今回は「物体検知の結果表示 (bbox, instance segmentationなど)」をまとめていきたいと思います。
前回の記事はこちら
https://www.hinomaruc.com/trying-object-detection-with-yolov8/
・「Predict」は学習済みのYOLOv8モデルを画像や動画に適用し予測や推論するためのモードです。
Predictモードによって物体検知をした結果はsave=Trueパラメータを有効にすれば、デフォルトのrunsフォルダ以下やprojectパラメータで指定したフォルダへ推論結果が出力されます。save=Falseだと下記の様に推論した画像内にどのオブジェクトがどれくらい出現したかのみ返ってきます。
動きを見てみます。

from ultralytics import YOLO
from PIL import Image
import cv2
# 事前学習済みのモデルを読み込み(detectionモデルを使用)
model = YOLO('yolov8n.pt')
# predictモードを実行
results = model.predict(source="/Users/hinomaruc/Desktop/blog/dataset/aidetection/DALL·E 2023-04-04 06.11.13 - ten cats.png",
project="/Users/hinomaruc/Desktop/blog/dataset/yolov8/runs", # 出力先
name="mypredict", #フォルダ名
exist_ok=True, #上書きOKか
save=True)/Users/hinomaruc/Desktop/blog/dataset/yolov8/runs/mypredict以下に検出結果のバウンディングボックスが付与された画像が出力されると思います。
本当は5匹の猫を検知して欲しかったのですが、yolov8nモデルの精度だと2匹と検出される結果になるようです。
image 1/1 /Users/hinomaruc/Desktop/blog/dataset/aidetection/DALL·E 2023-04-04 06.11.13 - ten cats.png: 640x640 2 cats, 519.2ms Speed: 3.4ms preprocess, 519.2ms inference, 2.1ms postprocess per image at shape (1, 3, 640, 640) Results saved to /Users/hinomaruc/Desktop/blog/dataset/yolov8/runs/mypredict

save=Falseの場合はどうなるのでしょうか?確認してみました。
image 1/1 /Users/hinomaruc/Desktop/blog/dataset/aidetection/DALL·E 2023-04-04 06.11.13 - ten cats.png: 640x640 2 cats, 401.7ms Speed: 2.8ms preprocess, 401.7ms inference, 2.0ms postprocess per image at shape (1, 3, 640, 640)
save=Falseまたはsaveパラメータを入力しなかった場合は、Results saved to ~ がログに出てきません。
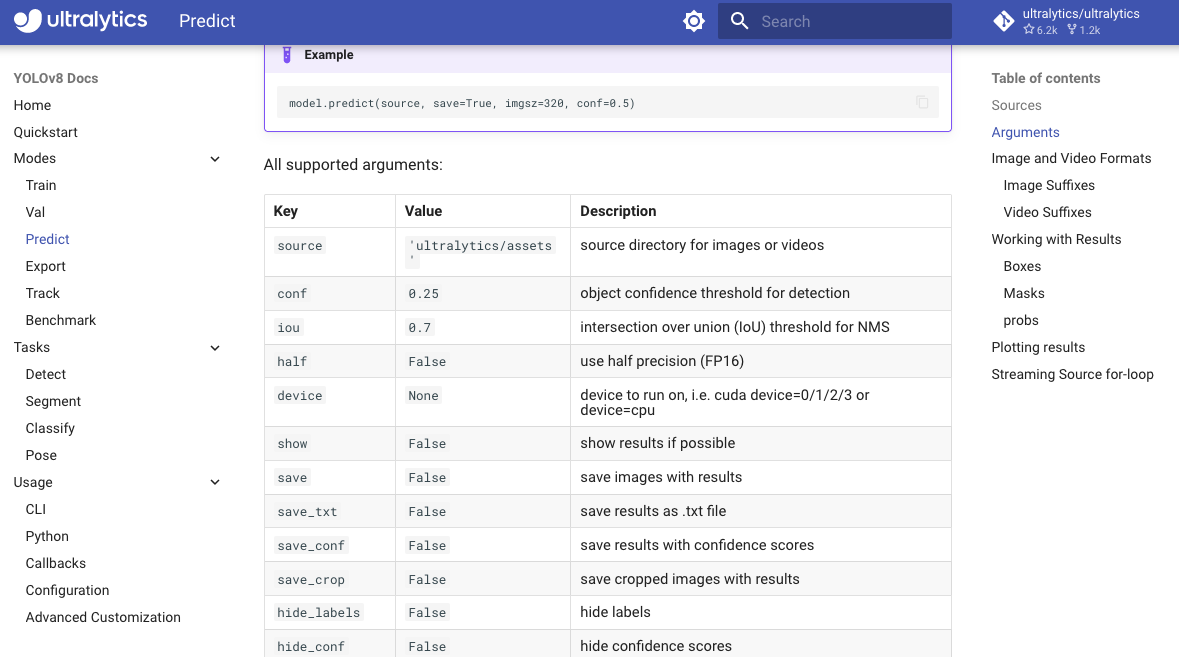
出力画像をカスタマイズしてみる (predictのパラメータ)
デフォルトの出力結果だと物足りない場合はmodel.predict()の引数にパラメータを設定してあげると、ある程度は検知結果の描画をコントロールすることが可能になります。
詳細はpredictページのArgumentsセクションに記載があります。
WARNING ⚠️ 'hide_labels' is deprecated and will be removed in 'ultralytics 8.2' in the future. Please use 'show_labels' instead.
