前回、(その3-1) エイムズの住宅価格のデータセットのデータ加工の計画ということでどう進めて行こうか計画を立てました。
今回は欠損値処理、外れ値処理、特徴量エンジニアリング① (追加変数作成、データ型変更)を実施しました。
変数選択や特徴量エンジニアリング② (ダミー変数作成)はしっかりやりたいパートなので別記事にしようと思います。
オリジナルデータの読み込み
import pandas as pd
# エイムズの住宅価格のデータセットの訓練データとテストデータを読み込む
df = pd.read_csv("/Users/hinomaruc/Desktop/blog/dataset/ames/train.csv",dtype={'MSSubClass': str})
df_test = pd.read_csv("/Users/hinomaruc/Desktop/blog/dataset/ames/test.csv",dtype={'MSSubClass': str})import seaborn as sns
# 描画設定
sns.set_style("whitegrid")
from matplotlib import rcParams
rcParams['font.family'] = 'Hiragino Sans' # Macの場合
#rcParams['font.family'] = 'Meiryo' # Windowsの場合
#rcParams['font.family'] = 'VL PGothic' # Linuxの場合
rcParams['xtick.labelsize'] = 12 # x軸のラベルのフォントサイズ
rcParams['ytick.labelsize'] = 12 # y軸のラベルのフォントサイズ
rcParams['axes.labelsize'] = 18 # ラベルのフォントとサイズ
rcParams['figure.figsize'] = 18,8 # 画像サイズの変更(inch)# 訓練データのレコード数
train_records = df.shape[0]# 訓練データとテストデータをまとめて処理するため、1つのデータフレームを作成する
df_all = pd.concat((df,df_test)).reset_index(drop=True)# 中身を確認
df_all
Id MSSubClass MSZoning LotFrontage LotArea Street Alley LotShape LandContour Utilities ... PoolArea PoolQC Fence MiscFeature MiscVal MoSold YrSold SaleType SaleCondition SalePrice 0 1 60 RL 65.0 8450 Pave NaN Reg Lvl AllPub ... 0 NaN NaN NaN 0 2 2008 WD Normal 208500.0 1 2 20 RL 80.0 9600 Pave NaN Reg Lvl AllPub ... 0 NaN NaN NaN 0 5 2007 WD Normal 181500.0 2 3 60 RL 68.0 11250 Pave NaN IR1 Lvl AllPub ... 0 NaN NaN NaN 0 9 2008 WD Normal 223500.0 3 4 70 RL 60.0 9550 Pave NaN IR1 Lvl AllPub ... 0 NaN NaN NaN 0 2 2006 WD Abnorml 140000.0 4 5 60 RL 84.0 14260 Pave NaN IR1 Lvl AllPub ... 0 NaN NaN NaN 0 12 2008 WD Normal 250000.0 ... ... ... ... ... ... ... ... ... ... ... ... ... ... ... ... ... ... ... ... ... ... 2914 2915 160 RM 21.0 1936 Pave NaN Reg Lvl AllPub ... 0 NaN NaN NaN 0 6 2006 WD Normal NaN 2915 2916 160 RM 21.0 1894 Pave NaN Reg Lvl AllPub ... 0 NaN NaN NaN 0 4 2006 WD Abnorml NaN 2916 2917 20 RL 160.0 20000 Pave NaN Reg Lvl AllPub ... 0 NaN NaN NaN 0 9 2006 WD Abnorml NaN 2917 2918 85 RL 62.0 10441 Pave NaN Reg Lvl AllPub ... 0 NaN MnPrv Shed 700 7 2006 WD Normal NaN 2918 2919 60 RL 74.0 9627 Pave NaN Reg Lvl AllPub ... 0 NaN NaN NaN 0 11 2006 WD Normal NaN 2919 rows × 81 columns
# テストデータにSalePriceカラムは含まれていないので除外
df_all = df_all.drop(["SalePrice"], axis=1)# infoメソッドで基本情報を確認
df_all.info()
RangeIndex: 2919 entries, 0 to 2918
Data columns (total 80 columns):
# Column Non-Null Count Dtype
--- ------ -------------- -----
0 Id 2919 non-null int64
1 MSSubClass 2919 non-null object
2 MSZoning 2915 non-null object
3 LotFrontage 2433 non-null float64
4 LotArea 2919 non-null int64
5 Street 2919 non-null object
6 Alley 198 non-null object
7 LotShape 2919 non-null object
8 LandContour 2919 non-null object
9 Utilities 2917 non-null object
10 LotConfig 2919 non-null object
11 LandSlope 2919 non-null object
12 Neighborhood 2919 non-null object
13 Condition1 2919 non-null object
14 Condition2 2919 non-null object
15 BldgType 2919 non-null object
16 HouseStyle 2919 non-null object
17 OverallQual 2919 non-null int64
18 OverallCond 2919 non-null int64
19 YearBuilt 2919 non-null int64
20 YearRemodAdd 2919 non-null int64
21 RoofStyle 2919 non-null object
22 RoofMatl 2919 non-null object
23 Exterior1st 2918 non-null object
24 Exterior2nd 2918 non-null object
25 MasVnrType 2895 non-null object
26 MasVnrArea 2896 non-null float64
27 ExterQual 2919 non-null object
28 ExterCond 2919 non-null object
