ここまでの記事でデータの読み込みから加工方法まで基本的なところを学べてきたと思います。
今回から様々なデータを使ってデータ分析をしていきたいなと思っています。
分析データの取得元の一つにKaggleというコンペサイトがあります。
APIを使ってデータを取得できるみたいなので、試してみます。
kaggle APIの利用方法は下記より確認できます。
分析のサンプルデータとして有名なTitanic(タイタニック)のデータをダウンロードしpandasに読み込むところまでやろうと思います。
kaggle.jsonをダウンロード
まずはKaggleにユーザー登録をしてあることを前提とします。
-
https://www.kaggle.com/ユーザー名/account にアクセスします。
右上のアイコンをクリックし、Accountリンクをクリックでも大丈夫です。 -
APIセクションから、Create New API Token をクリック
図: account画面
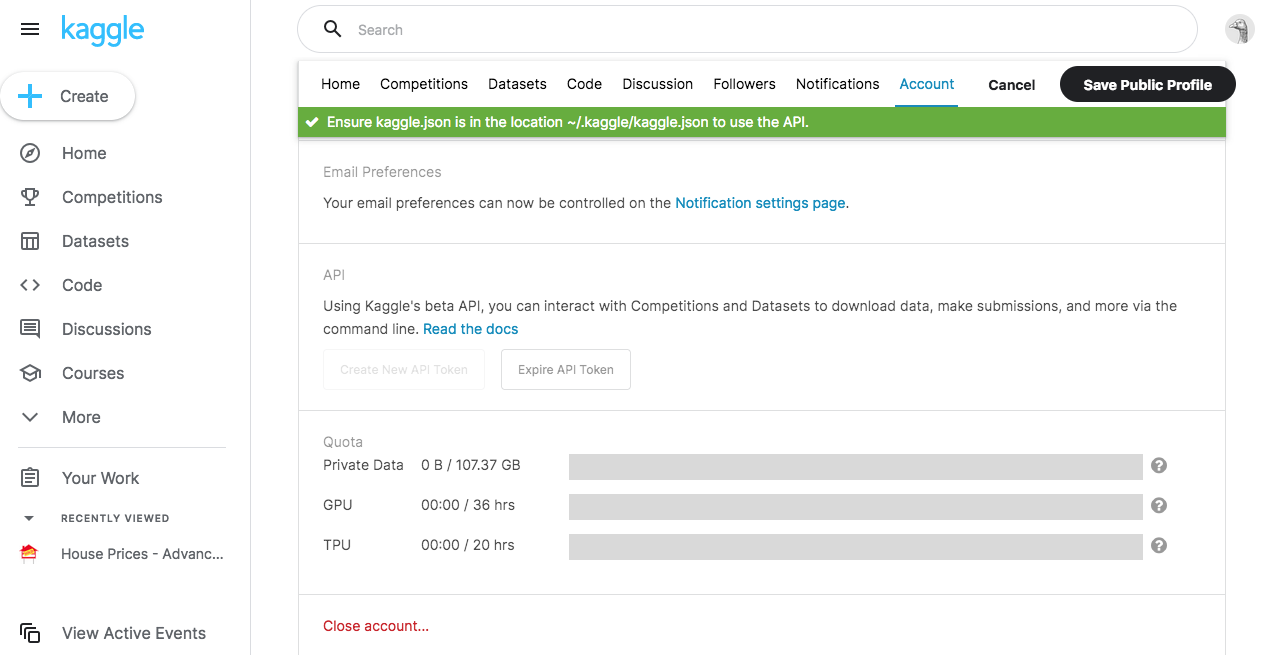
トークンを発行することによって、Kaggleのデータセットをダウンロードしたり、参加したコンペにデータ提出などをコマンドラインでできるようになります。
-
kaggle.jsonファイルがダウンロードされるので、お好きなところに保存します。
ヒノマルクはデフォルトで/Users/hinomaruc/Downloadフォルダに保存されるようになっています。
kaggle.jsonの配置
公式githubのページの通り、ホームディレクトリ以下に.kaggleフォルダを作成し、kaggle.jsonを配置しました。
他にも環境変数を設定する方法などが紹介されていますので、お好みの方法でAPIトークンを設定します。
$ mkdir ~/.kaggle
$ mv ~/Downloads/kaggle.json ~/.kaggle/
$ chmod 600 ~/.kaggle/kaggle.jsonkaggleコマンドを使ってコンペのリストやデータを確認
$ /Users/hinomaruc/Desktop/notebooks/my-venv/bin/python3 -m pip install kaggle$ source /Users/hinomaruc/Desktop/notebooks/my-venv/bin/activate(my-venv) $ kaggle
usage: kaggle [-h] [-v] {competitions,c,datasets,d,kernels,k,config} ...
