今日はseabornで棒グラフを作成しようと思います。
試してみましたが、大量データを表示すると重かったり、X軸がラベルで真っ黒になってしまうかと思います。
対応方法としてデータを特定条件で間引いて表示するようにしました。
今回は表示したいカラムを降順で並び替えた後、レコード数を100で割った結果分だけレコードを間引くようにしています。
1000レコードだったら1000/100で10レコードずつ飛ばして描画するようにしています。
データの読み込み
ライブラリのインポートと描画設定
import pandas as pd
import seaborn as sns
# 描画設定
sns.set_style("whitegrid")
from matplotlib import rcParams
rcParams['font.family'] = 'Hiragino Sans' # Macの場合
#rcParams['font.family'] = 'Meiryo' # Windowsの場合
#rcParams['font.family'] = 'VL PGothic' # Linuxの場合
rcParams['xtick.labelsize'] = 12 # x軸のラベルのフォントサイズ
rcParams['ytick.labelsize'] = 12 # y軸のラベルのフォントサイズ
rcParams['axes.labelsize'] = 18 # ラベルのフォrんとサイズ
rcParams['figure.figsize'] = 18,8 # 画像サイズの変更(inch)# ボストンの住宅価格データセットの読み込み
df = pd.read_csv("http://lib.stat.cmu.edu/datasets/boston_corrected.txt", encoding='Windows-1252',skiprows=9,sep="\t")# カラムの表示
df.columnsOut[0]
Index(['OBS.', 'TOWN', 'TOWN#', 'TRACT', 'LON', 'LAT', 'MEDV', 'CMEDV', 'CRIM',
'ZN', 'INDUS', 'CHAS', 'NOX', 'RM', 'AGE', 'DIS', 'RAD', 'TAX',
'PTRATIO', 'B', 'LSTAT'],
dtype='object')
追加カラムの作成
# https://stackoverflow.com/questions/19377969/combine-two-columns-of-text-in-pandas-dataframe
# X軸のラベルを作成する。連番(OBS.)だけだとわかりにくいので、連番+町名のカラムを作成した。
df["KEY"] = df['OBS.'].astype(str) + ":" + df['TOWN']追加カラムが作成できているか確認
df.head()Out[0]
OBS. TOWN TOWN# TRACT LON LAT MEDV CMEDV CRIM ZN ... NOX RM AGE DIS RAD TAX PTRATIO B LSTAT KEY 0 1 Nahant 0 2011 -70.955 42.2550 24.0 24.0 0.00632 18.0 ... 0.538 6.575 65.2 4.0900 1 296 15.3 396.90 4.98 1:Nahant 1 2 Swampscott 1 2021 -70.950 42.2875 21.6 21.6 0.02731 0.0 ... 