29 Foundation 2919 non-null object
30 BsmtQual 2838 non-null object
31 BsmtCond 2837 non-null object
32 BsmtExposure 2837 non-null object
33 BsmtFinType1 2840 non-null object
34 BsmtFinSF1 2918 non-null float64
35 BsmtFinType2 2839 non-null object
36 BsmtFinSF2 2918 non-null float64
37 BsmtUnfSF 2918 non-null float64
38 TotalBsmtSF 2918 non-null float64
39 Heating 2919 non-null object
40 HeatingQC 2919 non-null object
41 CentralAir 2919 non-null object
42 Electrical 2918 non-null object
43 1stFlrSF 2919 non-null int64
44 2ndFlrSF 2919 non-null int64
45 LowQualFinSF 2919 non-null int64
46 GrLivArea 2919 non-null int64
47 BsmtFullBath 2917 non-null float64
48 BsmtHalfBath 2917 non-null float64
49 FullBath 2919 non-null int64
50 HalfBath 2919 non-null int64
51 BedroomAbvGr 2919 non-null int64
52 KitchenAbvGr 2919 non-null int64
53 KitchenQual 2918 non-null object
54 TotRmsAbvGrd 2919 non-null int64
55 Functional 2917 non-null object
56 Fireplaces 2919 non-null int64
57 FireplaceQu 1499 non-null object
58 GarageType 2762 non-null object
59 GarageYrBlt 2760 non-null float64
60 GarageFinish 2760 non-null object
61 GarageCars 2918 non-null float64
62 GarageArea 2918 non-null float64
63 GarageQual 2760 non-null object
64 GarageCond 2760 non-null object
65 PavedDrive 2919 non-null object
66 WoodDeckSF 2919 non-null int64
67 OpenPorchSF 2919 non-null int64
68 EnclosedPorch 2919 non-null int64
69 3SsnPorch 2919 non-null int64
70 ScreenPorch 2919 non-null int64
71 PoolArea 2919 non-null int64
72 PoolQC 10 non-null object
73 Fence 571 non-null object
74 MiscFeature 105 non-null object
75 MiscVal 2919 non-null int64
76 MoSold 2919 non-null int64
77 YrSold 2919 non-null int64
78 SaleType 2918 non-null object
79 SaleCondition 2919 non-null object
dtypes: float64(11), int64(25), object(44)
memory usage: 1.8+ MB
訓練データとテストデータ合わせて2919レコード存在するようです。
欠損値処理前の確認
欠損値が存在するカラムの欠損割合を確認しておきます。
# 欠損値割合の確認
chk_null = df_all.isnull().sum()
chk_null_pct = chk_null / (df_all.index.max() + 1)
chk_null_tbl = pd.concat([chk_null[chk_null > 0], chk_null_pct[chk_null_pct > 0]], axis=1)
chk_null_tbl.sort_values(by=1,ascending=False).rename(columns={0: "欠損レコード数",1: "欠損割合(missing rows / all rows)"})
欠損レコード数 欠損割合(missing rows / all rows) PoolQC 2909 0.996574 MiscFeature 2814 0.964029 Alley 2721 0.932169 Fence 2348 0.804385 FireplaceQu 1420 0.486468 LotFrontage 486 0.166495 GarageFinish 159 0.054471 GarageQual 159 0.054471 GarageCond 159 0.054471 GarageYrBlt 159 0.054471 GarageType 157 0.053786 BsmtExposure 82 0.028092 BsmtCond 82 0.028092 BsmtQual 81 0.027749 BsmtFinType2 80 0.027407 BsmtFinType1 79 0.027064 MasVnrType 24 0.008222 MasVnrArea 23 0.007879 MSZoning 4 0.001370 BsmtFullBath 2 0.000685 BsmtHalfBath 2 0.000685 Functional 2 0.000685 Utilities 2 0.000685 GarageArea 1 0.000343 GarageCars 1 0.000343 Electrical 1 0.000343 KitchenQual 1 0.000343 TotalBsmtSF 1 0.000343 BsmtUnfSF 1 0.000343 BsmtFinSF2 1 0.000343 BsmtFinSF1 1 0.000343 Exterior2nd 1 0.000343 Exterior1st 1 0.000343 SaleType 1 0.000343
事前計画で確認していたとおり、欠損が存在します。
次は欠損値を埋めるために中央値や最頻値を確認しておきます。
後から考えて見るとテストデータの情報も使うのでdata leakage(データリーケージ)と言われる問題に当てはまりそうです。
しかし、コンペではよくやる方法かつモデリングにテストデータを使うわけではないのでセーフ・・・というコメントをKaggleのサンプルノートブックで見ましたのでこのまま進めようと思います。(エイムズの訓練データとテストデータで分布の違いもあまりなさそうなのでそもそも訓練データのみに限定しても、中央値と最頻値もそこまで変わらないかも知れません。)
※ LotFrontageの欠損値処理はNeighborhoodごとのLotFrontageの中央値を利用するため、念のため訓練データのみで算出した中央値で代入しました。
# 統計情報を確認します。
df_all.describe().transpose()
