どうもヒノマルクです。今日はBigQueryにPythonから接続できるようにしようと思います。google-cloud-bigqueryというライブラリを使用します。
google-cloud-bigqueryに対応しているPythonのバージョンについて
Pythonのバージョンが3.7以上、3.10以下がサポートされているようです。
(2022年9月24日現在の情報です。)
Supported Python Versions
Python >= 3.7, < 3.11
最新情報は下記ページにてご確認ください。
https://googleapis.dev/python/bigquery/latest/index.html
Python2系やPython3.5を使っている方は、google-cloud-queryのバージョン1.28.0が対応しているようなので、バージョンを指定してインストールすると良さそうです。
The last version of this library compatible with Python 2.7 and 3.5 is google-cloud-bigquery==1.28.0.
Google Cloud Platformのプロジェクト作成
まだ作成していない方は、作成しましょう。
下記記事にて、BigQuery利用環境の準備方法をまとめていますのでぜひご覧になってください。
プロジェクトの認証方法
アプリケーションからGCPのサービスを利用するためには、認証というプロセスが必要になります。
22年1月22日現在、Workload Identity連携での認証が推奨されています。今回はID連携の準備に時間がかかるので、サービスアカウントで認証します。
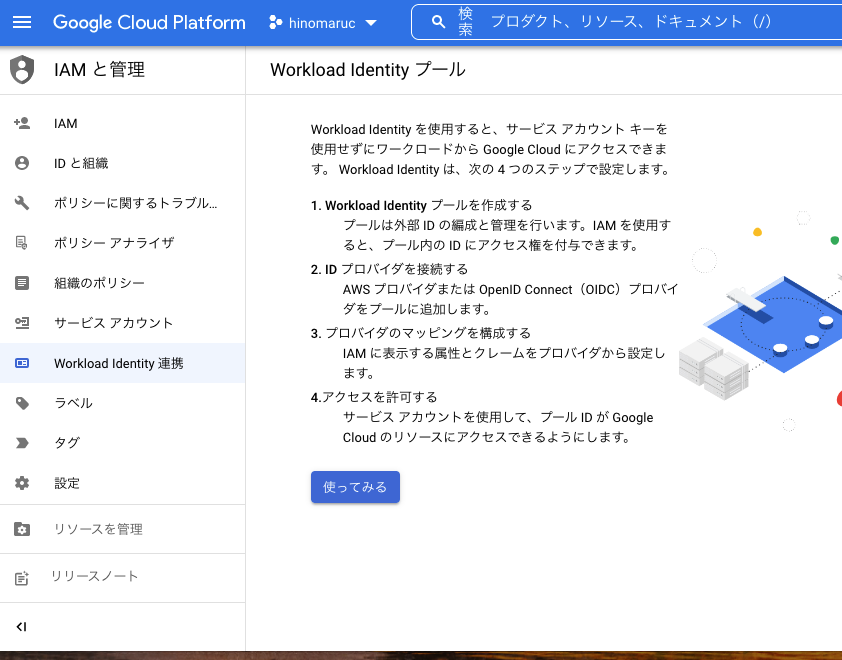
どの認証方法がよいかは、フローチャートが用意されているので確認してみてください。
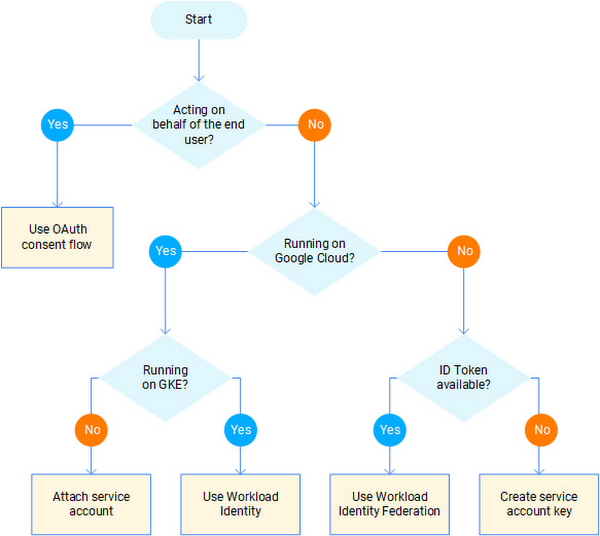
引用: Decision time
サービスアカウントキーの作成
下記公式ページに詳しく載っていますので、手順に沿って作成してください。(下のセクションでも図と共に説明していますが、公式サイトを見た方がより詳しい内容が確認できると思います。)
サービスアカウント作成手順の概要
- IAMと管理 → サービスアカウント にてサービスアカウントを作成
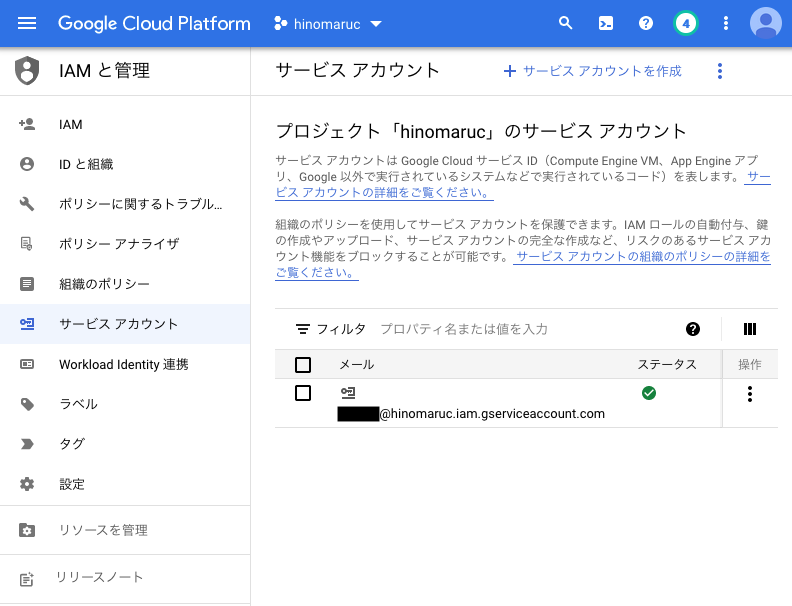
-
作成したサービスアカウントの詳細ページより、「キー」タブを選択し「鍵を追加」ボタンをクリック
-
xxxxx.jsonファイルがダウンロードされるので、任意の場所に保存します。
google-cloud-bigqueryのインストール
サービスアカウントキーが発行されたら、諸々の準備が整いました。
まずは、google-cloud-bigqueryのインストールからです。
$ /Users/hinomaruc/Desktop/notebooks/my-venv/bin/python3 -m pip install google-cloud-bigquery
Collecting google-cloud-bigquery
Downloading google_cloud_bigquery-2.32.0-py2.py3-none-any.whl (205 kB)
|████████████████████████████████| 205 kB 2.7 MB/s
Collecting google-api-core[grpc]<3.0.0dev,>=1.29.0
Downloading google_api_core-2.4.0-py2.py3-none-any.whl (111 kB)
|████████████████████████████████| 111 kB 14.1 MB/s
・・・省略・・・
Installing collected packages: pyasn1, urllib3, rsa, pyasn1-modules, protobuf, idna, charset-normalizer, certifi, cachetools, requests, grpcio, googleapis-common-protos, google-auth, grpcio-status, google-crc32c, google-api-core, proto-plus, google-resumable-media, google-cloud-core, google-cloud-bigquery