WARNING ⚠️ 'hide_conf' is deprecated and will be removed in 'ultralytics 8.2' in the future. Please use 'show_conf' instead.
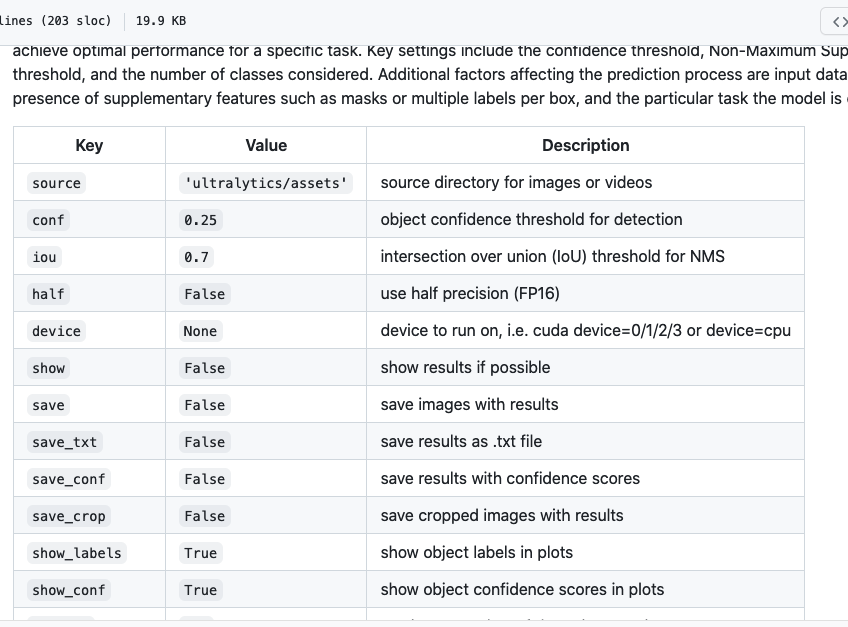
※ 追記
githubのusage.mdの方がドキュメントがアップデートされているようでpredictのオプションではshow_labelsとshow_confという記載がありました。こちらを参照した方がいいかも知れません。
それでは画像描画のカスタマイズをしてみます。
・バウンディングボックスの線を太く
・確信度0.35以下は非表示
・確信度のラベルは非表示
らへんをお試しでしてみようと思います。
results = model.predict(source="/Users/hinomaruc/Desktop/blog/dataset/aidetection/DALL·E 2023-04-04 06.11.13 - ten cats.png",
project="/Users/hinomaruc/Desktop/blog/dataset/yolov8/runs", # 出力先
name="mypredict", #フォルダ名
exist_ok=True, #上書きOKか
show_labels=True, #ラベルを表示するか
show_conf=False, #確信度を表示するか
conf=0.35, #確信度の閾値 (設定値以下は非表示)
line_thickness=10, #ラインの太さ
save=True)
あれ? show_confをFalseにしたのですが、なぜかconfが表示されてしまっています。(前動かした時は正常動作していたと思うのですが、、) 気にせず他の方法も試してみます。
→ 23/5/6追記: 本日Ultralyticsをultralytics-8.0.78からultralytics-8.0.93へアップデートしたら正常動作するようになりました。
→ 23/5/6追記: 本日Ultralyticsをアップデートしたら、line_thicknessはUltralytics8.2からdeprecatedになるようで、line_widthを使うようWarningが出ました。line_widthを使うようにしましょう。
出力画像をカスタマイズしてみる (Resultsオブジェクトのplotメソッド)
predict後に返却されるResultsオブジェクトにはplotメソッドが存在する様です。こちらでも色々いじれそうなので試してみます。
You can use plot() function of Result object to plot results on in image object. It plots all components(boxes, masks, classification logits, etc.) found in the results object
引用: https://docs.ultralytics.com/modes/predict/#plotting-results
from ultralytics import YOLO
from PIL import Image
import cv2
import matplotlib.pyplot as plt
# 事前学習済みのモデルを読み込み(detectionモデルを使用)
model = YOLO('yolov8n.pt')
# predictモードを実行
results = model.predict(source="/Users/hinomaruc/Desktop/blog/dataset/aidetection/DALL·E 2023-04-04 06.11.13 - ten cats.png",
project="/Users/hinomaruc/Desktop/blog/dataset/yolov8/runs", # 出力先
name="mypredict", #フォルダ名
exist_ok=True)
# Reusltsオブジェクトのplotメソッドでndarrayを取得
res_plotted = results[0].plot()
# matplotlibなどはRGBで表現、opencvはBGRで表現。matplotlibで描画するためRGBに変換する
res_plotted_rgb = cv2.cvtColor(res_plotted, cv2.COLOR_BGR2RGB)