count mean std min 25% 50% 75% max Id 2919.0 1460.000000 842.787043 1.0 730.5 1460.0 2189.5 2919.0 LotFrontage 2433.0 69.305795 23.344905 21.0 59.0 68.0 80.0 313.0 LotArea 2919.0 10168.114080 7886.996359 1300.0 7478.0 9453.0 11570.0 215245.0 OverallQual 2919.0 6.089072 1.409947 1.0 5.0 6.0 7.0 10.0 OverallCond 2919.0 5.564577 1.113131 1.0 5.0 5.0 6.0 9.0 YearBuilt 2919.0 1971.312778 30.291442 1872.0 1953.5 1973.0 2001.0 2010.0 YearRemodAdd 2919.0 1984.264474 20.894344 1950.0 1965.0 1993.0 2004.0 2010.0 MasVnrArea 2896.0 102.201312 179.334253 0.0 0.0 0.0 164.0 1600.0 BsmtFinSF1 2918.0 441.423235 455.610826 0.0 0.0 368.5 733.0 5644.0 BsmtFinSF2 2918.0 49.582248 169.205611 0.0 0.0 0.0 0.0 1526.0 BsmtUnfSF 2918.0 560.772104 439.543659 0.0 220.0 467.0 805.5 2336.0 TotalBsmtSF 2918.0 1051.777587 440.766258 0.0 793.0 989.5 1302.0 6110.0 1stFlrSF 2919.0 1159.581706 392.362079 334.0 876.0 1082.0 1387.5 5095.0 2ndFlrSF 2919.0 336.483727 428.701456 0.0 0.0 0.0 704.0 2065.0 LowQualFinSF 2919.0 4.694416 46.396825 0.0 0.0 0.0 0.0 1064.0 GrLivArea 2919.0 1500.759849 506.051045 334.0 1126.0 1444.0 1743.5 5642.0 BsmtFullBath 2917.0 0.429894 0.524736 0.0 0.0 0.0 1.0 3.0 BsmtHalfBath 2917.0 0.061364 0.245687 0.0 0.0 0.0 0.0 2.0 FullBath 2919.0 1.568003 0.552969 0.0 1.0 2.0 2.0 4.0 HalfBath 2919.0 0.380267 0.502872 0.0 0.0 0.0 1.0 2.0 BedroomAbvGr 2919.0 2.860226 0.822693 0.0 2.0 3.0 3.0 8.0 KitchenAbvGr 2919.0 1.044536 0.214462 0.0 1.0 1.0 1.0 3.0 TotRmsAbvGrd 2919.0 6.451524 1.569379 2.0 5.0 6.0 7.0 15.0 Fireplaces 2919.0 0.597122 0.646129 0.0 0.0 1.0 1.0 4.0 GarageYrBlt 2760.0 1978.113406 25.574285 1895.0 1960.0 1979.0 2002.0 2207.0 GarageCars 2918.0 1.766621 0.761624 0.0 1.0 2.0 2.0 5.0 GarageArea 2918.0 472.874572 215.394815 0.0 320.0 480.0 576.0 1488.0 WoodDeckSF 2919.0 93.709832 126.526589 0.0 0.0 0.0 168.0 1424.0 OpenPorchSF 2919.0 47.486811 67.575493 0.0 0.0 26.0 70.0 742.0 EnclosedPorch 2919.0 23.098321 64.244246 0.0 0.0 0.0 0.0 1012.0 3SsnPorch 2919.0 2.602261 25.188169 0.0 0.0 0.0 0.0 508.0 ScreenPorch 2919.0 16.062350 56.184365 0.0 0.0 0.0 0.0 576.0 PoolArea 2919.0 2.251799 35.663946 0.0 0.0 0.0 0.0 800.0 MiscVal 2919.0 50.825968 567.402211 0.0 0.0 0.0 0.0 17000.0 MoSold 2919.0 6.213087 2.714762 1.0 4.0 6.0 8.0 12.0 YrSold 2919.0 2007.792737 1.314964 2006.0 2007.0 2008.0 2009.0 2010.0
# 最頻値の確認
df_all.describe(include=['O']).transpose()
count unique top freq MSSubClass 2919 16 20 1079 MSZoning 2915 5 RL 2265 Street 2919 2 Pave 2907 Alley 198 2 Grvl 120 LotShape 2919 4 Reg 1859 LandContour 2919 4 Lvl 2622 Utilities 2917 2 AllPub 2916 LotConfig 2919 5 Inside 2133 LandSlope 2919 3 Gtl 2778 Neighborhood 2919 25 NAmes 443 Condition1 2919 9 Norm 2511 Condition2 2919 8 Norm 2889 BldgType 2919 5 1Fam 2425 HouseStyle 2919 8 1Story 1471 RoofStyle 2919 6 Gable 2310 RoofMatl 2919 8 CompShg 2876 Exterior1st 2918 15 VinylSd 1025 Exterior2nd 2918 16 VinylSd 1014 MasVnrType 2895 4 None 1742 ExterQual 2919 4 TA 1798 ExterCond 2919 5 TA 2538 Foundation 2919 6 PConc 1308 BsmtQual 2838 4 TA 1283 BsmtCond 2837 4 TA 2606 BsmtExposure 2837 4 No 1904 BsmtFinType1 2840 6 Unf 851 BsmtFinType2 2839 6 Unf 2493 Heating 2919 6 GasA 2874 HeatingQC 2919 5 Ex 1493 CentralAir 2919 2 Y 2723 Electrical 2918 5 SBrkr 2671 KitchenQual 2918 4 TA 1492 Functional 2917 7 Typ 2717 FireplaceQu 1499 5 Gd 744 GarageType 2762 6 Attchd 1723 GarageFinish 2760 3 Unf 1230 GarageQual 2760 5 TA 2604 GarageCond 2760 5 TA 2654 PavedDrive 2919 3 Y 2641 PoolQC 10 3 Ex 4 Fence 571 4 MnPrv 329 MiscFeature 105 4 Shed 95 SaleType 2918 9 WD 2525 SaleCondition 2919 6 Normal 2402
