①
(その3-3) エイムズの住宅価格のデータセットのデータ加工②
学習用データとスコア付与用データの読み込み
import pandas as pd
import numpy as np
# エイムズの住宅価格のデータセットの訓練データとテストデータを読み込む
df = pd.read_csv("/Users/hinomaruc/Desktop/blog/dataset/ames/ames_train.csv")
df_test = pd.read_csv("/Users/hinomaruc/Desktop/blog/dataset/ames/ames_test.csv")# 描画設定
import seaborn as sns
from matplotlib import ticker
import matplotlib.pyplot as plt
sns.set_style("whitegrid")
from matplotlib import rcParams
rcParams['font.family'] = 'Hiragino Sans' # Macの場合
#rcParams['font.family'] = 'Meiryo' # Windowsの場合
#rcParams['font.family'] = 'VL PGothic' # Linuxの場合
rcParams['xtick.labelsize'] = 12 # x軸のラベルのフォントサイズ
rcParams['ytick.labelsize'] = 12 # y軸のラベルのフォントサイズ
rcParams['axes.labelsize'] = 18 # ラベルのフォントとサイズ
rcParams['figure.figsize'] = 18,8 # 画像サイズの変更(inch)# 説明変数と目的変数を指定
# 学習データ
X_train = df.drop(["Id","SalePrice"],axis=1)
Y_train = df["SalePrice"] # 販売価格
# テストデータ
X_test = df_test.drop(["Id"],axis=1)auto-sklearnでモデルの作成
# https://automl.github.io/auto-sklearn/master/examples/20_basic/example_regression.html
# https://automl.github.io/auto-sklearn/master/api.html
# auto-sklearnのregressionモデルの作成
import autosklearn.regression
automl = autosklearn.regression.AutoSklearnRegressor(
time_left_for_this_task=120,
per_run_time_limit=30,
tmp_folder='autosklearn_regression_ames',
)
automl.fit(X_train, Y_train, dataset_name='ames')/Users/hinomaruc/Desktop/blog/venv-autosklearn/lib/python3.8/site-packages/autosklearn/metalearning/metalearning/meta_base.py:68: FutureWarning: The frame.append method is deprecated and will be removed from pandas in a future version. Use pandas.concat instead.
self.metafeatures = self.metafeatures.append(metafeatures)
/Users/hinomaruc/Desktop/blog/venv-autosklearn/lib/python3.8/site-packages/autosklearn/metalearning/metalearning/meta_base.py:72: FutureWarning: The frame.append method is deprecated and will be removed from pandas in a future version. Use pandas.concat instead.
self.algorithm_runs[metric].append(runs)
AutoSklearnRegressor(per_run_time_limit=30, time_left_for_this_task=120,
tmp_folder='autosklearn_regression_ames')
AutoSklearnRegressor(per_run_time_limit=30, time_left_for_this_task=120,
tmp_folder='autosklearn_regression_ames')
# 学習データの精度を確認。テストデータへの精度が確認できないので参考程度
print("train",automl.score(X_train,Y_train))train 0.9487616655929721
print(automl.leaderboard())
rank ensemble_weight type cost duration
model_id
2 1 0.92 random_forest 0.090034 11.974992
6 2 0.06 ard_regression 0.160411 2.643135
8 3 0.02 liblinear_svr 0.168951 1.088582
### モデルを適用し、SalePriceの予測をする
df_test["SalePrice"] = automl.predict(X_test)df_test[["Id","SalePrice"]]
Id SalePrice 0 1461 124727.860840 1 1462 166993.297119 2 1463 184823.295898 3 1464 184942.644531 4 1465 205705.609375 ... ... ... 1454 2915 90049.703369 1455 2916 91061.872314 1456 2917 165485.618164 1457 2918 119376.864990 1458 2919 241576.075684 1459 rows × 2 columns
# SalePrice(予測) の分布を確認
sns.histplot(df_test["SalePrice"],bins=20)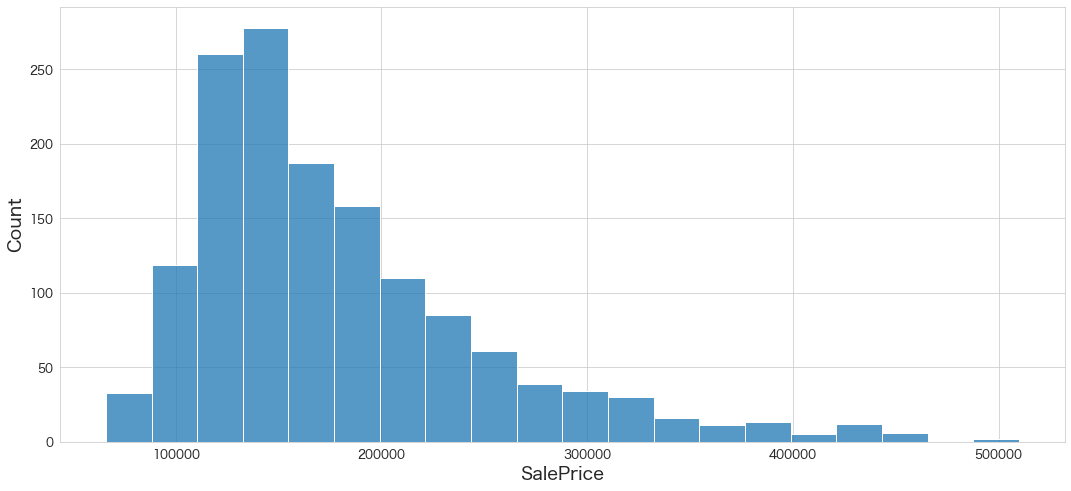
Kaggleにスコア付与結果をアップロード
df_test[["Id","SalePrice"]].to_csv("ames_submission.csv",index=False)!/Users/hinomaruc/Desktop/blog/my-venv/bin/kaggle competitions submit -c house-prices-advanced-regression-techniques -f ames_submission.csv -m "#10 automl auto-sklearn"100%|██████████████████████████████████████| 33.3k/33.3k [00:04<00:00, 7.10kB/s] Successfully submitted to House Prices - Advanced Regression Techniques #8 automl auto-sklearn Score: 0.15174
ランダムフォーレストやXGBoostよりは悪い結果になってしまいました。autogluonと同じように学習時間を伸ばせば精度はあがるかもしれません。
使用ライブラリのバージョン
pandas Version: 1.4.2
numpy Version: 1.22.4
scikit-learn Version: 0.24.2
seaborn Version: 0.11.2
matplotlib Version: 3.5.2
auto-sklearn: 0.14.7
まとめ
これで3種類すべてのautomlライブラリを試しました。mljarが一番精度がよかったです。(その分学習時間も一番かかったように思えます)
catboostとかも試してみたかったですが、一旦次の機会にすることにします。
これまで分類問題(タイタニックの生存)と回帰問題(エイムズの住宅価格)をやったので、次回からは時系列予測に入ろうかと思います。
時系列のデータは実業務でも使う機会が多いのではないでしょうか?
ARモデル、ARIMAモデル、SARIMAモデルなど分類や回帰とは少し異なる時系列用のモデルが存在するのでどういう結果になるのか楽しみです。