# matplotlibで描画
plt.imshow(res_plotted_rgb)
plt.axis('off')
plt.show()
res_plotted = results[0].plot(conf=False
,labels=False
,line_width=10
,font_size=0.1
)
res_plotted_rgb = cv2.cvtColor(res_plotted, cv2.COLOR_BGR2RGB)
# matplotlibで描画
plt.imshow(res_plotted_rgb)
plt.axis('off')
plt.show()
confの閾値を設定して表示するバウンディングボックスを限定するといったことはResultsオブジェクトのplotメソッドだけでは出来なそうです。
plotメソッドにしかなさそうなのは、下記引数くらいでしょうか? exampleパラメータ試してみても何も変わらなかったので、詳細はもう少し確認した方が良さそうです。
font_size (float, optional)、font (str)、pil (bool)、img (numpy.ndarray)、example (str)
引用: https://docs.ultralytics.com/modes/predict/#plotting-results
次にpredictのパラメータとResultsオブジェクトのplotメソッドの両方を使ってみたいと思います。
出力画像をカスタマイズしてみる (混合バージョン)
confが0.35以下のbboxは非表示にして、confとlabelも非表示にするということをやってみようと思います。
# confが0.35以下は非表示、bboxの線を太く
results = model.predict(source="/Users/hinomaruc/Desktop/blog/dataset/aidetection/DALL·E 2023-04-04 06.11.13 - ten cats.png",
project="/Users/hinomaruc/Desktop/blog/dataset/yolov8/runs", # 出力先
name="mypredict", #フォルダ名
exist_ok=True, #上書きOKか
show_labels=True, #ラベルを表示するか
show_conf=False, #確信度を表示するか
conf=0.35, #確信度の閾値 (設定値以下は非表示)
line_thickness=10) #ラインの太さ
# confとlabelsの非表示
res_plotted = results[0].plot(conf=False, labels=False, line_width=10, font_size=0.1)
res_plotted_rgb = cv2.cvtColor(res_plotted, cv2.COLOR_BGR2RGB)
# matplotlibで描画
plt.imshow(res_plotted_rgb)
plt.axis('off')
plt.show()
検知結果を自分で描画してみる
実業務だと検知結果を要件に合わせて独自のものにしたい場合もあるかと思います。従って、model.predictやResultsオブジェクトのplotメソッドに頼らずにやってみようと思います。
Predict結果のResultsオブジェクト
predict結果はResultsオブジェクトとして返ってきます。
より柔軟な条件やレイアウトで検知結果を描画したい場合は、このResultsオブジェクトを知る必要があります。
コードではresults = model.predict()と実行しているので、results変数にResultsオブジェクトを格納しています。
predictのパラメータでstream=Falseにするかstream=onにするかで返却されるのがリストなのかジェネレーターになるのか決まる様です。
returning either a list of Results objects or a memory-efficient generator of Results objects when using the streaming mode.