欠損値処理
## 下記変数は欠損値に意味がある(プールやフェンスがそもそもないなど)ので、欠損というカテゴリにする。
df_all["PoolQC"] = df_all["PoolQC"].fillna("NA")
df_all["MiscFeature"] = df_all["MiscFeature"].fillna("NA")
df_all["Alley"] = df_all["Alley"].fillna("NA")
df_all["Fence"] = df_all["Fence"].fillna("NA")
df_all["FireplaceQu"] = df_all["FireplaceQu"].fillna("NA")
df_all["GarageFinish"] = df_all["GarageFinish"].fillna("NA")
df_all["GarageQual"] = df_all["GarageQual"].fillna("NA")
df_all["GarageCond"] = df_all["GarageCond"].fillna("NA")
df_all["GarageYrBlt"] = df_all["GarageYrBlt"].fillna(0)
df_all["GarageType"] = df_all["GarageType"].fillna("NA")
df_all["BsmtExposure"] = df_all["BsmtExposure"].fillna("NA")
df_all["BsmtCond"] = df_all["BsmtCond"].fillna("NA")
df_all["BsmtQual"] = df_all["BsmtQual"].fillna("NA")
df_all["BsmtFinType2"] = df_all["BsmtFinType2"].fillna("NA")
df_all["BsmtFinType1"] = df_all["BsmtFinType1"].fillna("NA")
## 下記変数の欠損値は不明データという意味のようなので、中央値や最頻値など何かしらのロジックで補完してあげる。
df_all["MasVnrType"] = df_all["MasVnrType"].fillna("None")
df_all["MasVnrArea"] = df_all["MasVnrArea"].fillna(0)
df_all['MSZoning'] = df_all['MSZoning'].fillna("RL")
df_all["BsmtFullBath"] = df_all["BsmtFullBath"].fillna(0)
df_all["BsmtHalfBath"] = df_all["BsmtHalfBath"].fillna(0)
df_all["Functional"] = df_all["Functional"].fillna("Typ")
df_all["Utilities"] = df_all["Utilities"].fillna("AllPub")
df_all["GarageArea"] = df_all["GarageArea"].fillna(0)
df_all["GarageCars"] = df_all["GarageCars"].fillna(0)
df_all["Electrical"] = df_all["Electrical"].fillna("SBrkr")
df_all["KitchenQual"] = df_all["KitchenQual"].fillna("TA")
df_all["TotalBsmtSF"] = df_all["TotalBsmtSF"].fillna(0)
df_all["BsmtUnfSF"] = df_all["BsmtUnfSF"].fillna(0)
df_all["BsmtFinSF2"] = df_all["BsmtFinSF2"].fillna(0)
df_all["BsmtFinSF1"] = df_all["BsmtFinSF1"].fillna(0)
df_all["Exterior2nd"] = df_all["Exterior2nd"].fillna("VinylSd")
df_all["Exterior1st"] = df_all["Exterior1st"].fillna("VinylSd")
df_all["SaleType"] = df_all["SaleType"].fillna("WD")# 参考: https://stackoverflow.com/questions/63788349/filling-nan-values-in-pandas-using-train-data-statistics
# NeighbourhoodごとにLotFrontageの中央値を算出 (訓練データのみ利用)
Neighborhood_median = df.groupby("Neighborhood")["LotFrontage"].median()
# data leakageを防ぐため、訓練データのNeighborhoodのLotFrontageの中央値を算出し欠損値に代入
df_all['LotFrontage'] = df_all['LotFrontage'].fillna(df_all['Neighborhood'].map(Neighborhood_median))欠損値処理後の欠損割合確認
念のためもう一度欠損割合を出して見ます。(抜け漏れがないかどうかを確認しています。)
# 欠損値割合の確認
chk_null = df_all.isnull().sum()
chk_null_pct = chk_null / (df_all.index.max() + 1)
chk_null_tbl = pd.concat([chk_null[chk_null > 0], chk_null_pct[chk_null_pct > 0]], axis=1)
chk_null_tbl.sort_values(by=1,ascending=False).rename(columns={0: "欠損レコード数",1: "欠損割合(missing rows / all rows)"})
欠損レコード数 欠損割合(missing rows / all rows)
抜け漏れはありませんでした。
外れ値処置
外れ値疑いのある変数を前回の記事)で事前にパーセンタイルを見て洗い出しています。
LotAreaとBsmtFinSF1に関してもう少しだけ深掘りしてみようと思います。
今回はLotAreaとBsmtFinSF1に外れ値が存在するかQQプロットを確認した後に一般化ESDテストで外れ値の検定をしたいと思います。
QQプロット確認
# 正規分布に従うかどうかをQQプロットを描画して確認
import scipy.stats as stats
import matplotlib.pyplot as plt
plt.subplot(1,2,1)
sns.histplot(df_all["LotArea"], kde=True)
plt.subplot(1,2,2)
stats.probplot(df_all["LotArea"], dist="norm", plot=plt)
plt.show()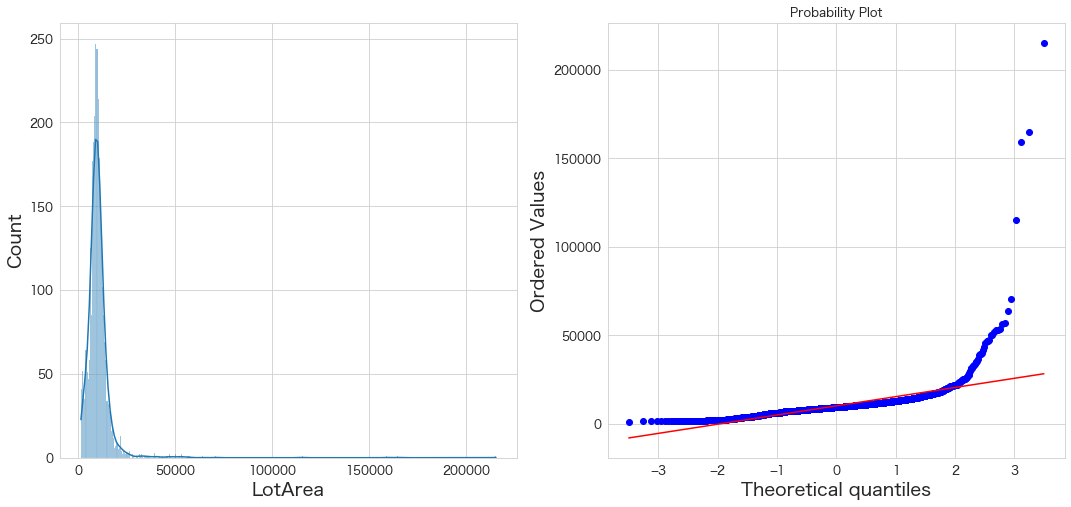
plt.subplot(1,2,1)
sns.histplot(df_all["BsmtFinSF1"], kde=True)
plt.subplot(1,2,2)
