とうとうモデリング作業になります。
ここまでが長かったですね。
タイタニックの乗客の生存有無を予測するモデルを作成しようと思います。
1:生存か0:非生存かを予測するいわゆる分類問題(Classification Problem)になります。
最初なので分類問題の基本的な手法である決定木(Decision tree)モデルから試そうと思います。
作成したモデルで生存 or 非生存を予測し、Kaggleにアップロードして精度を確認していくというプロセスを繰り返していこうと考えています。
評価指標
Metric
Your score is the percentage of passengers you correctly predict. This is known as accuracy.
引用: https://www.kaggle.com/competitions/titanic/overview/evaluation
Titanicのデータセットでは、生存有無を正確に予測できた乗客の割合(Accuracy)を評価指標とするようです。
Accuracyは TP+TN / TP+TN+FP+FN で計算できるようです。
言い換えると、(0/1に関わらず)正解を予測できた数 / 全ての数 という意味になります。
決定木分析
分析用データの準備
事前に欠損値処理や特徴量エンジニアリングを実施してデータをエクスポートしています。
本記事と同じ結果にするためには事前に下記記事を確認してデータを用意してください。
学習データと評価データの読み込み
import pandas as pd
import numpy as np
# タイタニックデータセットの学習用データと評価用データの読み込み
df_train = pd.read_csv("/Users/hinomaruc/Desktop/notebooks/titanic/titanic_train.csv")
df_eval = pd.read_csv("/Users/hinomaruc/Desktop/notebooks/titanic/titanic_eval.csv")概要確認
# 概要確認
df_train.info()
RangeIndex: 891 entries, 0 to 890
Data columns (total 22 columns):
# Column Non-Null Count Dtype
--- ------ -------------- -----
0 PassengerId 891 non-null int64
1 Survived 891 non-null int64
2 Pclass 891 non-null int64
3 Name 891 non-null object
4 Sex 891 non-null object
5 Age 891 non-null float64
6 SibSp 891 non-null int64
7 Parch 891 non-null int64
8 Ticket 891 non-null object
9 Fare 891 non-null float64
10 Cabin 204 non-null object
11 Embarked 891 non-null object
12 FamilyCnt 891 non-null int64
13 SameTicketCnt 891 non-null int64
14 Pclass_str_1 891 non-null float64
15 Pclass_str_2 891 non-null float64
16 Pclass_str_3 891 non-null float64
17 Sex_female 891 non-null float64
18 Sex_male 891 non-null float64
19 Embarked_C 891 non-null float64
20 Embarked_Q 891 non-null float64
21 Embarked_S 891 non-null float64
dtypes: float64(10), int64(7), object(5)
memory usage: 153.3+ KB
# 概要確認
df_eval.info()
RangeIndex: 418 entries, 0 to 417
Data columns (total 21 columns):
# Column Non-Null Count Dtype
--- ------ -------------- -----
0 PassengerId 418 non-null int64
1 Pclass 418 non-null int64
2 Name 418 non-null object
3 Sex 418 non-null object
4 Age 418 non-null float64
5 SibSp 418 non-null int64
6 Parch 418 non-null int64
7 Ticket 418 non-null object
8 Fare 418 non-null float64
9 Cabin 91 non-null object
10 Embarked 418 non-null object
11 Pclass_str_1 418 non-null float64
12 Pclass_str_2 418 non-null float64
