ヒノマルクです。
前回の記事ではHive環境を構築しました。
今回はBigQueryを利用する環境を準備したいと思います。
最近ではHiveからBigQueryに移行したという企業や最初からBigQueryを使う前提でインフラ環境を構築している企業も少なくないと思います。
まだBigQueryを使ったことがないという方は、Googleアカウントさえあれば無料枠だけでも十分操作できますので利用してみてください。
BigQueryとは
BigQueryについては公式サイトに記載があります。
BigQuery は、機械学習、地理空間分析、ビジネスインテリジェンスなどの組み込み機能を使用してデータの管理と分析を支援する、フルマネージドのエンタープライズデータウェアハウスです。
BigQuery のスケーラブルな分散型分析エンジンを使用すると、数テラバイト、数ペタバイトのデータに対し、数秒もしくは数分でクエリを完了できます。
簡単に言い換えると、とても大きなデータでも検索するとすばやく結果が返ってくるデータウェアハウス(=~ データベース)です。
機械学習(BigQuery ML)で予測分析が行えたり、地理空間分析(BigQuery GIS)で地点間の距離を計算させたり、BIへの組み込み機能(BigQuery BI Engine)でダッシュボードの表示速度を向上させたりすることが可能です。
分析という観点ではBigQueryさえあれば何でもできるのではないかと思えます。
BigQueryを使える環境を準備する
とても簡単です。Googleアカウントさえあれば、あとは画面上でボタンを押下していくだけで利用できるようになります。
クレジットカード情報などの支払い情報は必要なく、まずはBigQueryサンドボックスで無料で使い始めることができます。
Google Cloud Platform (GCP)のプロジェクトを作成
BigQueryはGCPで利用できるサービスの1つになりますので、まずはGCPのプロジェクトを作成する必要があります。