引用: https://docs.ultralytics.com/modes/predict/
Tipにもありますが、streamは長時間の動画や巨大なデータソースに対して使うといい様です。out of memoryエラーなどが発生した場合はstream=Trueをパラメータとして渡してあげると改善するかも知れません。
Streaming mode with stream=True should be used for long videos or large predict sources, otherwise results will accumuate in memory and will eventually cause out-of-memory errors.
引用: https://docs.ultralytics.com/modes/predict/
Resultsオブジェクトの中身の確認
Resultsオブジェクトの結果の内容は「working-with-resultsセクション」にまとめられています。
The Results object contains the following components:
Results.boxes: Boxes object with properties and methods for manipulating bounding boxes
Results.masks: Masks object for indexing masks or getting segment coordinates
Results.probs: torch.Tensor containing class probabilities or logits
Results.orig_img: Original image loaded in memory
Results.path: Path containing the path to the input image
引用: https://docs.ultralytics.com/modes/predict
model.predictは実行済みなので、results変数の中身を確認してみます。stream=FalseのはずなのでResultsオブジェクトのリストが返ってくるはずです。
print(type(results))
print("---")
print(results)
class 'list'>
---
[ultralytics.yolo.engine.results.Results object with attributes:
_keys: ('boxes', 'masks', 'probs', 'keypoints')
boxes: ultralytics.yolo.engine.results.Boxes object
keypoints: None
keys: ['boxes']
masks: None
names: {0: 'person', 1: 'bicycle', 2: 'car', 3: 'motorcycle', 4: 'airplane', 5: 'bus', 6: 'train', 7: 'truck', 8: 'boat', 9: 'traffic light', 10: 'fire hydrant', 11: 'stop sign', 12: 'parking meter', 13: 'bench', 14: 'bird', 15: 'cat', 16: 'dog', 17: 'horse', 18: 'sheep', 19: 'cow', 20: 'elephant', 21: 'bear', 22: 'zebra', 23: 'giraffe', 24: 'backpack', 25: 'umbrella', 26: 'handbag', 27: 'tie', 28: 'suitcase', 29: 'frisbee', 30: 'skis', 31: 'snowboard', 32: 'sports ball', 33: 'kite', 34: 'baseball bat', 35: 'baseball glove', 36: 'skateboard', 37: 'surfboard', 38: 'tennis racket', 39: 'bottle', 40: 'wine glass', 41: 'cup', 42: 'fork', 43: 'knife', 44: 'spoon', 45: 'bowl', 46: 'banana', 47: 'apple', 48: 'sandwich', 49: 'orange', 50: 'broccoli', 51: 'carrot', 52: 'hot dog', 53: 'pizza', 54: 'donut', 55: 'cake', 56: 'chair', 57: 'couch', 58: 'potted plant', 59: 'bed', 60: 'dining table', 61: 'toilet', 62: 'tv', 63: 'laptop', 64: 'mouse', 65: 'remote', 66: 'keyboard', 67: 'cell phone', 68: 'microwave', 69: 'oven', 70: 'toaster', 71: 'sink', 72: 'refrigerator', 73: 'book', 74: 'clock', 75: 'vase', 76: 'scissors', 77: 'teddy bear', 78: 'hair drier', 79: 'toothbrush'}
orig_img: array([[[110, 142, 168],
[105, 130, 154],
[106, 132, 155],
...,
[127, 156, 177],