13 Pclass_str_3 418 non-null float64
14 Sex_female 418 non-null float64
15 Sex_male 418 non-null float64
16 Embarked_C 418 non-null float64
17 Embarked_Q 418 non-null float64
18 Embarked_S 418 non-null float64
19 FamilyCnt 418 non-null int64
20 SameTicketCnt 418 non-null int64
dtypes: float64(10), int64(6), object(5)
memory usage: 68.7+ KB
# 描画設定
import seaborn as sns
from matplotlib import ticker
import matplotlib.pyplot as plt
sns.set_style("whitegrid")
from matplotlib import rcParams
rcParams['font.family'] = 'Hiragino Sans' # Macの場合
#rcParams['font.family'] = 'Meiryo' # Windowsの場合
#rcParams['font.family'] = 'VL PGothic' # Linuxの場合
rcParams['xtick.labelsize'] = 12 # x軸のラベルのフォントサイズ
rcParams['ytick.labelsize'] = 12 # y軸のラベルのフォントサイズ
rcParams['axes.labelsize'] = 18 # ラベルのフォントとサイズ
rcParams['figure.figsize'] = 18,8 # 画像サイズの変更(inch)モデル作成
# 決定木のモデル作成
from sklearn.tree import DecisionTreeClassifier
from sklearn.tree import plot_tree
clf = DecisionTreeClassifier(random_state=0)# 学習データを訓練データとテストデータに分割する。
from sklearn.model_selection import train_test_split
x_train, x_test = train_test_split(df_train, test_size=0.20,random_state=100)
# 説明変数
FEATURE_COLS=[
'Age'
, 'Fare'
, 'SameTicketCnt'
, 'Pclass_str_1'
, 'Pclass_str_3'
, 'Sex_female'
, 'Embarked_Q'
, 'Embarked_S'
]
X_train = x_train[FEATURE_COLS] # 説明変数 (train)
Y_train = x_train["Survived"] # 目的変数 (train)
X_test = x_test[FEATURE_COLS] # 説明変数 (test)
Y_test = x_test["Survived"] # 目的変数 (test)# 学習データから分割した訓練データをfitする
model = clf.fit(X_train,Y_train)モデル結果確認
# 決定木を描画する
plot_tree( model
, feature_names=FEATURE_COLS
, class_names=["非生存","生存"]
, filled=True, rounded=True
)[Text(0.5735625617588933, 0.9761904761904762, 'Sex_female <= 0.5\ngini = 0.469\nsamples = 712\nvalue = [445, 267]\nclass = 非生存'),
Text(0.32795516304347827, 0.9285714285714286, 'Age <= 6.5\ngini = 0.303\nsamples = 467\nvalue = [380, 87]\nclass = 非生存'),
Text(0.16946640316205533, 0.8809523809523809, 'SameTicketCnt <= 4.5\ngini = 0.42\nsamples = 20\nvalue = [6, 14]\nclass = 生存'),
・・・省略・・・
Text(0.9841897233201581, 0.7857142857142857, 'SameTicketCnt <= 4.0\ngini = 0.5\nsamples = 2\nvalue = [1, 1]\nclass = 非生存'),
Text(0.9762845849802372, 0.7380952380952381, 'gini = 0.0\nsamples = 1\nvalue = [0, 1]\nclass = 生存'),
Text(0.9920948616600791, 0.7380952380952381, 'gini = 0.0\nsamples = 1\nvalue = [1, 0]\nclass = 非生存')]