stats.probplot(df_all["BsmtFinSF1"], dist="norm", plot=plt)
plt.show()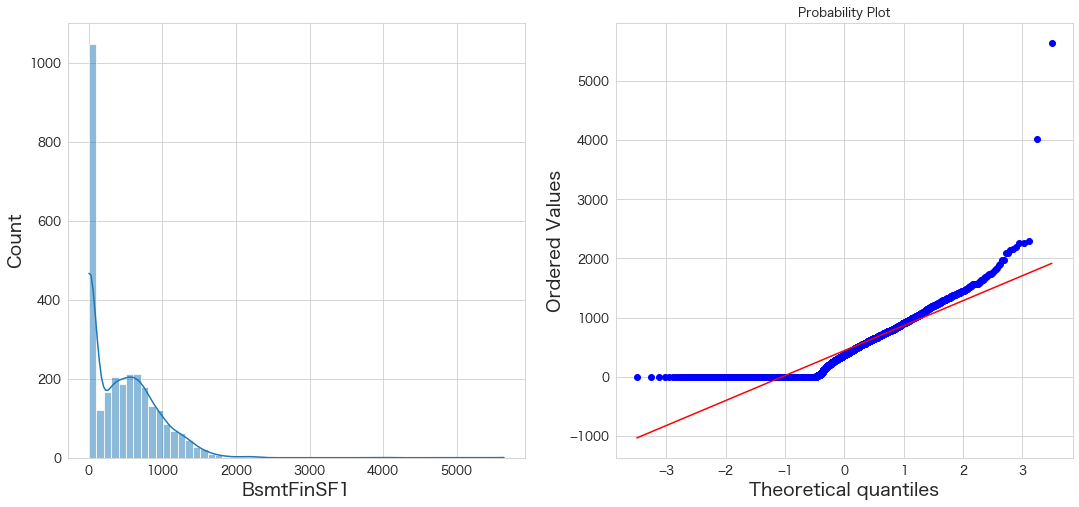
どちらも正規分布かどうかは微妙ですが、「おおよそ」正規分布かどうかが判断基準なので良しとします 笑
Generalized ESD testで外れ値検定
値が大きい上位100件に外れ値が含まれているかどうかを確認します。
# Generalized ESD test (https://www.itl.nist.gov/div898/handbook/eda/section3/eda35h3.htm)
#H0: There are no outliers in the data set
#Ha: There are up to r outliers in the data set
# arguments Y:numpy.ndarray、r:iteration num
def generalized_esd_test(Y,r):
import numpy as np
import scipy.stats as stats
# deepcopyしておく
from copy import deepcopy
X = deepcopy(Y)
# maximum iteration num
r = r
# Significance level
alpha = 0.05
# sample size
N = len(X)
# Calculate G
for i in range(1, r + 1):
print("i = ",i)
Xmean = np.mean(X)
s = np.std(X, ddof=1) # use sample std
max_diviation = max(abs(X - Xmean))
max_diviation_idx = np.argmax(abs(X - Xmean))
possible_outlier = Y[max_diviation_idx]
# G calculatedを計算
G_calculated = max_diviation / s
print("possible_outlier = ",possible_outlier,"(idx = ",str(max_diviation_idx) + ")")
# critical value of the t distribution with N-i-1 degrees of freedom and a significance level of α/2(N-i+1).
t = stats.t.ppf(1 - (alpha / (2 * (N - i + 1))), N - i - 1)
print("N=",N - i + 1)
print("t=",t,"degree of freedom=",N - i - 1)
# G criticalを計算
G_critical = (N - i) * t / np.sqrt((N - i - 1 + np.square(t)) * (N - i + 1))
print("G_calculated = ", G_calculated)
print("G_critical = ", G_critical)
if G_calculated > G_critical:
print("G_calculated > G_criticalなので帰無仮説は棄却され外れ値は存在する")
else:
print("G_calculated < G_criticalなので帰無仮説は棄却されず外れ値は存在するとは言えない")
# 外れ値と思われる値を削除し再度検定をする
X = np.delete(X,max_diviation_idx,0)
print("\n")# LotAreaで外れ値が存在するか確認
generalized_esd_test(df_all["LotArea"].sort_values().values,100)
i = 1
possible_outlier = 215245 (idx = 2918)
N= 2919
t= 4.306550766574631 degree of freedom= 2917
G_calculated = 26.001899402815667
G_critical = 4.292925364694157
G_calculated > G_criticalなので帰無仮説は棄却され外れ値は存在する
i = 2
possible_outlier = 164660 (idx = 2917)
N= 2918
t= 4.306476922671189 degree of freedom= 2916
G_calculated = 22.354964004302147
G_critical = 4.292847569321462
G_calculated > G_criticalなので帰無仮説は棄却され外れ値は存在する
i = 3
possible_outlier = 159000 (idx = 2916)
N= 2917
t= 4.306403052835418 degree of freedom= 2915
G_calculated = 23.663238180880295
G_critical = 4.292769745538434
G_calculated > G_criticalなので帰無仮説は棄却され外れ値は存在する
i = 4
possible_outlier = 115149 (idx = 2915)
N= 2916
t= 4.306329157048419 degree of freedom= 2914
G_calculated = 18.58207297550706
G_critical = 4.29269189332379
G_calculated > G_criticalなので帰無仮説は棄却され外れ値は存在する
・・・省略・・・
i = 43
possible_outlier = 26073 (idx = 2876)
N= 2877
t= 4.303426787299295 degree of freedom= 2875
G_calculated = 4.383029757221394
G_critical = 4.289633262286592
G_calculated > G_criticalなので帰無仮説は棄却され外れ値は存在する
i = 44
possible_outlier = 25485 (idx = 2875)
N= 2876
t= 4.303351838616646 degree of freedom= 2874
G_calculated = 4.242037278752227
G_critical = 4.2895542559588336
G_calculated < G_criticalなので帰無仮説は棄却されず外れ値は存在するとは言えない
・・・省略・・・
i = 100
possible_outlier = 19508 (idx = 2819)
N= 2820
t= 4.299111545040229 degree of freedom= 2818
G_calculated = 3.0470670647529547
G_critical = 4.285082538875043
G_calculated < G_criticalなので帰無仮説は棄却されず外れ値は存在するとは言えない
44件の外れ値が存在するという結果になりました。(26073ft2以上の値)
generalized_esd_test(df_all["BsmtFinSF1"].sort_values().values,100)
i = 1
possible_outlier = 5644.0 (idx = 2918)
N= 2919
t= 4.306550766574631 degree of freedom= 2917