GCPでは他にもGoogle Compute Engineというサービスでクラウド上に仮想サーバーをたてたり、Cloud SQLというサービスでデータベースを構築したりなどが可能です。
GCPのプロジェクトはトップページ経由で新規プロジェクト画面から作成する方法や、BigQueryページにアクセスしたときに表示されるプロジェクト作成リンクから作成する方法などがあります。
※ BigQueryページにプロジェクト作成リンクがでてくるのは、プロジェクトが何も存在しないか選択されていない時のみ
今回は公式のクイックスタートの通り、BigQueryページから新規プロジェクトを作成してみます。
BigQueryページを開きます。(未ログインの場合は、Googleアカウントでのログインが求められます。)
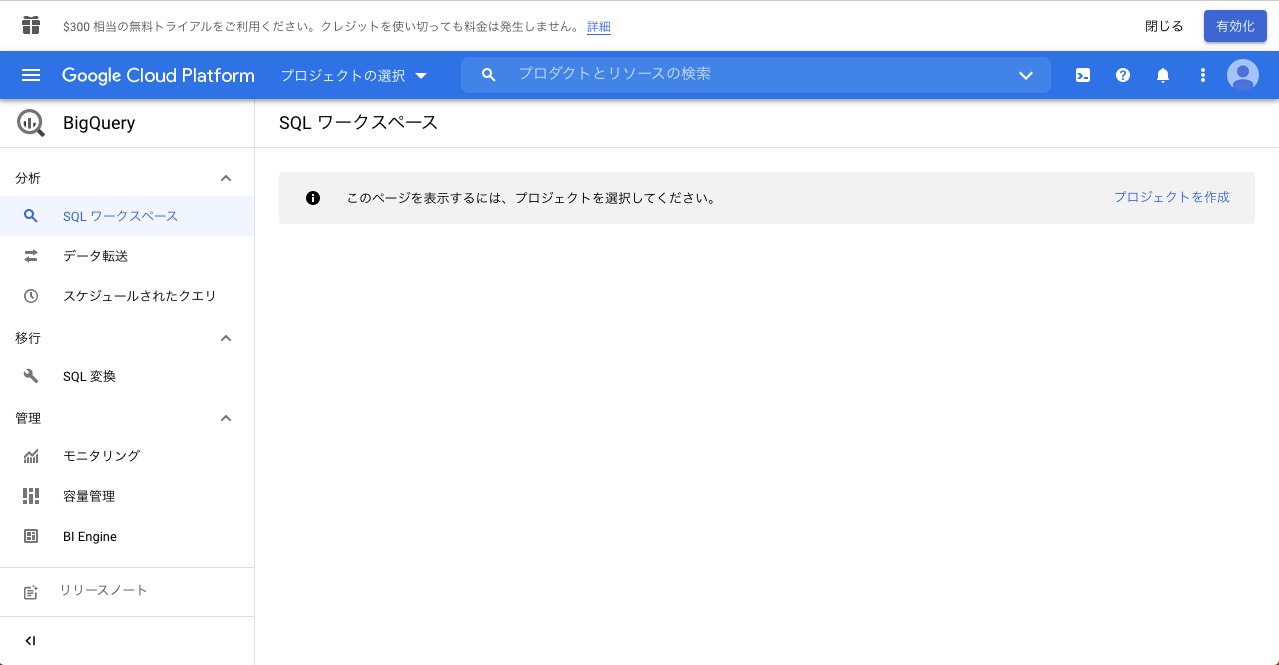
画面上の「プロジェクトを作成」リンクをクリックします。
その後、画面のようなプロジェクト作成ページが表示されるので、プロジェクト名を記入します。
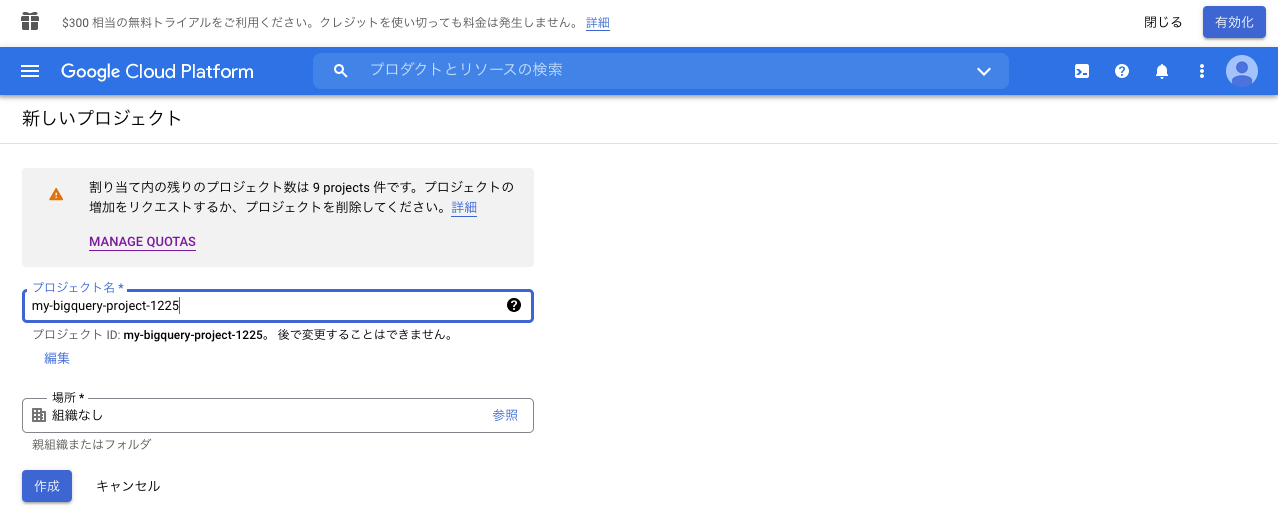
[作成]ボタンを押下します。
BigQueryのSQLワークスペース画面を開く
BigQueryページから新規プロジェクトを作成した場合は、自動的にSQLワークスペース画面に飛びます。
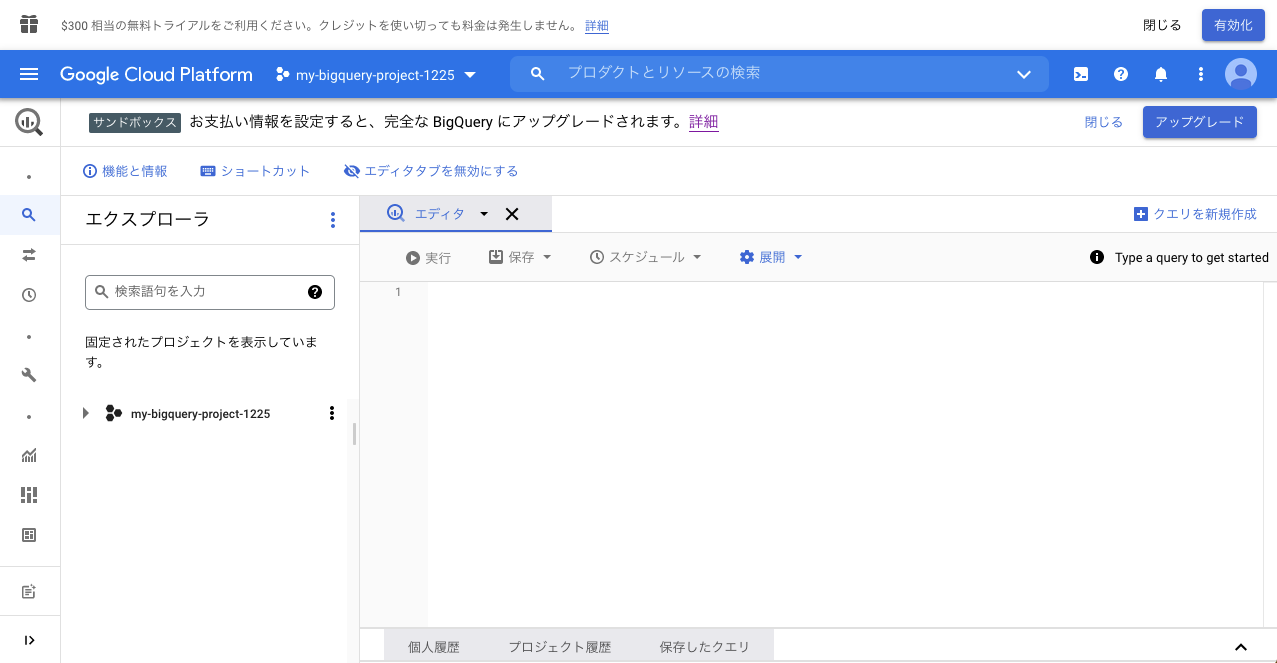
画面上部が、「サンドボックス」となっていることを確認します。
一般公開データセットを使えるようにする
BigQueryには最初から利用可能な公開データが豊富に用意されています。
しかもデータの保存費用は無料でクエリへの課金のみになります。
BigQueryではクエリ料金は処理されるデータに基づいて課金されますが(オンデマンド料金の場合)、毎月1TBは無料です。
なるべくデータセットの容量が小さいものを選んで無料枠の中で試行錯誤できるようにしようと思います。
一般公開データセットの料金について