作成したモデルを描画してくれます。
ツリーが深すぎて見えないですね 笑
# 学習データを分割してできた訓練データへの当てはまりを確認
# Return the mean accuracy on the given test data and labels.
model.score(X_train,Y_train)0.9859550561797753
訓練データへの当てはまりが良すぎるのでoverfittingの可能性がありそうです。
テストデータへの当てはまりも確認します。
# 学習データを分割してできたテストデータへの当てはまりを確認
# Return the mean accuracy on the given test data and labels.
model.score(X_test,Y_test)0.7541899441340782
訓練データの精度とテストデータの精度の乖離が大きいのでオーバーフィットしていそうです。
最初なんでこんなものでしょう 汗
オーバーフィットしているとモデルの汎用性がなくなり、未知のデータへの当てはまりが悪くなる可能性があります。
# 変数重要度
feature_importances = pd.DataFrame()
# 変数名を格納
feature_importances["feature"] = model.feature_names_in_
# 重要度を格納
feature_importances["feature_importances"] = model.feature_importances_
# 重要度の降順で表示
feature_importances.sort_values(by="feature_importances", ascending=False)
feature feature_importances 5 Sex_female 0.299011 0 Age 0.262170 1 Fare 0.237589 4 Pclass_str_3 0.081600 2 SameTicketCnt 0.061893 3 Pclass_str_1 0.028035 7 Embarked_S 0.022451 6 Embarked_Q 0.007252
女性であること、年齢、運賃の重要度が高いようです。
# モデルのパラメータを表示
model.get_params()
{'ccp_alpha': 0.0,
'class_weight': None,
'criterion': 'gini',
'max_depth': None,
'max_features': None,
'max_leaf_nodes': None,
'min_impurity_decrease': 0.0,
'min_samples_leaf': 1,
'min_samples_split': 2,
'min_weight_fraction_leaf': 0.0,
'random_state': 0,
'splitter': 'best'}
デフォルト値を使いました。
random_stateだけ0に固定しています。(たしかもう一度モデリングしても同じ結果になるようなseed的なオプションだったと思います。)
# https://scikit-learn.org/stable/modules/generated/sklearn.model_selection.cross_val_score.html
# StratifiedKFold with KFold = 10
from sklearn.model_selection import cross_val_score
X = df_train[FEATURE_COLS] # 説明変数 (train)
Y = df_train["Survived"] # 目的変数 (train)
np.mean(cross_val_score(clf, X, Y, cv=10,verbose=3))
[CV] END ................................ score: (test=0.733) total time= 0.0s
[CV] END ................................ score: (test=0.820) total time= 0.0s
[CV] END ................................ score: (test=0.697) total time= 0.0s
[CV] END ................................ score: (test=0.831) total time= 0.0s
[CV] END ................................ score: (test=0.787) total time= 0.0s
[CV] END ................................ score: (test=0.787) total time= 0.0s