G_calculated = 11.41935757035419
G_critical = 4.292925364694157
G_calculated > G_criticalなので帰無仮説は棄却され外れ値は存在する
i = 2
possible_outlier = 4010.0 (idx = 2917)
N= 2918
t= 4.306476922671189 degree of freedom= 2916
G_calculated = 8.016734950867887
G_critical = 4.292847569321462
G_calculated > G_criticalなので帰無仮説は棄却され外れ値は存在する
i = 3
possible_outlier = 2288.0 (idx = 2916)
N= 2917
t= 4.306403052835418 degree of freedom= 2915
G_calculated = 4.198958878597564
G_critical = 4.292769745538434
G_calculated < G_criticalなので帰無仮説は棄却されず外れ値は存在するとは言えない
・・・省略・・・
i = 100
possible_outlier = 1369.0 (idx = 2818)
N= 2820
t= 4.299111545040229 degree of freedom= 2818
G_calculated = 2.4918207914603885
G_critical = 4.285082538875043
G_calculated < G_criticalなので帰無仮説は棄却されず外れ値は存在するとは言えない
2件外れ値が存在するという結果になりました。
これはQQプロットでも2件正規分布から外れているので、確認結果とも合致しますね。
外れ値と思われるデータの確認
LotAreaの確認
HTML(df_all.query("LotArea >= 26073").sort_values(by="LotArea")[["BldgType","HouseStyle","LotFrontage","LotArea","GrLivArea","TotalBsmtSF"]].to_html())
BldgType HouseStyle LotFrontage LotArea GrLivArea TotalBsmtSF 2208 1Fam 1Story 56.0 26073 1898 1898.0 1446 1Fam 1Story 73.0 26142 1188 1188.0 692 1Fam 2Story 42.0 26178 2519 1210.0 1856 1Fam 2Story 120.0 26400 2016 0.0 934 1Fam 1Story 313.0 27650 2069 585.0 2610 1Fam 1Story 124.0 27697 1608 1396.0 828 1Fam 2Story 80.0 28698 2126 1013.0 1057 1Fam 2Story 91.0 29959 1850 973.0 1945 1Fam 1Story 65.0 31220 1474 1632.0 2904 1Fam 1Story 125.0 31250 1600 0.0 171 1Fam 1Story 141.0 31770 1656 1080.0 1190 2fmCon 1Story 73.0 32463 1622 1249.0 529 1Fam 1Story 74.0 32668 2515 2035.0 2796 1Fam 1.5Fin 90.0 33120 2486 1595.0 2607 1Fam 1Story 61.0 33983 1676 1160.0 411 2fmCon 1Story 100.0 34650 1056 1056.0 1184 1Fam 1Story 50.0 35133 1572 1572.0 1169 1Fam 2Story 118.0 35760 3627 1930.0 1287 1Fam 1Story 80.0 36500 1582 1624.0 271 1Fam 1Story 73.0 39104 1363 1385.0 2549 1Fam 1Story 128.0 39290 5095 5095.0 2617 1Fam 1Story 73.0 39384 1390 1705.0 523 1Fam 2Story 130.0 40094 4676 3138.0 2264 2fmCon 1Story 195.0 41600 1424 1100.0 2599 1Fam 1Story 200.0 43500 2034 0.0 848 1Fam 1.5Fin 75.0 45600 2358 907.0 661 1Fam 2Story 52.0 46589 2448 1629.0 2188 1Fam 1Story 123.0 47007 3820 0.0 1947 1Fam 1Story 65.0 47280 1488 1488.0 2900 1Fam 1Story 85.0 50102 1650 1632.0 53 1Fam 1Story 68.0 50271 1842 1842.0 2263 1Fam 1Story 52.0 51974 2338 2660.0 384 1Fam 2Story 80.0 53107 1953 1580.0 457 1Fam 1Story 80.0 53227 1663 1364.0 769 1Fam 2Story 47.0 53504 3279 1650.0 2250 1Fam 2.5Unf 60.0 56600 1836 686.0 1396 1Fam 1Story 85.0 57200 1687 747.0 1298 1Fam 2Story 313.0 63887 5642 6110.0 451 1Fam 1Story 62.0 70761 1533 1533.0 706 1Fam 1Story 80.0 115149 1824 1643.0 249 1Fam 1.5Fin 80.0 159000 2144 1444.0 335 2fmCon 1.5Fin 85.0 164660 1786 1499.0 313 1Fam 1Story 150.0 215245 2036 2136.0
一番広い面積の215245ft2は計算すると19996.9m2(約141m x 141m)の広さのようです。
甲子園球場のグランドが14700m2で東京ドームのグランドが13000m2なのでどれくらい広いか想像がつきますね。
しかし突拍子もなく広いかと言われるとそうでもない気がします。ですので、LotAreaは外れ値なしとしたいと思います。
BsmtFinSF1の確認
HTML(df_all.query("BsmtFinSF1 >= 2000").sort_values(by="BsmtFinSF1")[["BldgType","HouseStyle","LotFrontage","LotArea","GrLivArea","BsmtFinSF1","BsmtFinSF2","BsmtUnfSF","TotalBsmtSF"]].transpose().to_html())