kaggle: error: the following arguments are required: command
kaggleコマンドを認識しているようです。
activateで仮想環境に入らなくても、下記で仮想環境に入ってkaggleコマンドを実行しても動きます。
/Users/hinomaruc/Desktop/notebooks/my-venv/bin/kaggle(my-venv) $ kaggle competitions listref deadline category reward teamCount userHasEntered --------------------------------------------- ------------------- --------------- --------- --------- -------------- contradictory-my-dear-watson 2030-07-01 23:59:00 Getting Started Prizes 64 False gan-getting-started 2030-07-01 23:59:00 Getting Started Prizes 93 False store-sales-time-series-forecasting 2030-06-30 23:59:00 Getting Started Knowledge 743 False tpu-getting-started 2030-06-03 23:59:00 Getting Started Knowledge 164 False digit-recognizer 2030-01-01 00:00:00 Getting Started Knowledge 1891 False titanic 2030-01-01 00:00:00 Getting Started Knowledge 13981 False house-prices-advanced-regression-techniques 2030-01-01 00:00:00 Getting Started Knowledge 4438 False connectx 2030-01-01 00:00:00 Getting Started Knowledge 204 False nlp-getting-started 2030-01-01 00:00:00 Getting Started Knowledge 813 False spaceship-titanic 2030-01-01 00:00:00 Getting Started Knowledge 223 False competitive-data-science-predict-future-sales 2022-12-31 23:59:00 Playground Kudos 13651 False herbarium-2022-fgvc9 2022-05-30 23:59:00 Research Knowledge 35 False birdclef-2022 2022-05-24 23:59:00 Research $10,000 125 False h-and-m-personalized-fashion-recommendations 2022-05-09 23:59:00 Featured $50,000 882 False g-research-crypto-forecasting 2022-05-03 23:59:00 Featured $125,000 2088 False nbme-score-clinical-patient-notes 2022-05-03 23:59:00 Featured $50,000 492 False happy-whale-and-dolphin 2022-04-18 23:59:00 Research $25,000 779 False ubiquant-market-prediction 2022-04-18 23:59:00 Featured $100,000 1793 False tabular-playground-series-mar-2022 2022-03-31 23:59:00 Playground Swag 158 False womens-march-mania-2022 2022-03-18 15:00:00 Featured $25,000 193 False
今オープン中のコンペデータだけ表示されているみたいです。
下記のActive competitionsで表示されているコンペ一覧でしょうか?
