ちょうど昨日ですが大きいサイズのJSONのような文字列を処理する必要があったのですが、Pythonで処理するには重かったのでどう対応したのかまとめておきます。
JSONデータの文字数としては22万文字ほどになります。
最終的にjsonライブラリを使うのではなく、正規表現で必要な文字列を抽出する方式で目的達成しました。
JSON形式のデータ処理の試行錯誤のプロセスとしては下記になります。
- Jupyter notebookからimport jsonとjson.loads(JSONデータ)で読み込もうとしたがフリーズ。
- How to speed up process of loading and reading JSON files in Python?を参考にimport jsonではなく、import ujsonもしくは import orjsonを使うが変わらずフリーズ。
- jupyter notebookからではなくipythonで実行すると時間はかかるがフリーズしなかったが、JSONDecodeErrorが発生。22万文字を見直すのは辛いので他の方法を考えることになった。
JSONDecodeError: Expecting property name enclosed in double quotes: line 2 column 2 (char 2)
- 正規表現で必要な情報を抽出する方法に変更するとフリーズもしないし時間もそれほどかからず目的達成
json.loadsでデータ処理する方法も便利なので方法として記載しておきます。
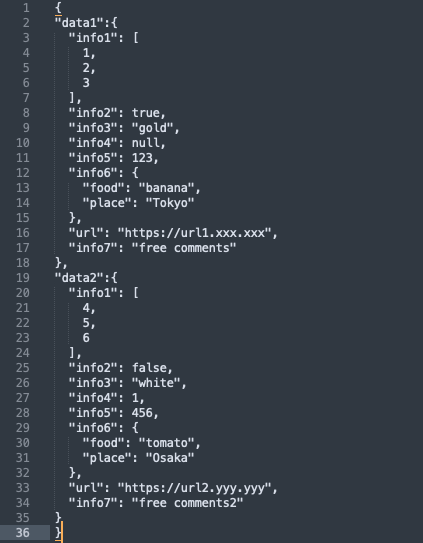
サンプルデータとして下記JSON文字列を用意しました。
タスクとしてはJSON文字列からURLの値(https://url1.xxx.xxx と https://url2.yyy.yyy) を抽出すると仮定します。
json_str="""
{
"data1":{
"info1": [
1,
2,
3
],
"info2": true,
"info3": "gold",
"info4": null,
"info5": 123,
"info6": {
"food": "banana",
"place": "Tokyo"
},
"url": "https://url1.xxx.xxx",
"info7": "free comments"
},
"data2":{
"info1": [
4,
5,
6
],
"info2": false,
"info3": "white",
"info4": 1,
"info5": 456,
"info6": {
"food": "tomato",
"place": "Osaka"
},
"url": "https://url2.yyy.yyy",
"info7": "free comments2"
}
}
"""方法1: JSONデータとして読み込んだ後に欲しい項目を取得する方法
JSONデータからURL情報を抜き出したいと思います。(https://url1.xxx.xxx と https://url2.yyy.yyy)
import json # ujsonやorjsonでもOK
json_data = json.loads(json_str)
json_data
{'data1': {'info1': [1, 2, 3],
'info2': True,
'info3': 'gold',
'info4': None,
'info5': 123,
'info6': {'food': 'banana', 'place': 'Tokyo'},
'url': 'https://url1.xxx.xxx',
'info7': 'free comments'},
'data2': {'info1': [4, 5, 6],
'info2': False,
'info3': 'white',
'info4': 1,
'info5': 456,
'info6': {'food': 'tomato', 'place': 'Osaka'},
'url': 'https://url2.yyy.yyy',
'info7': 'free comments2'}}
json_data["data1"]
{'info1': [1, 2, 3],
'info2': True,
'info3': 'gold',
'info4': None,
'info5': 123,
'info6': {'food': 'banana', 'place': 'Tokyo'},
'url': 'https://url1.xxx.xxx',
'info7': 'free comments'}
json_data["data1"]["url"]'https://url1.xxx.xxx'
for key in json_data:
print(json_data[key]["url"])https://url1.xxx.xxx https://url2.yyy.yyy
出来ました。データ量が少ない場合は分かりやすくて良い方法だと思います。
方法2: JSON形式の文字列から正規表現で目的の項目を取得する方法
正規表現で取得してみます。
正規表現で使っている(https[^"]*)の[^"]という部分はダブルクオテーション以外の文字という意味になります。
import re
# 正規表現
pattern = r'"url":\s"(https[^"]*)"'
# マッチする全ての文字列を取得
matches = re.findall(pattern, json_str)
# 中身を表示。URLに必要ない文字列が含まれていた場合はreplaceする
for i in matches:
print(i.replace('\\', ''))https://url1.xxx.xxx https://url2.yyy.yyy
取得できました。
まとめ
JSON形式のデータが大きすぎると私の環境だとjson.loads()する時点でフリーズしたり読み込みにかなり時間がかかってしまいました。
正規表現で取得することによる不具合はいまのところ起きていませんが、個人的にはjsonライブラリで取得する方が美しいので好みです 笑