2161 1182 1677 1705 898 1974 523 1663 2549 1298 BldgType 1Fam 1Fam 1Fam 1Fam 1Fam 1Fam 1Fam 1Fam 1Fam 1Fam HouseStyle 1Story 2Story 1Story 1Story 1Story 1Story 2Story 1Story 1Story 2Story LotFrontage 91.0 160.0 100.0 85.0 100.0 106.0 130.0 105.0 128.0 313.0 LotArea 11778 15623 14836 11128 12919 12720 40094 13693 39290 63887 GrLivArea 2276 4476 2492 2490 2364 2470 4676 2674 5095 5642 BsmtFinSF1 2085.0 2096.0 2146.0 2158.0 2188.0 2257.0 2260.0 2288.0 4010.0 5644.0 BsmtFinSF2 0.0 0.0 0.0 0.0 0.0 0.0 0.0 0.0 0.0 0.0 BsmtUnfSF 186.0 300.0 346.0 300.0 142.0 278.0 878.0 342.0 1085.0 466.0 TotalBsmtSF 2271.0 2396.0 2492.0 2458.0 2330.0 2535.0 3138.0 2630.0 5095.0 6110.0
上位2件が外れ値ではないかという疑いがありますが、土地面積も大きいし、住居面積(地下含めない)も大きいので地下室も巨大なのではないかと推測します。
ですので、こちらも外れ値ではないと判断しようと思います。
こういった正規分布とは中々言えないデータの場合、前回の記事でも書いたとおり特徴量エンジニアリングをする時にデータを変換してあげることによってモデルへの当てはまりをよく出来る可能性があります。
他にも数値型変数を対数変換やBox-Cox変換することにより回帰モデルへの当てはまりをよく出来る可能性もあります。(ただし偏回帰係数の意味合いが変わったりするのでモデル解釈には十分注意する必要がある。) 引用: https://www.hinomaruc.com/ames-dataset-analytics-3-1/#toc3
今回はモデリングパートで必要に応じてBox-Cox変換など試してみようと思うので、データ加工パートではスキップします。
特徴量エンジニアリング ①
下記変数を作成したいと思います。
・住居総面積 (GrLivArea + TotalBsmtSF)
・バスルーム総数 (BsmtFullBath + BsmtHalfBath + FullBath + HalfBath)
・ウッドデッキとポーチを足した総面積 (WoodDeckSF + OpenPorchSF + EnclosedPorch + 3SsnPorch + ScreenPorch)
また追加でデータ型を適切なタイプに変換し、順序型の変数は数値情報に変換しておこうと思います。
追加変数の作成
df_all['TotalLivArea'] = df_all['GrLivArea'] + df_all['TotalBsmtSF']
df_all['TotalBathRms'] = df_all['BsmtFullBath'] + df_all['BsmtHalfBath'] + df_all['FullBath'] + df_all['HalfBath']
df_all['TotalWoodDeckPorch'] = df_all['WoodDeckSF'] + df_all['OpenPorchSF'] + df_all['EnclosedPorch'] + df_all['3SsnPorch'] + df_all['ScreenPorch']データタイプ変換
# 年月をカテゴリ型に変換
# 3月より12月が優れているは通常なさそう。(1月から順に12月まで徐々に何かが良くなる/悪くなる場合は除く)
# 1999年より2000年が優れているとは限らず定量的に測れるものではない。(年々絶対良くなる/悪くなる場合は除く)
df_all['YrSold'] = df_all['YrSold'].astype(str)
df_all['MoSold'] = df_all['MoSold'].astype(str)
df_all['GarageYrBlt'] = df_all['GarageYrBlt'].astype(str)
df_all['YearBuilt'] = df_all['YearBuilt'].astype(str)
df_all['YearRemodAdd'] = df_all['YearRemodAdd'].astype(str)順序型変数の数値変換
カテゴリ型の変数を機械学習で扱える形に変換したいと思います。
具体的には下記3パターンあるかなと思います。(今回は1番の作業をやりますが、変数選択の作業後に3番もやろうと思います。)
- カテゴリの順序に優劣など意味がある場合はOrdinalEncoderを使って数値変換
- 順序型の変数でなくてもよい場合はOneHotEncoderを使って数値変換
- 目的変数がカテゴリ型で数値に変換する場合はLabelEncoderを使って数値変換
KaggleのサンプルノートブックではMSSubClassは順序型の変数として定義されているが、個人的に20番より30番の方が価値が低いのではないかと思うので順序型にはせずにダミー変数化することにしました。
20 1-STORY 1946 & NEWER ALL STYLES
30 1-STORY 1945 & OLDER
※ 海外だと古い住宅ほど価値があると聞いたことがあるため、20番の方が30番よりも価値が高い可能性もあります。実社会だと業務やデータに詳しい方に聞くのが一番かも知れません。
# 順序型の変数を数値に変換する。
from sklearn.preprocessing import OrdinalEncoder
# マップを作成。bad -> normal -> goodみたいな順番に並べています。
ordinal_maps = {
'LotShape' : ['IR3','IR2','IR1','Reg'],
'Utilities': ['ELO','NoSeWa','NoSewr','AllPub'],
'LandSlope': ['Sev','Mod','Gtl'],
'ExterQual': ['Po','Fa','TA','Gd','Ex'],
'ExterCond': ['Po','Fa','TA','Gd','Ex'],
'BsmtQual' : ['NA','Po','Fa','TA','Gd','Ex'],
'BsmtCond' : ['NA','Po','Fa','TA','Gd','Ex'],
'BsmtExposure': ['NA','No','Mn','Av','Gd'],
'BsmtFinType1': ['NA','Unf','LwQ','Rec','BLQ','ALQ','GLQ'],
'BsmtFinType2': ['NA','Unf','LwQ','Rec','BLQ','ALQ','GLQ'],
'HeatingQC' : ['Po','Fa','TA','Gd','Ex'],
'KitchenQual' : ['Po','Fa','TA','Gd','Ex'],
'Functional' : ['Sal','Sev','Maj2','Maj1','Mod','Min2','Min1','Typ'],
'FireplaceQu' : ['NA','Po','Fa','TA','Gd','Ex'],
'GarageFinish': ['NA','Unf','RFn','Fin'],
'GarageQual' : ['NA','Po','Fa','TA','Gd','Ex'],
'GarageCond' : ['NA','Po','Fa','TA','Gd','Ex'],
'PoolQC' : ['NA','Fa','TA','Gd','Ex'],
'Fence' : ['NA','MnWw','GdWo','MnPrv','GdPrv']
}
# ordinalencoderで変換
for key, val in ordinal_maps.items():
category={0:val}
ordinalEnc = OrdinalEncoder(categories = category)