Google では、これらのデータセットの保存費用を負担しており、プロジェクトを介してデータへの公開アクセスを提供しています。データで実行したクエリにのみ料金が発生します。
毎月 1 TB まで無料です。出典: https://cloud.google.com/bigquery/public-data
クエリ料金について
オンデマンド料金. この料金モデルでは、各クエリによって処理されたバイト数に基づいて課金されます。
処理されるクエリデータは毎月 1 TB まで無料です。出典: https://cloud.google.com/bigquery/pricing#analysis_pricing_models
下記にアクセスすれば一般公開データセット(bigquery-public-data)の情報をワークスペースで確認することができます。
※ プロジェクト選択が外れている場合は画面上部から作成したプロジェクトを選択し直してください。

詳しくは公式ドキュメントをご確認ください
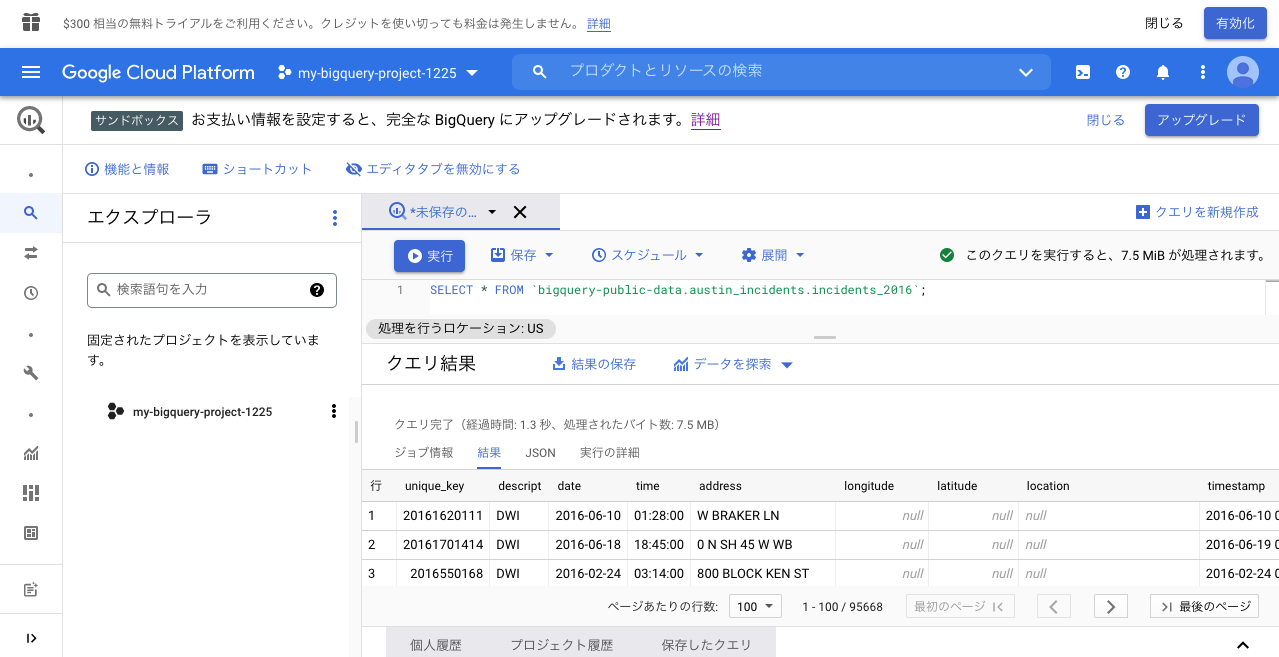
一般公開データセット内のテーブルに対してSELECT文を発行してみる。
今回選んだのは、 austin_incidentsデータセットのincidents_2016テーブルです。
なんとわずか7.46MBなので試行錯誤にぴったりです。
austinはアメリカのテキサス州の地名のようです。
incidentsは事件という意味なので、2016年にオースティンで発生した事件のデータセットのようです。
| 表のサイズ | 行数 |
|---|---|
| 7.46 MB | 95,668 |
SELECT * FROM `bigquery-public-data.austin_incidents.incidents_2016`;画像のようにデータが返ってきたら成功です。
もしエラーや失敗などになったらSQLがきちんとコピーできているか確認したり、BigQuery APIが有効化されているか確認してみてください。