0.469 6.421 78.9 4.9671 2 242 17.8 396.90 9.14 2:Swampscott 2 3 Swampscott 1 2022 -70.936 42.2830 34.7 34.7 0.02729 0.0 ... 0.469 7.185 61.1 4.9671 2 242 17.8 392.83 4.03 3:Swampscott 3 4 Marblehead 2 2031 -70.928 42.2930 33.4 33.4 0.03237 0.0 ... 0.458 6.998 45.8 6.0622 3 222 18.7 394.63 2.94 4:Marblehead 4 5 Marblehead 2 2032 -70.922 42.2980 36.2 36.2 0.06905 0.0 ... 0.458 7.147 54.2 6.0622 3 222 18.7 396.90 5.33 5:Marblehead 5 rows × 22 columns
seabornで棒グラフの作成 (全レコード)
import matplotlib.pyplot as plt
from matplotlib import ticker
# データをY軸で表示したいカラムの降順に並べ替え
df.sort_values(by="CMEDV",ascending=False,inplace=True)
# 描画
plt.figure()
plt.title("CMEDV vs TOWN")
g = sns.barplot(x="KEY",y="CMEDV",color="#4F81BD",data=df)
g.tick_params(axis='x', labelrotation=90)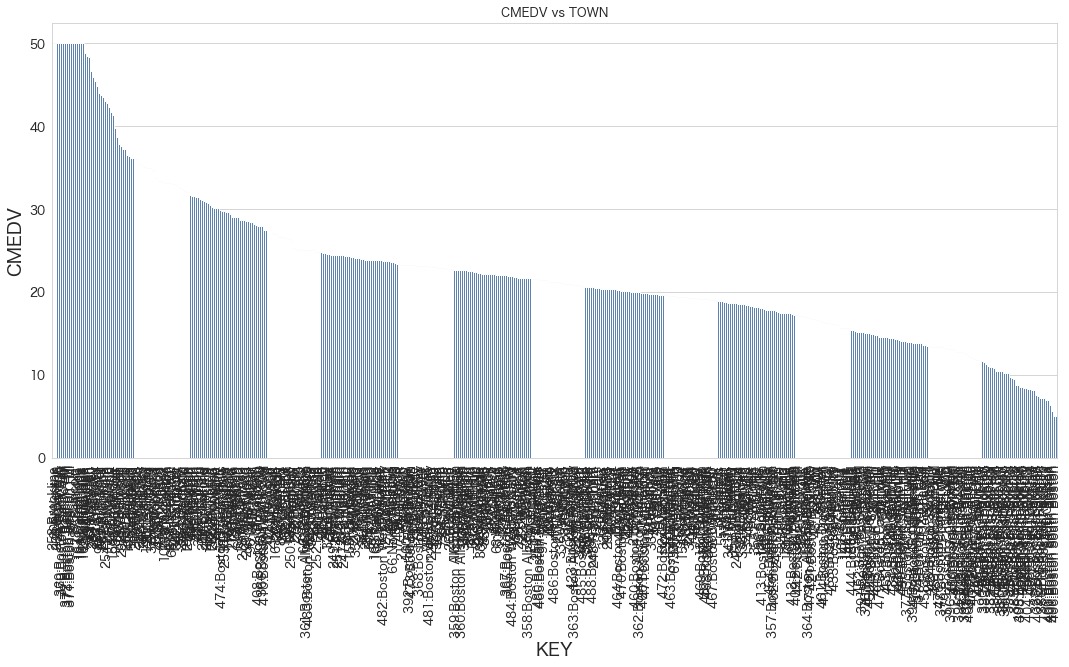
明らかに表示がおかしいですね。
描画するにも私の環境だと1分くらい待ちました。
今回は前後を比較するためにワザと綺麗に表示できないパターンを作成してみました。
seabornで棒グラフの作成 (レコードを間引いて描画)
冒頭で説明したデータを間引くパターンです。
import matplotlib.pyplot as plt
from matplotlib import ticker
# データをY軸で表示したいカラムの降順に並べ替え
df.sort_values(by="CMEDV",ascending=False,inplace=True)
# データ量が100行以上の場合は間引いて表示する
mabiki_num = df.count()[0] // 100
df_mabiki = df[::mabiki_num]
# 描画
plt.figure()
plt.title("CMEDV vs TOWN")
g = sns.barplot(x="KEY",y="CMEDV",color="#4F81BD",data=df_mabiki)
g.tick_params(axis='x', labelrotation=90, labelsize=10) #labelsize=12だと大きすぎるので10にした。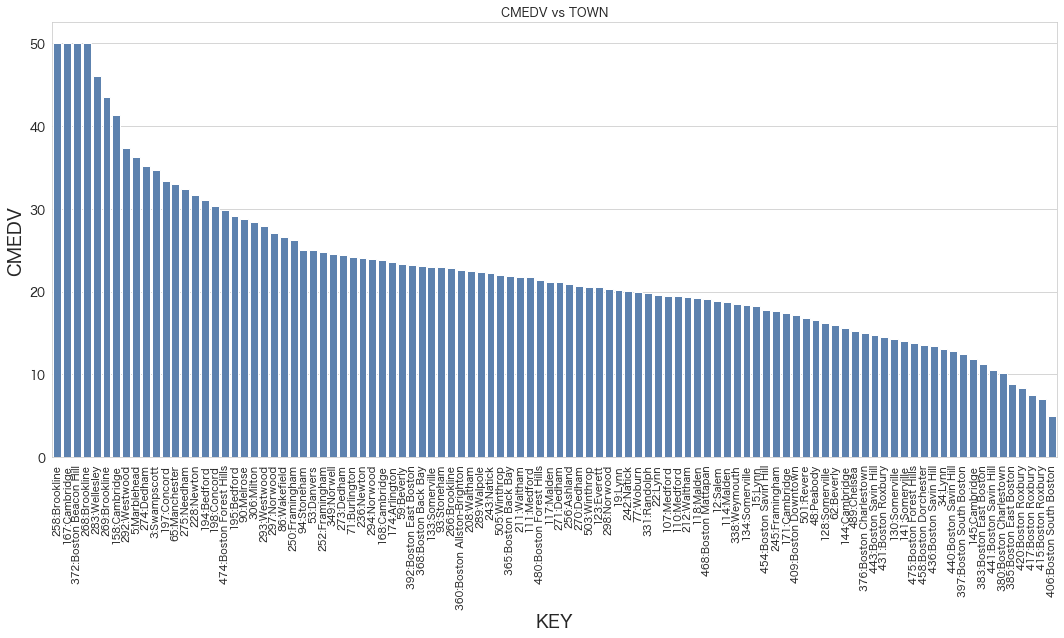
今度は綺麗に表示できました。
分布の全体感も間引いた割には変わりないように見えます。
データの特徴や傾向を捉えるためには十分そうです。