df_all.loc[:,key] = ordinalEnc.fit_transform(df_all.loc[:,key].values.reshape(-1,1))作成と変換結果の確認
df_all.info()RangeIndex: 2919 entries, 0 to 2918 Data columns (total 83 columns): # Column Non-Null Count Dtype --- ------ -------------- ----- 0 Id 2919 non-null int64 1 MSSubClass 2919 non-null object 2 MSZoning 2919 non-null object 3 LotFrontage 2919 non-null float64 4 LotArea 2919 non-null int64 5 Street 2919 non-null object 6 Alley 2919 non-null object 7 LotShape 2919 non-null float64 8 LandContour 2919 non-null object 9 Utilities 2919 non-null float64 10 LotConfig 2919 non-null object 11 LandSlope 2919 non-null float64 12 Neighborhood 2919 non-null object 13 Condition1 2919 non-null object 14 Condition2 2919 non-null object 15 BldgType 2919 non-null object 16 HouseStyle 2919 non-null object 17 OverallQual 2919 non-null int64 18 OverallCond 2919 non-null int64 19 YearBuilt 2919 non-null object 20 YearRemodAdd 2919 non-null object 21 RoofStyle 2919 non-null object 22 RoofMatl 2919 non-null object 23 Exterior1st 2919 non-null object 24 Exterior2nd 2919 non-null object 25 MasVnrType 2919 non-null object 26 MasVnrArea 2919 non-null float64 27 ExterQual 2919 non-null float64 28 ExterCond 2919 non-null float64 29 Foundation 2919 non-null object 30 BsmtQual 2919 non-null float64 31 BsmtCond 2919 non-null float64 32 BsmtExposure 2919 non-null float64 33 BsmtFinType1 2919 non-null float64 34 BsmtFinSF1 2919 non-null float64 35 BsmtFinType2 2919 non-null float64 36 BsmtFinSF2 2919 non-null float64 37 BsmtUnfSF 2919 non-null float64 38 TotalBsmtSF 2919 non-null float64 39 Heating 2919 non-null object 40 HeatingQC 2919 non-null float64 41 CentralAir 2919 non-null object 42 Electrical 2919 non-null object 43 1stFlrSF 2919 non-null int64 44 2ndFlrSF 2919 non-null int64 45 LowQualFinSF 2919 non-null int64 46 GrLivArea 2919 non-null int64 47 BsmtFullBath 2919 non-null float64 48 BsmtHalfBath 2919 non-null float64 49 FullBath 2919 non-null int64 50 HalfBath 2919 non-null int64 51 BedroomAbvGr 2919 non-null int64 52 KitchenAbvGr 2919 non-null int64 53 KitchenQual 2919 non-null float64 54 TotRmsAbvGrd 2919 non-null int64 55 Functional 2919 non-null float64 56 Fireplaces 2919 non-null int64 57 FireplaceQu 2919 non-null float64 58 GarageType 2919 non-null object 59 GarageYrBlt 2919 non-null object 60 GarageFinish 2919 non-null float64 61 GarageCars 2919 non-null float64 62 GarageArea 2919 non-null float64 63 GarageQual 2919 non-null float64 64 GarageCond 2919 non-null float64 65 PavedDrive 2919 non-null object 66 WoodDeckSF 2919 non-null int64 67 OpenPorchSF 2919 non-null int64 68 EnclosedPorch 2919 non-null int64 69 3SsnPorch 2919 non-null int64 70 ScreenPorch 2919 non-null int64 71 PoolArea 2919 non-null int64 72 PoolQC 2919 non-null float64 73 Fence 2919 non-null float64 74 MiscFeature 2919 non-null object 75 MiscVal 2919 non-null int64 76 MoSold 2919 non-null object 77 YrSold 2919 non-null object 78 SaleType 2919 non-null object 79 SaleCondition 2919 non-null object 80 TotalLivArea 2919 non-null float64 81 TotalBathRms 2919 non-null float64 82 TotalWoodDeckPorch 2919 non-null int64 dtypes: float64(31), int64(22), object(30) memory usage: 1.8+ MB
まとめ
今回は欠損値処理、外れ値処理、特徴量エンジニアリング① (追加変数作成、データ型変更、順序型変数の数値変換)の作業を行いました。
次回は変数選択や特徴量エンジニアリング② (ダミー変数作成)の作業を行い分析データを出力するところまでやろうと思います。
各ライブラリのバージョン
pandas Version: 1.4.3
numpy Version: 1.22.4
scikit-learn Version: 1.1.1
seaborn Version: 0.11.2
matplotlib Version: 3.5.2