[ 95, 126, 149],
[ 82, 113, 134]],
[[102, 129, 153],
[118, 146, 167],
[128, 158, 179],
...,
[ 94, 125, 156],
[100, 132, 157],
[ 89, 122, 145]],
[[100, 128, 156],
[ 86, 112, 140],
[ 96, 124, 151],
...,
[106, 137, 166],
[104, 134, 162],
[ 90, 121, 145]],
...,
[[ 91, 107, 116],
[ 95, 110, 124],
[100, 114, 128],
...,
[255, 70, 60],
[255, 70, 60],
[255, 70, 60]],
[[ 97, 109, 119],
[102, 117, 127],
[104, 115, 133],
...,
[255, 70, 60],
[255, 70, 60],
[255, 70, 60]],
[[101, 112, 122],
[ 97, 109, 120],
[ 98, 110, 127],
...,
[255, 70, 60],
[255, 70, 60],
[255, 70, 60]]], dtype=uint8)
orig_shape: (1024, 1024)
path: '/Users/hinomaruc/Desktop/blog/dataset/aidetection/DALL·E 2023-04-04 06.11.13 - ten cats.png'
probs: None
speed: {'preprocess': 1.615762710571289, 'inference': 420.8803176879883, 'postprocess': 1.6927719116210938}]
results[0].boxes
ultralytics.yolo.engine.results.Boxes object with attributes:
boxes: tensor([[2.6777e+00, 1.2805e+02, 9.6429e+02, 9.7548e+02, 3.9142e-01, 1.5000e+01],
[5.4689e+02, 2.4734e+02, 1.0239e+03, 1.0066e+03, 3.3916e-01, 1.5000e+01]])
cls: tensor([15., 15.])
conf: tensor([0.3914, 0.3392])
data: tensor([[2.6777e+00, 1.2805e+02, 9.6429e+02, 9.7548e+02, 3.9142e-01, 1.5000e+01],
[5.4689e+02, 2.4734e+02, 1.0239e+03, 1.0066e+03, 3.3916e-01, 1.5000e+01]])
id: None
is_track: False
orig_shape: tensor([1024, 1024])
shape: torch.Size([2, 6])
xywh: tensor([[483.4832, 551.7655, 961.6110, 847.4221],
[785.3898, 626.9630, 477.0051, 759.2471]])
xywhn: tensor([[0.4722, 0.5388, 0.9391, 0.8276],
[0.7670, 0.6123, 0.4658, 0.7415]])
xyxy: tensor([[ 2.6777, 128.0545, 964.2887, 975.4766],
[ 546.8872, 247.3394, 1023.8923, 1006.5865]])
xyxyn: tensor([[0.0026, 0.1251, 0.9417, 0.9526],
[0.5341, 0.2415, 0.9999, 0.9830]])
catを2つ認識していたので、2つのテンソルが存在するようです。
confは物体がそのクラスに所属する確からしさです。0.8以下は表示しないといった場合に使えます。
clsはクラスのことで両方とも15番:catを指しています。(クラスの一覧はresults[0].namesで確認できます。)
xywhやxyxyは異なるフォーマットで同じバウンディングボックスの位置情報を表しています。
元イメージのサイズが1024px x 1024pxで、xywhのxyはバウンディングボックスの「中心点」と「縦横の長さ」を表しています。
xyxyはバウンディングボックスの「左上」と「右下」の位置を表しています。
xyxynやxywhnは正規化された数値情報になっています。例えば、xyxynの0.5341は1024pxを掛けると約546pxになります。320px x 320pxの画像に縮小していた場合、バウンディングボックスxyxyの最初のxyの位置は0.5341*320px = 170px, 0.2415x320px = 77pxの位置になります。正規化された情報の方が画像サイズを変更して学習したい場合などには有効かも知れません。
下記にフォーマットごとの位置関係を図に記載してみました。
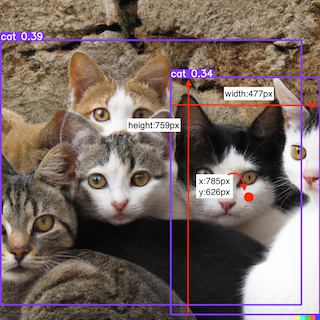

バウンディングボックスの位置情報が分かったので、これで独自の認識結果を描画する準備が整いました。
バウンディングボックスを描画してみる
自分でbboxを描画します。
import os
from ultralytics import YOLO
from PIL import Image, ImageDraw, ImageFont
from IPython.display import Image as DisplayImage
from IPython.display import display