Titanicコンペのデータセットをダウンロード
Kaggleの中でも非常に有名なタイタニックのデータを見てみます。
図: Titanicコンペの画面
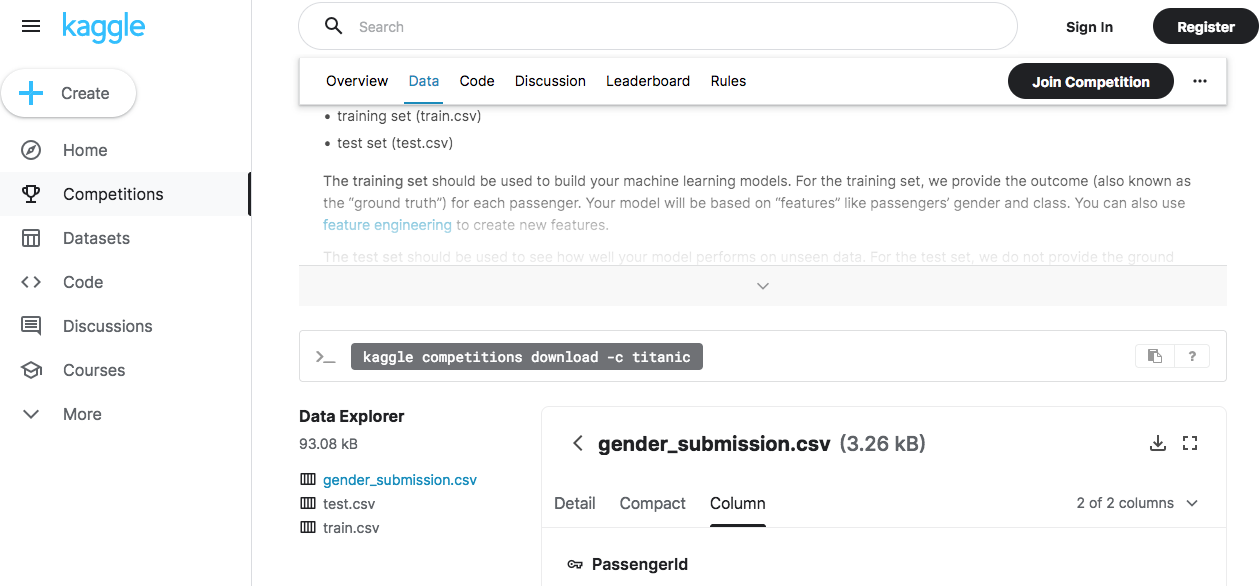
(my-venv) $ kaggle competitions files titanicname size creationDate --------------------- ---- ------------------- train.csv 60KB 2018-04-09 05:33:22 test.csv 28KB 2018-04-09 05:33:22 gender_submission.csv 3KB 2018-04-09 05:33:22
(my-venv) $ kaggle competitions download -c titanic
Downloading titanic.zip to /Users/hinomaruc/Desktop/notebooks
0%| | 0.00/34.1k [00:00<?, ?B/s]
100%|██████████| 34.1k/34.1k [00:00<00:00, 9.27MB/s]
(my-venv) $ ls | grep titanictitanic.zip
zipファイルでダウンロードが出来ました。
Titanicデータのpandasへの読み込み
zipファイルを解凍して出てきたファイルを読み込んでもいいですが、ここではTitanicコンペの学習データ(train.csv)だけをダウンロードして読み込んでみます。
せっかくなので、仮想環境にactivateで入らない方法でやります。
hinomaruc:notebooks hinomaruc$ /Users/hinomaruc/Desktop/notebooks/my-venv/bin/kaggle competitions download -f train.csv titanic
Downloading train.csv to /Users/hinomaruc/Desktop/notebooks
0%| | 0.00/59.8k [00:00<?, ?B/s]
100%|███████████| 59.8k/59.8k [00:00<00:00, 12.1MB/s]
train.csvがダウンロードできました。
import pandas as pd
df = pd.read_csv("/Users/hinomaruc/Desktop/notebooks/train.csv")df.head()
PassengerId Survived Pclass Name Sex Age SibSp Parch Ticket Fare Cabin Embarked 0 1 0 3 Braund, Mr. Owen Harris male 22.0 1 0 A/5 21171 7.2500 NaN S 1 2 1 1 Cumings, Mrs. John Bradley (Florence Briggs Th... female 38.0 1 0 PC 17599 71.2833 C85 C 2 3 1 3 Heikkinen, Miss. Laina female 26.0 0 0 STON/O2. 3101282 7.9250 NaN S 3 4 1 1 Futrelle, Mrs. Jacques Heath (Lily May Peel) female 35.0 1 0 113803 53.1000 C123 S 4 5 0 3 Allen, Mr. William Henry male 35.0 0 0 373450 8.0500 NaN S
表示できました。
まとめ
Kaggleは世界中の分析者たちがコンペで競い合っていて、分析中のコードも惜しみなくシェアされています。
ヒノマルクは今から9年前(2013年)にユーザー登録していました。
当時から盛り上がっていた記憶があります。