Successfully installed cachetools-4.2.4 certifi-2021.10.8 charset-normalizer-2.0.10 google-api-core-2.4.0 google-auth-2.3.3 google-cloud-bigquery-2.32.0 google-cloud-core-2.2.2 google-crc32c-1.3.0 google-resumable-media-2.1.0 googleapis-common-protos-1.54.0 grpcio-1.43.0 grpcio-status-1.43.0 idna-3.3 proto-plus-1.19.8 protobuf-3.19.3 pyasn1-0.4.8 pyasn1-modules-0.2.8 requests-2.27.1 rsa-4.8 urllib3-1.26.8
PythonからBigQueryを操作してみる
サービスアカウントキーを環境変数に設定
GOOGLE_APPLICATION_CREDENTIALSという環境変数にサービスアカウントキーを発行したときのjsonファイルを指定してあげる必要があります。
import os
os.environ['GOOGLE_APPLICATION_CREDENTIALS']="xxx.json"xxx.jsonは作成したサービスアカウントキーを指定してください。
export GOOGLE_APPLICATION_CREDENTIALS="xxx.json"上記コマンドでも設定できるようですが、ヒノマルクの環境だとpython上で環境変数を指定しないと認識してくれませんでした。
環境変数確認
%env・・・省略・・・ 'GOOGLE_APPLICATION_CREDENTIALS': 'xxx.json'
設定されているようです。
クライアントの作成
from google.cloud import BigQuery
client = bigquery.Client(project="hinomaruc")project=""はご自分のGCPのプロジェクトを指定してください。
GOOGLE_APPLICATION_CREDENTIALSが設定されていないと下記のようなエラーになります。
DefaultCredentialsError: Could not automatically determine credentials. Please set GOOGLE_APPLICATION_CREDENTIALS or explicitly create credentials and re-run the application. For more information, please see https://cloud.google.com/docs/authentication/getting-started
クエリの発行
公式サンプルのそのままです。
Googleが用意してくれている公開データにアクセスするので、そのまま利用できます。
テキサス州の人名を最大100件取得するクエリのようです。
QUERY = (
'SELECT name FROM `bigquery-public-data.usa_names.usa_1910_2013` '
'WHERE state = "TX" '
'LIMIT 100')
query_job = client.query(QUERY) # API request
rows = query_job.result() # Waits for query to finish
for row in rows:
print(row.name)Frances Alice Beatrice ・・・省略・・・ Nora Nettie Odessa
dry_runでどのくらいのデータを読み込むのかを確認
BigQueryは読み込んだデータ量分の課金になります。
(※ オンデマンド料金の場合)
その為、もし流したいクエリを実行したい場合どのくらいの容量か気になると思います。
GCPのBigQueryワークスペースでも確認できるのですが、Pythonでもdry_runオプションで確認することが出来ます。
job_config = bigquery.QueryJobConfig()
job_config.dry_run = True
query_job = client.query(QUERY,job_config=job_config)
print("This query is {} bytes.".format(query_job.total_bytes_processed))This query is 65935918 bytes.
約66MB読み込まれるという結果になりました。
毎月1TBまでは無料なので、実行しても課金される心配はなさそうです。
参照
https://cloud.google.com/docs/authentication/getting-started
https://googleapis.dev/python/bigquery/latest/index.html
https://googleapis.dev/python/bigquery/latest/usage/index.html