import cv2
# 事前学習済みのモデルを読み込み(detectionモデルを使用)
model = YOLO('yolov8n.pt')
# predictモードを実行 (結果だけ欲しいので、project・name・exist_okはなくてもOK)
results = model.predict(source="/Users/hinomaruc/Desktop/blog/dataset/aidetection/DALL·E 2023-04-04 06.11.13 - ten cats.png")
# Resultsオブジェクトから描画に必要な情報を取得
coordinate_bbox = results[0].boxes.xyxy #bbox
classes=results[0].boxes.cls # 検出クラス
classes_map = results[0].names # クラス番号と名称
# 画像の読み込み
img = Image.open(results[0].path)
# 色の指定 (クラスごとにランダムに色を選択する場合使う)
# colors = ['red', 'green', 'blue', 'yellow', 'cyan', 'magenta', 'olive', 'purple']
# colors = [(255, 0, 0), (0, 255, 0), (0, 0, 255), (255, 255, 0), (0, 255, 255), (255, 0, 255), (128, 128, 0), (128, 0, 128)]
# 描画コンテントの取得
draw = ImageDraw.Draw(img)
"""
フォントの設定。Macだと/System/Library/Fontsに色々あるのでここから選んだ。
bboxだけの描画であれば必要ない。必要ない場合はdraw.text(font=font)のfont部分を消す。
エラーが出る場合はフォントファイルへのフルパス(/System/Library/Fonts/ヒラギノ丸ゴ ProN W4.ttc)で設定してあげる
"""
font = ImageFont.truetype('ヒラギノ丸ゴ ProN W4', 40)
# バウンディングボックスの描画
i=1
for bbox, cls in zip(coordinate_bbox, classes):
x1, y1, x2, y2 = map(int, bbox)
#color = colors[int(cls) % len(colors)] 今回は色を直接指定するので使わない
color=(255,0,0) # red
# bboxの描画
draw.rectangle([x1, y1, x2, y2], outline=color, width=5)
cls_text = classes_map.get(int(cls))
# 検出クラス名の描画
draw.text((x1, y1 - 50), cls_text+"#"+str(i), fill="orange",font=font)
i += 1
# 画像のリサイズ (必要であれば)
img = img.resize((640,640))
# 出力先フォルダの作成。model.predictで作成させてもOK。
directories = ['/Users/hinomaruc/Desktop/blog/dataset/yolov8/runs/mypredict']
for directory in directories:
if not os.path.exists(directory):
os.makedirs(directory)
# 画像の保存 (存在しないフォルダだとFileNotFoundErrorになるので注意)
img.save('/Users/hinomaruc/Desktop/blog/dataset/yolov8/runs/mypredict/sample_bbox.png')
# 画像の表示
display(DisplayImage(filename='/Users/hinomaruc/Desktop/blog/dataset/yolov8/runs/mypredict/sample_bbox.png'))
# 画像を保存するまでもない場合はMatplotlibで表示もできる
# PIL to ndarray
import matplotlib.pyplot as plt
img_np = np.array(img)
plt.imshow(img_np)
まとめ
いかがでしょうか? 私は凝り性なので、色々カスタマイズしたくなってしまいますね。
今回使ったのはultralytics-8.0.78になります。
(venv-yolov8) hinomaruc@myMBP blog % pip install ultralytics -U
Requirement already satisfied: ultralytics in ./venv-yolov8/lib/python3.7/site-packages (8.0.71)
・・・省略・・・
Installing collected packages: ultralytics
Attempting uninstall: ultralytics
Found existing installation: ultralytics 8.0.71
Uninstalling ultralytics-8.0.71:
Successfully uninstalled ultralytics-8.0.71
Successfully installed ultralytics-8.0.78
毎回「pip install ultralytics -U」では何かしらのマイナーアップデートがありますので、忘れずに実行することをおすすめいたします。