[CV] END ................................ score: (test=0.775) total time= 0.0s
[CV] END ................................ score: (test=0.742) total time= 0.0s
[CV] END ................................ score: (test=0.809) total time= 0.0s
[CV] END ................................ score: (test=0.775) total time= 0.0s
[Parallel(n_jobs=1)]: Using backend SequentialBackend with 1 concurrent workers.
[Parallel(n_jobs=1)]: Done 1 out of 1 | elapsed: 0.0s remaining: 0.0s
[Parallel(n_jobs=1)]: Done 2 out of 2 | elapsed: 0.0s remaining: 0.0s
[Parallel(n_jobs=1)]: Done 10 out of 10 | elapsed: 0.1s finished
0.7755805243445695
だいたい、77.5% Accuracyになるようです。
Kaggleにアップするためのデータ作成とアップロード
# Surviviedを予測し、Kaggleにアップロードするためのcsvの作成
df_eval["Survived_predicted"] = clf.predict(df_eval[FEATURE_COLS])
df_eval[["PassengerId","Survived_predicted"]].to_csv("titanic_submission.csv",index=False)# Kaggleに作成した予測ファイルをアップロード
!/Users/hinomaruc/Desktop/notebooks/my-venv/bin/kaggle competitions submit -c titanic -f titanic_submission.csv -m "model #001. my first submission using decision tree"
100%|████████████████████████████████████████| 2.21k/2.21k [00:05<00:00, 396B/s]
Successfully submitted to Titanic - Machine Learning from Disaster
check https://www.kaggle.com/competitions/titanic/submit
Kaggleのデータ提出画面を確認すると結果が確認できます。
場合によってエラーになる場合があります。
エラー構文もわかりやすいと思うので解決していきます。
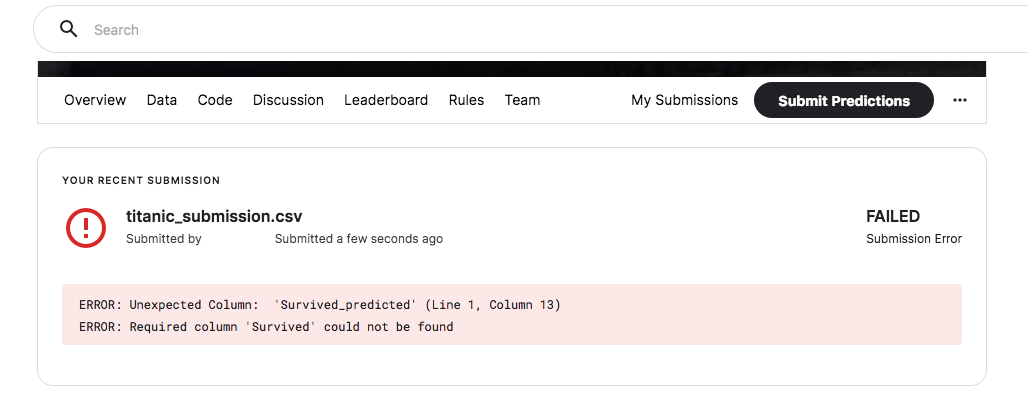
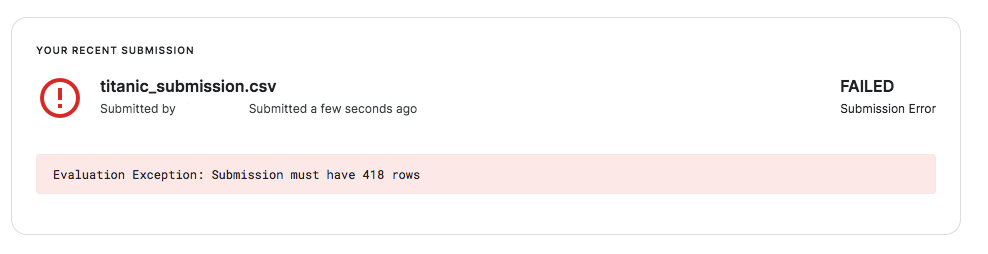
# Survived_predictedだとエラーになるので、Survivedに直したデータを作成
df_eval["Survived"] = clf.predict(df_eval[FEATURE_COLS])
df_eval[["PassengerId","Survived"]].to_csv("titanic_submission.csv",index=False)Kaggleの結果
# エラーを解決して再度アップロード
!/Users/hinomaruc/Desktop/notebooks/my-venv/bin/kaggle competitions submit -c titanic -f titanic_submission.csv -m "model #001. my first submission using decision tree"
100%|████████████████████████████████████████| 2.77k/2.77k [00:05<00:00, 549B/s]
Successfully submitted to Titanic - Machine Learning from Disaster
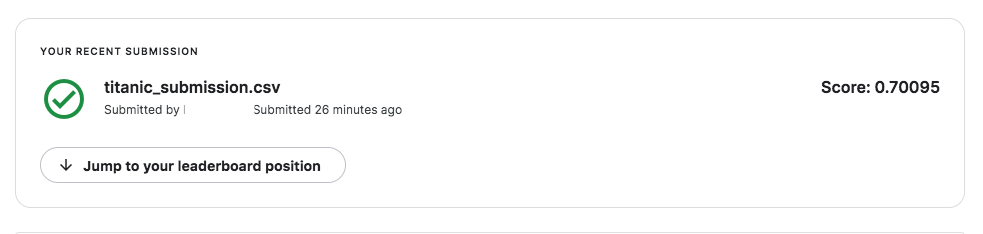
スコアは70%のようです。まずまずのスタートですね。
まとめ
決定木の結果は70%でした。
こちらの結果をベースに精度改善をしていきたいと思います。
タイタニックのコンペをみると1位は精度100%のようなので、そこまでいけるのか。。
